Lucene:虽不是全文检索引擎,却强大依旧
Posted 研发云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene:虽不是全文检索引擎,却强大依旧相关的知识,希望对你有一定的参考价值。
在进行数据处理时
我们一般会遇到两种数据形式
一种是具有固定格式或有限长度的数据
叫做结构化数据(例:数据库、元数据)
另一种是格式或长度不固定的数据
叫做非结构化数据(例:邮件,word 文档)
而后者又被称为全文数据

当需要对结构化数据进行搜索处理时
我们通常会使用 SQL 语句等手段
但对非结构化数据的搜索处理时
往往还需要先建立索引,再对索引进行搜索
该过程被称之为全文检索(Full-text Search)
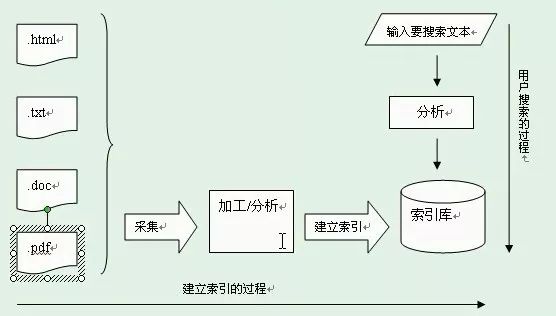
全文检索大体分两个过程
包括索引创建(Indexing)和搜索索引(Search)
索引创建是提取“数据的相关信息”并创建索引的过程
索引存储在索引库(index)中
搜索索引就是得到用户的查询请求
然后搜索“之前所创建的索引”并返回结果的过程
那么,有什么工具能让我们实现这些功能呢?
答案就是 Lucene

Lucene 是著名的 Apache Jakarta 大家庭中的一员,是一款高性能的、可扩展的信息检索(IR)工具库,也是一个开放源代码的全文检索引擎工具包。
Lucene 的检索算法属于索引检索,它可以对需要检索的文件、字符流进行索引创建,也能在检索的时候对索引进行快速的检索,从而得到检索位置(这个位置记录了检索词出现的文件路径或者某个关键词)。
(1)索引文件格式独立于应用平台:Lucene 定义了一套以 8 位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在倒排索引的基础上,实现了分块索引:Lucene 能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构:这使得对于 Lucene 扩展的学习难度降低,方便扩充新功能。
(4)独立于语言和文件格式的文本分析接口:Lucene 的索引器通过接受 Token 流完成索引文件的创立,用户只需要实现文本分析的接口,即可扩展新的语言和文件格式。
(5)默认实现了一套强大的查询引擎功能:Lucene 的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等,用户无需自己编写代码,即可使系统可获得强大的查询能力。
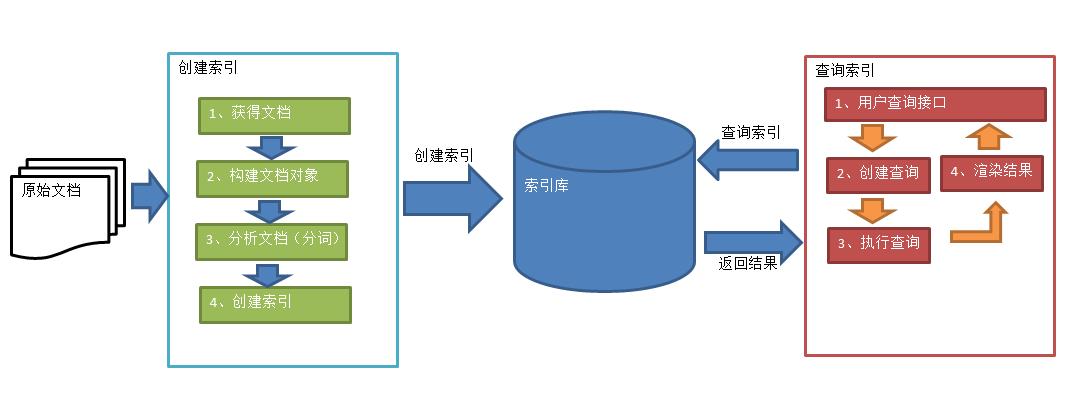
Lucene 拥有完整的索引引擎和查询引擎
以及部分文本分析引擎
不过它不提供制作搜索界面的功能
需要用户根据需求自己开发搜索界面
因此 Lucene 不算是一个完整的全文检索引擎
而只是一个全文检索引擎的架构
但它提供了一个简单却强大的应用程式接口
能够让用户实现全文检索
并以其开放源代码的特性和优异的索引结构
获得了越来越多的应用

用户完全可以以 Lucene 为基础
建立起属于自己的完整全文检索引擎
实际上,基于 Lucene 建立的搜索引擎确实不少
比较著名的有Apache Solr、Elastic Search、
Index Tank、Katta、Bobo Search、
Compass、Summa和Constellio
这些优秀的搜索引擎也充分展现了Lucene的实力

长|按|二|维|码|关|注
获取更多产品介绍及业界动态
 研发云微信公众号
研发云微信公众号
研·发·云
以上是关于Lucene:虽不是全文检索引擎,却强大依旧的主要内容,如果未能解决你的问题,请参考以下文章