基于Prometheus的jvm监控指标详解
Posted Young丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Prometheus的jvm监控指标详解相关的知识,希望对你有一定的参考价值。
使用Prometheus 监控Springboot应用参考 Prometheus Operator实战—— Prometheus、Alertmanager、Grafana 监控Springboot服务
下面来看看jvm的监控指标
# HELP jvm_gc_collection_seconds Time spent in a given JVM garbage collector in seconds.
# TYPE jvm_gc_collection_seconds summary
#这是一个Summary指标,与Histogram类似,可以对指标数据进行采样
并发收集器 CMS(Concurrent Mark-Sweep)
以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器
对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。
CMS是用于对tenured generation的回收,也就是年老代的回收,目标是尽量减少应用的暂停时间,减少full gc发生的几率,
利用和应用程序线程并发的垃圾回收线程来标记清除年老代。
在启动JVM参数加上-XX:+UseConcMarkSweepGC ,这个参数表示对于老年代的回收采用CMS。CMS采用的基础算法是:标记—清除。
CMS不对堆空间整理压缩节约了垃圾回收的停顿时间,但也带来的堆空间的浪费。为了解决堆空间浪费问题,
CMS回收器不再采用简单的指针指向一块可用堆空 间来为下次对象分配使用。
而是把一些未分配的空间汇总成一个列表,当JVM分配对象空间的时候,会搜索这个列表找到足够大的空间来hold住这个对象。
CMS的另一个缺点是它需要更大的堆空间。因为CMS标记阶段应用程序的线程还是在执行的,那么就会有堆空间继续分配的情况,
为了保证在CMS回 收完堆之前还有空间分配给正在运行的应用程序,必须预留一部分空间。
在回收完成之前,堆没有足够空间分配!默认当老年代使用68%的时候,CMS就开始行动了。 – XX:CMSInitiatingOccupancyFraction =n 来设置这个阀值。
总得来说,CMS回收器减少了回收的停顿时间,但是降低了堆空间的利用率。
如果你的应用程序对停顿比较敏感,并且在应用程序运行的时候可以提供更大的内存和更多的CPU(也就是硬件牛逼),那么使用CMS来收集会给你带来好处。
还有,如果在JVM中,有相对较多存活时间较长的对象(老年代比较大)会更适合使用CMS。
ParNew垃圾收集器
Par是Parallel的缩写,多线程的意思,
但是这里的多线程仅仅指垃圾收集多线程并行,并不是垃圾收集和程序并行运行.ParNew也需要暂停一切工作,然后多线程并行垃圾收集.
参数
“-XX:+UseConcMarkSweepGC”:指定使用CMS后,会默认使用ParNew作为新生代收集器;
“-XX:+UseParNewGC”:强制指定使用ParNew;
“-XX:ParallelGCThreads”:指定垃圾收集的线程数量,ParNew默认开启的收集线程尽量与CPU的数量相当;
# HELP jvm_gc_collection_seconds Time spent in a given JVM garbage collector in seconds.
# TYPE jvm_gc_collection_seconds summary
jvm_gc_collection_seconds_countgc="ParNew", 87.0 ==>YGC
jvm_gc_collection_seconds_sumgc="ParNew", 15.487 ==>YGCT
jvm_gc_collection_seconds_countgc="ConcurrentMarkSweep", 0.0 ==>FGC
jvm_gc_collection_seconds_sumgc="ConcurrentMarkSweep", 0.0 ==>FGCT
# HELP jvm_memory_bytes_used Used bytes of a given JVM memory area.
# TYPE jvm_memory_bytes_used gauge
#jvm已用内存区域
jvm_memory_bytes_usedarea="heap", 2.334615096E9 ==>堆内存使用
jvm_memory_bytes_usedarea="nonheap", 1.8031396E8 ==>非堆内存使用
备注:
nonheap = "Code Cache" + "Metaspace" + "Compressed Class Space"
heap = "Par Eden Space" + "Par Survivor Space" + "CMS Old Gen"
结论:init约等于xms的值,max约等于xmx的值。
used是已经被使用的内存大小,committed是当前可使用的内存大小(包括已使用的),### committed >= used。
committed不足时jvm向系统申请,若超过max则发生OutOfMemoryError错误。
# HELP jvm_memory_bytes_committed Committed (bytes) of a given JVM memory area.
# TYPE jvm_memory_bytes_committed gauge
jvm_memory_bytes_committedarea="heap", 8.267825152E9
jvm_memory_bytes_committedarea="nonheap", 1.85270272E8
# HELP jvm_memory_bytes_max Max (bytes) of a given JVM memory area.
# TYPE jvm_memory_bytes_max gauge
#jvm内存区域的最大字节数
jvm_memory_bytes_maxarea="heap", 8.267825152E9
jvm_memory_bytes_maxarea="nonheap", 1.59383552E9
# HELP jvm_memory_bytes_init Initial bytes of a given JVM memory area.
# TYPE jvm_memory_bytes_init gauge
#jvm内存区域的初始化字节数
jvm_memory_bytes_initarea="heap", 8.589934592E9
jvm_memory_bytes_initarea="nonheap", 2555904.0
# HELP jvm_memory_pool_bytes_used Used bytes of a given JVM memory pool.
# TYPE jvm_memory_pool_bytes_used gauge
#jvm内存池使用情况
jvm_memory_pool_bytes_usedpool="Code Cache", 7.2995456E7
jvm_memory_pool_bytes_usedpool="Metaspace", 9.6191616E7
jvm_memory_pool_bytes_usedpool="Compressed Class Space", 1.1126888E7
jvm_memory_pool_bytes_usedpool="Par Eden Space", 2.184666584E9
jvm_memory_pool_bytes_usedpool="Par Survivor Space", 3342224.0
jvm_memory_pool_bytes_usedpool="CMS Old Gen", 1.46606288E8
# HELP jvm_memory_pool_bytes_committed Committed bytes of a given JVM memory pool.
# TYPE jvm_memory_pool_bytes_committed gauge
jvm_memory_pool_bytes_committedpool="Code Cache", 7.3596928E7
jvm_memory_pool_bytes_committedpool="Metaspace", 9.9876864E7
jvm_memory_pool_bytes_committedpool="Compressed Class Space", 1.179648E7
jvm_memory_pool_bytes_committedpool="Par Eden Space", 2.577006592E9
jvm_memory_pool_bytes_committedpool="Par Survivor Space", 3.2210944E8
jvm_memory_pool_bytes_committedpool="CMS Old Gen", 5.36870912E9
# HELP jvm_memory_pool_bytes_max Max bytes of a given JVM memory pool.
# TYPE jvm_memory_pool_bytes_max gauge
#jvm内存池最大数
jvm_memory_pool_bytes_maxpool="Code Cache", 2.5165824E8
jvm_memory_pool_bytes_maxpool="Metaspace", 2.68435456E8
jvm_memory_pool_bytes_maxpool="Compressed Class Space", 1.073741824E9
jvm_memory_pool_bytes_maxpool="Par Eden Space", 2.577006592E9
jvm_memory_pool_bytes_maxpool="Par Survivor Space", 3.2210944E8
jvm_memory_pool_bytes_maxpool="CMS Old Gen", 5.36870912E9
# HELP jvm_memory_pool_bytes_init Initial bytes of a given JVM memory pool.
# TYPE jvm_memory_pool_bytes_init gauge
#jvm内存池初始化数
jvm_memory_pool_bytes_initpool="Code Cache", 2555904.0
jvm_memory_pool_bytes_initpool="Metaspace", 0.0
jvm_memory_pool_bytes_initpool="Compressed Class Space", 0.0
jvm_memory_pool_bytes_initpool="Par Eden Space", 2.577006592E9
jvm_memory_pool_bytes_initpool="Par Survivor Space", 3.2210944E8
jvm_memory_pool_bytes_initpool="CMS Old Gen", 5.36870912E9
# HELP jmx_config_reload_success_total Number of times configuration have successfully been reloaded.
# TYPE jmx_config_reload_success_total counter
jmx_config_reload_success_total 0.0
# HELP jvm_classes_loaded The number of classes that are currently loaded in the JVM
# TYPE jvm_classes_loaded gauge
#当前jvm已加载类数量
jvm_classes_loaded 16377.0
# HELP jvm_classes_loaded_total The total number of classes that have been loaded since the JVM has started execution
# TYPE jvm_classes_loaded_total counter
#从jvm运行开始加载的类的数量,这是一个Counter指标,递增
jvm_classes_loaded_total 16377.0
# HELP jvm_classes_unloaded_total The total number of classes that have been unloaded since the JVM has started execution
# TYPE jvm_classes_unloaded_total counter
#jvm运行后卸载的类数量,这是一个Counter指标。生产环境一直是0
jvm_classes_unloaded_total 0.0
# HELP jvm_info JVM version info
# TYPE jvm_info gauge
jvm_infoversion="1.8.0_151-b12",vendor="Oracle Corporation",runtime="Java(TM) SE Runtime Environment", 1.0
# HELP os_free_physical_memory_bytes FreePhysicalMemorySize (java.lang<type=OperatingSystem><>FreePhysicalMemorySize)
# TYPE os_free_physical_memory_bytes gauge
os_free_physical_memory_bytes 1.9491221504E10
# HELP os_committed_virtual_memory_bytes CommittedVirtualMemorySize (java.lang<type=OperatingSystem><>CommittedVirtualMemorySize)
# TYPE os_committed_virtual_memory_bytes gauge
os_committed_virtual_memory_bytes 3.4423967744E10
# HELP os_total_swap_space_bytes TotalSwapSpaceSize (java.lang<type=OperatingSystem><>TotalSwapSpaceSize)
# TYPE os_total_swap_space_bytes gauge
os_total_swap_space_bytes 0.0
# HELP os_max_file_descriptor_count MaxFileDescriptorCount (java.lang<type=OperatingSystem><>MaxFileDescriptorCount)
# TYPE os_max_file_descriptor_count gauge
os_max_file_descriptor_count 1048576.0
# HELP os_system_load_average SystemLoadAverage (java.lang<type=OperatingSystem><>SystemLoadAverage)
# TYPE os_system_load_average gauge
os_system_load_average 3.84
# HELP os_total_physical_memory_bytes TotalPhysicalMemorySize (java.lang<type=OperatingSystem><>TotalPhysicalMemorySize)
# TYPE os_total_physical_memory_bytes gauge
os_total_physical_memory_bytes 2.02692759552E11
# HELP os_system_cpu_load SystemCpuLoad (java.lang<type=OperatingSystem><>SystemCpuLoad)
# TYPE os_system_cpu_load gauge
os_system_cpu_load 0.04950495049504951
# HELP os_free_swap_space_bytes FreeSwapSpaceSize (java.lang<type=OperatingSystem><>FreeSwapSpaceSize)
# TYPE os_free_swap_space_bytes gauge
os_free_swap_space_bytes 0.0
# HELP os_available_processors AvailableProcessors (java.lang<type=OperatingSystem><>AvailableProcessors)
# TYPE os_available_processors gauge
os_available_processors 48.0
# HELP os_process_cpu_load ProcessCpuLoad (java.lang<type=OperatingSystem><>ProcessCpuLoad)
# TYPE os_process_cpu_load gauge
os_process_cpu_load 0.0
# HELP os_open_file_descriptor_count OpenFileDescriptorCount (java.lang<type=OperatingSystem><>OpenFileDescriptorCount)
# TYPE os_open_file_descriptor_count gauge
os_open_file_descriptor_count 163.0
# HELP jmx_scrape_duration_seconds Time this JMX scrape took, in seconds.
# TYPE jmx_scrape_duration_seconds gauge
jmx_scrape_duration_seconds 0.00121965
# HELP jmx_scrape_error Non-zero if this scrape failed.
# TYPE jmx_scrape_error gauge
jmx_scrape_error 0.0
# HELP jmx_config_reload_failure_total Number of times configuration have failed to be reloaded.
# TYPE jmx_config_reload_failure_total counter
jmx_config_reload_failure_total 0.0
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
#用户和系统的总cpu使用时间
process_cpu_seconds_total 2293.82
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.618365917041E9
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 163.0
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 1048576.0
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 3.4423963648E10
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 3.942313984E9
# HELP jvm_buffer_pool_used_bytes Used bytes of a given JVM buffer pool.
# TYPE jvm_buffer_pool_used_bytes gauge
#jvm缓冲区使用情况,包括Code Cache(编译后的代码缓存,
不同版本的jvm默认大小不同)、PS Old Gen(老年代)、PS Eden Space(伊甸园)、PS Survivor Space(幸存者)、PS Perm Gen(永久代)
jvm_buffer_pool_used_bytespool="direct", 1729229.0
jvm_buffer_pool_used_bytespool="mapped", 0.0
# HELP jvm_buffer_pool_capacity_bytes Bytes capacity of a given JVM buffer pool.
# TYPE jvm_buffer_pool_capacity_bytes gauge
#给定jvm的估算缓冲区大小
jvm_buffer_pool_capacity_bytespool="direct", 1729229.0
jvm_buffer_pool_capacity_bytespool="mapped", 0.0
# HELP jvm_buffer_pool_used_buffers Used buffers of a given JVM buffer pool.
# TYPE jvm_buffer_pool_used_buffers gauge
#给定jvm的已使用缓冲区大小
jvm_buffer_pool_used_bufferspool="direct", 243.0
jvm_buffer_pool_used_bufferspool="mapped", 0.0
# HELP jvm_threads_current Current thread count of a JVM
# TYPE jvm_threads_current gauge
#jvm当前线程数
jvm_threads_current 284.0
# HELP jvm_threads_daemon Daemon thread count of a JVM
# TYPE jvm_threads_daemon gauge
#jvm后台线程数
jvm_threads_daemon 241.0
# HELP jvm_threads_peak Peak thread count of a JVM
# TYPE jvm_threads_peak gauge
#jvm线程峰值
jvm_threads_peak 286.0
# HELP jvm_threads_started_total Started thread count of a JVM
# TYPE jvm_threads_started_total counter
#jvm总启动线程数量,Counter指标
jvm_threads_started_total 1260.0
# HELP jvm_threads_deadlocked Cycles of JVM-threads that are in deadlock waiting to acquire object monitors or ownable synchronizers
# TYPE jvm_threads_deadlocked gauge
#死锁线程数量
jvm_threads_deadlocked 0.0
# HELP jvm_threads_deadlocked_monitor Cycles of JVM-threads that are in deadlock waiting to acquire object monitors
# TYPE jvm_threads_deadlocked_monitor gauge
jvm_threads_deadlocked_monitor 0.0
基于 prometheus 的微服务指标监控
在微服务架构下随着服务越来越多,定位问题也变得越来越复杂,因此监控服务的运行状态以及针对异常状态及时的发出告警也成为微服务治理不可或缺的一环。服务的监控主要有日志监控、调用链路监控、指标监控等几种类型方式,其中指标监控在整个微服务监控中比重最高,也是实际生产中排查问题最重要的依赖
指标监控又可以细分为多种类型:
基础监控: 是针运行服务的基础设施的监控,比如容器、虚拟机、物理机等,监控的指标主要有内存的使用率,cpu 的使用率等资源的监控,通过对资源的监控和告警能够及时发现资源瓶颈从而进行扩容操作避免影响服务,同时针对资源的异常变化也能辅助定位服务问题,比如内存泄漏会导致内存异常
运行时监控: 运行时监控主要有 GC 的监控包括 GC 次数、GC 耗时,线程数量的监控等等
通用监控: 通用监控主要包括对流量和耗时的监控,通过流量的变化趋势可以清晰的了解到服务的流量高峰以及流量的增长情况,流量同时也是资源分配的重要参考指标。耗时是服务性能的直观体现,耗时比较大的服务我们往往需要进行优化,平均耗时往往参考价值不大,因为我们采取中位数,包括 90、95、99 值等
错误监控: 错误监控是服务健康状态的直观体现,主要包括请求返回的错误码,如 HTTP 的错误码 5xx、4xx,熔断、限流等等,通过对服务错误率的观察可以了解到服务当前的健康状态
prometheus是一个开源的系统监控和告警工具,支持强大的查询语言 PromQL 允许用户实时选择和汇聚时间序列数据,时间序列数据是服务端通过 HTTP 协议主动拉取获得,也可以通过中间网关来推送时间序列数据,可以通过静态配置文件或服务发现来获取监控目标,同时可以设置告警规则,prometheus 周期性通过 PromQL 进行计算,当满足条件就会触发告警
1 Prometheus 的架构
Prometheus 的整体架构以及生态系统组件如下图所示:
Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化
下面我们通过一个简单的实例来演示如何对微服务进行指标监控,以及相关组件的使用
2 go-zero 基于 Prometheus 的服务指标监控
go-zero 框架中集成了基于 prometheus 的服务指标监控,下面我们通过 go-zero 官方的示例shorturl来演示是如何对服务指标进行收集监控的:
第一步需要先安装 Prometheus,安装步骤请参考官方文档
Prometheus:
Host: 127.0.0.1
Port: 9091
Path: /metrics
编辑 prometheus 的配置文件 prometheus.yml,添加如下配置,并创建 targets.json
- job_name: 'file_ds'
file_sd_configs:
- files:
- targets.json[{
"targets": ["127.0.0.1:9091"],
"labels": {
"job": "shorturl-api",
"app": "shorturl-api",
"env": "test",
"instance": "127.0.0.1:8888"
}
}]启动 prometheus 服务,默认侦听在 9090 端口
prometheus --config.file=prometheus.yml在浏览器输入http://127.0.0.1:9090/Status,然后点击 -> Targets 即可看到状态为 Up 的 Job,并且 Lables 栏可以看到我们配置的默认的标签
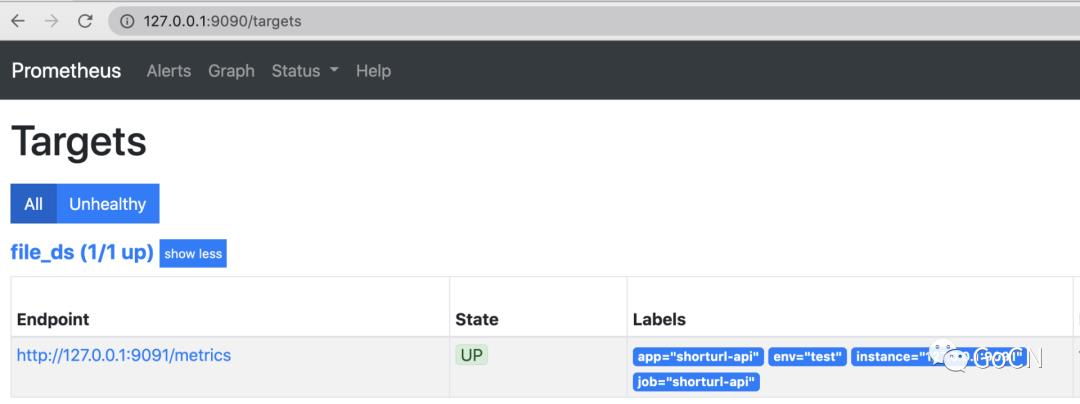
通过以上几个步骤我们完成了 prometheus 对 shorturl 服务的指标监控收集的配置工作,为了演示简单我们进行了手动的配置,在实际的生产环境中一般采用定时更新配置文件或者服务发现的方式来配置监控目标,篇幅有限这里不展开讲解,感兴趣的同学请自行查看相关文档
3 go-zero 监控的指标类型
go-zero 中目前在 http 的中间件和 rpc 的拦截器中添加了对请求指标的监控。
主要从请求耗时和请求错误两个维度,请求耗时采用了 Histogram 指标类型定义了多个 Buckets 方便进行分位统计,请求错误采用了 Counter 类型,并在 http metric 中添加了 path 标签 rpc metric 中添加了 method 标签以便进行细分监控。
接下来演示如何查看监控指标:
首先在命令行多次执行如下命令
curl -i "http://localhost:8888/shorten?url=http://www.xiaoheiban.cn"
打开 Prometheus 切换到 Graph 界面,在输入框中输入{path="/shorten"}指令,即可查看监控指标,如下图
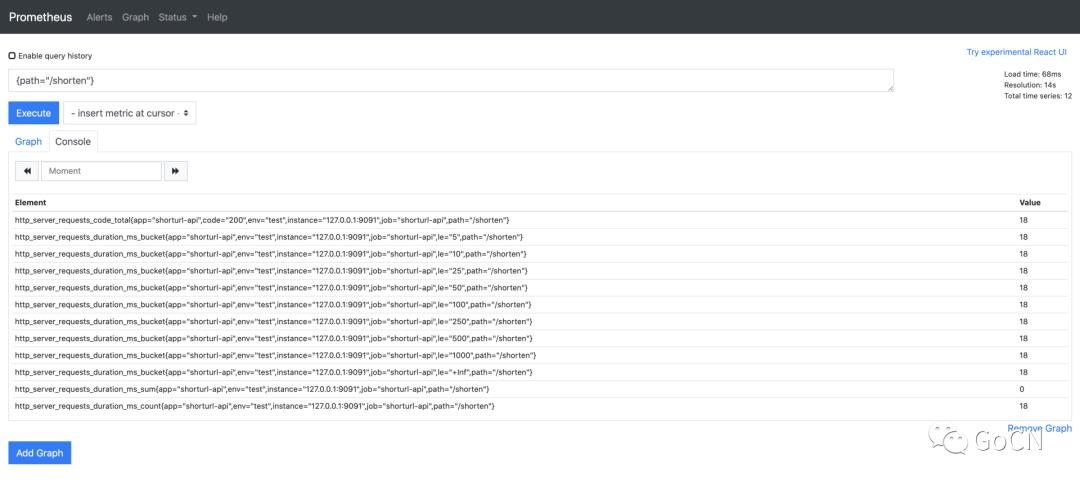
我们通过 PromQL 语法查询过滤 path 为/shorten 的指标,结果中显示了指标名以及指标数值,其中 http_server_requests_code_total 指标中 code 值为 http 的状态码,200 表明请求成功,http_server_requests_duration_ms_bucket 中对不同 bucket 结果分别进行了统计,还可以看到所有的指标中都添加了我们配置的默认指标
Console 界面主要展示了查询的指标结果,Graph 界面为我们提供了简单的图形化的展示界面,在实际的生产环境中我们一般使用 Grafana 做图形化的展示
4 grafana 可视化界面
grafana是一款可视化工具,功能强大,支持多种数据来源 Prometheus、Elasticsearch、Graphite 等,安装比较简单请参考官方文档,grafana 默认端口 3000,安装好后再浏览器输入http://localhost:3000/admin,默认账号和密码都为
下面演示如何基于以上指标进行可视化界面的绘制:
点击左侧边栏添加 dashboard,然后添加 Variables 方便针对不同的标签进行过滤筛选比如添加 app 变量用来过滤不同的服务
进入 dashboard 点击右上角 Add panel 添加面板,以 path 维度统计接口的 qps

最终的效果如下所示,可以通过服务名称过滤不同的服务,面板展示了 path 为/shorten 的 qps 变化趋势
5 总结
以上演示了 go-zero 中基于 prometheus+grafana 服务指标监控的简单流程,生产环境中可以根据实际的场景做不同维度的监控分析。现在 go-zero 的监控指标主要还是针对 http 和 rpc,这对于服务的整体监控显然还是不足的,比如容器资源的监控,依赖的 mysql、redis 等资源的监控,以及自定义的指标监控等等,go-zero 在这方面后续还会持续优化
监控不是万能的,虽然监控能帮助我们及时的发现问题,但很多场景下告警一旦产生可能就已经对用户产生了影响,所以我们应该提前预测问题发生的可能,采取的手段主要有对服务的压测,对使用资源的评估,以及定期的进行服务巡检等等,希望本文能给大家带来帮助
项目地址
https://github.com/tal-tech/go-zero
微信交流群
2020 GopherChinaCon 隆重开启!
时间:2020年11月20-22日
地点:上海由由喜来登酒店
报名方式:点击“阅读原文”,早鸟票火热开启中
以上是关于基于Prometheus的jvm监控指标详解的主要内容,如果未能解决你的问题,请参考以下文章