使用Lucene.Net做一个简单的搜索引擎-全文索引
Posted ZKEASOFT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Lucene.Net做一个简单的搜索引擎-全文索引相关的知识,希望对你有一定的参考价值。
Lucene.Net
Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。
Lucene.net是Apache软件基金会赞助的开源项目,基于Apache License协议。
Lucene.net并不是一个爬行搜索引擎,也不会自动地索引内容。我们得先将要索引的文档中的文本抽取出来,然后再将其加到Lucene.net索引中。标准的步骤是先初始化一个Analyzer、打开一个IndexWriter、然后再将文档一个接一个地加进去。一旦完成这些步骤,索引就可以在关闭前得到优化,同时所做的改变也会生效。这个过程可能比开发者习惯的方式更加手工化一些,但却在数据的索引上给予你更多的灵活性,而且其效率也很高。
官网:http://lucenenet.apache.org/
GitHub: https://github.com/apache/lucenenet
添加nuget包引用
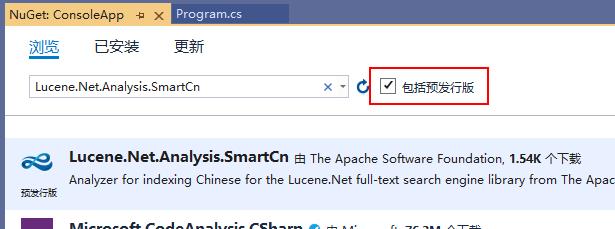
首先我们要在项目中引用Lucene.Net的相关引用,不同的语言要使用的分析器(Analyzer)是不一样的,这里我们使用Lucene.Net.Analysis.SmartCn来做示例,用于分析中文。当前Lucene.Net.Analysis.SmartCn包还未发布正式版,所以搜索时要勾选“包括预发行版本”:
IndexWriter
IndexWriter用于将文档索引起来,它会使用对应的分析器(Analyzer)来将文档中的文字进行拆分索引并且将索引存到Index_Data目录:
static IndexWriter GetIndexWriter() { var dir = FSDirectory.Open("Index_Data"); Analyzer analyzer = new SmartChineseAnalyzer(LuceneVersion.LUCENE_48); var indexConfig = new IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer); IndexWriter writer = new IndexWriter(dir, indexConfig); return writer; }
有了IndexWriter,我们就可以将文档索引进来了:
static void WriteDocument(string url, string title, string keywords, string description) { using (var writer = GetIndexWriter()) { writer.DeleteDocuments(new Term("url", url)); Document doc = new Document(); doc.Add(new StringField("url", url, Field.Store.YES)); TextField titleField = new TextField("title", title, Field.Store.YES); titleField.Boost = 3F; TextField keywordField = new TextField("keyword", keywords, Field.Store.YES); keywordField.Boost = 2F; TextField descriptionField = new TextField("description", description, Field.Store.YES); descriptionField.Boost = 1F; doc.Add(titleField); doc.Add(keywordField); doc.Add(descriptionField); writer.AddDocument(doc); writer.Flush(triggerMerge: true, applyAllDeletes: true); writer.Commit(); } }
对代码做一些简单的说明,在实例化一个Document后,需要在Document里面添加一些字段:
- StringField:将该字段索引,但不会做语意拆分
- TextField:索引器会对该字段进行拆分后再索引
- Boost:即权重,比如标题(3F)和关键字(2F)都匹配的话,以标题为优先排在前面
现在我们已经可以将文档索引起来了,我们将索引一个页面:
WriteDocument("https://www.zkea.net/index", "纸壳CMS开源免费可视化设计内容管理系统", "纸壳CMS,ZKEACMS,可视化设计,可视化CMS", "纸壳CMS(ZKEACMS)是开源的建站系统,您可以直接使用它来做为您的企业网站,门户网站或者个人网站,博客");
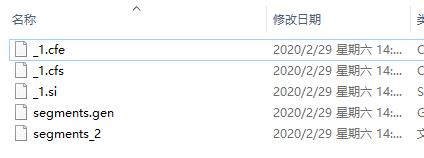
Index_Data目录将会生成一些索引文件:
有了索引,接下来要做的就是搜索了。
IndexSearcher
因为用户在搜索的时候并不单单只输入关键字,很可能输入的是词、句,所以在搜索之前,我们还要对搜索语句进行分析,拆解出里面的关键词后再进行搜索。
static List<string> GetKeyWords(string q) { List<string> keyworkds = new List<string>(); Analyzer analyzer = new SmartChineseAnalyzer(LuceneVersion.LUCENE_48); using (var ts = analyzer.GetTokenStream(null, q)) { ts.Reset(); var ct = ts.GetAttribute<Lucene.Net.Analysis.TokenAttributes.ICharTermAttribute>(); while (ts.IncrementToken()) { StringBuilder keyword = new StringBuilder(); for (int i = 0; i < ct.Length; i++) { keyword.Append(ct.Buffer[i]); } string item = keyword.ToString(); if (!keyworkds.Contains(item)) { keyworkds.Add(item); } } } return keyworkds; }
拆分好用户输入的词句后,接下来使用IndexSearcher并使用组合条件进行搜索:
static void Search(string q) { IndexReader reader = DirectoryReader.Open(FSDirectory.Open("Index_Data")); var searcher = new IndexSearcher(reader); var keyWordQuery = new BooleanQuery(); foreach (var item in GetKeyWords(q)) { keyWordQuery.Add(new TermQuery(new Term("title", item)), Occur.SHOULD); keyWordQuery.Add(new TermQuery(new Term("keyword", item)), Occur.SHOULD); keyWordQuery.Add(new TermQuery(new Term("description", item)), Occur.SHOULD); } var hits = searcher.Search(keyWordQuery, 200).ScoreDocs; foreach (var hit in hits) { var document = searcher.Doc(hit.Doc); Console.WriteLine("Url:{0}", document.Get("url")); Console.WriteLine("Title:{0}", document.Get("title")); Console.WriteLine("Keyword:{0}", document.Get("keyword")); Console.WriteLine("Description:{0}", document.Get("description")); } }
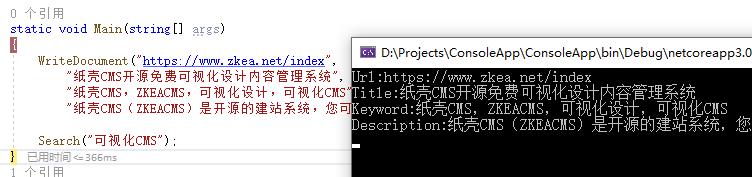
接下来我们来试着搜索一下:
完整代码
这里只是一个简单的示例,有关于更多,可以查看Lucene.Net的官方文档。
using Lucene.Net.Analysis; using Lucene.Net.Analysis.Cn.Smart; using Lucene.Net.Documents; using Lucene.Net.Index; using Lucene.Net.Search; using Lucene.Net.Store; using Lucene.Net.Util; using System; using System.Collections.Generic; using System.Text; namespace ConsoleApp { class Program { static void Main(string[] args) { WriteDocument("https://www.zkea.net/index", "纸壳CMS开源免费可视化设计内容管理系统", "纸壳CMS,ZKEACMS,可视化设计,可视化CMS", "纸壳CMS(ZKEACMS)是开源的建站系统,您可以直接使用它来做为您的企业网站,门户网站或者个人网站,博客"); Search("可视化CMS"); } static void WriteDocument(string url, string title, string keywords, string description) { using (var writer = GetIndexWriter()) { writer.DeleteDocuments(new Term("url", url)); Document doc = new Document(); doc.Add(new StringField("url", url, Field.Store.YES)); TextField titleField = new TextField("title", title, Field.Store.YES); titleField.Boost = 3F; TextField keywordField = new TextField("keyword", keywords, Field.Store.YES); keywordField.Boost = 2F; TextField descriptionField = new TextField("description", description, Field.Store.YES); descriptionField.Boost = 1F; doc.Add(titleField); doc.Add(keywordField); doc.Add(descriptionField); writer.AddDocument(doc); writer.Flush(triggerMerge: true, applyAllDeletes: true); writer.Commit(); } } static IndexWriter GetIndexWriter() { var dir = FSDirectory.Open("Index_Data"); Analyzer analyzer = new SmartChineseAnalyzer(LuceneVersion.LUCENE_48); var indexConfig = new IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer); IndexWriter writer = new IndexWriter(dir, indexConfig); return writer; } static List<string> GetKeyWords(string q) { List<string> keyworkds = new List<string>(); Analyzer analyzer = new SmartChineseAnalyzer(LuceneVersion.LUCENE_48); using (var ts = analyzer.GetTokenStream(null, q)) { ts.Reset(); var ct = ts.GetAttribute<Lucene.Net.Analysis.TokenAttributes.ICharTermAttribute>(); while (ts.IncrementToken()) { StringBuilder keyword = new StringBuilder(); for (int i = 0; i < ct.Length; i++) { keyword.Append(ct.Buffer[i]); } string item = keyword.ToString(); if (!keyworkds.Contains(item)) { keyworkds.Add(item); } } } return keyworkds; } static void Search(string q) { IndexReader reader = DirectoryReader.Open(FSDirectory.Open("Index_Data")); var searcher = new IndexSearcher(reader); var keyWordQuery = new BooleanQuery(); foreach (var item in GetKeyWords(q)) { keyWordQuery.Add(new TermQuery(new Term("title", item)), Occur.SHOULD); keyWordQuery.Add(new TermQuery(new Term("keyword", item)), Occur.SHOULD); keyWordQuery.Add(new TermQuery(new Term("description", item)), Occur.SHOULD); } var hits = searcher.Search(keyWordQuery, 200).ScoreDocs; foreach (var hit in hits) { var document = searcher.Doc(hit.Doc); Console.WriteLine("Url:{0}", document.Get("url")); Console.WriteLine("Title:{0}", document.Get("title")); Console.WriteLine("Keyword:{0}", document.Get("keyword")); Console.WriteLine("Description:{0}", document.Get("description")); } } } }
以上是关于使用Lucene.Net做一个简单的搜索引擎-全文索引的主要内容,如果未能解决你的问题,请参考以下文章