学员优秀博文赏析:双基准快速排序实现
Posted 最课程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学员优秀博文赏析:双基准快速排序实现相关的知识,希望对你有一定的参考价值。
我一般是不会去主动碰算法问题的。上学的时候一个算法复杂度就把我搞烦了,还想让我去搞算法本身?我是这么安慰自己的:反正写CRUD又不需要算法,这辈子都不需要算法的。好吧,其实我是一直不肯承认,不去动算法的原因只有三个字:因为笨!
所以你去看,一般招算法工程师的都是大厂,而且,薪水永远稳居程序员工资的顶端位置。流传在开发界的鄙视链中,算法工程师一直稳居金字塔顶端,俯睨众生。

故,当学员之中出现第一篇涉足算法,还写的有模有样的的博客的时候,我是有点吃惊的。虽然只是基础算法,但这篇博客中除了涉及到了算法本身,还涉及到了源码分析,同时为了保证论证的完整性,文末还给出了reference。
这几乎是一个优秀程序员都会具备的素质,可是我们的这位学员才学习了Java一个月啊~~。直到我看到学员本尊的时候,一切都释然了。你们来感受下他的头像,我可以保证确实是本尊无疑:

隐藏的大侠都应该是如此的。
来,现在我们就来欣赏这位同学的博文,师徒班常同学的《Java中双基准快速排序方法(DualPivotQuicksort.sort())的具体实现》:
===========================================================
在Java语言的Arrays类下提供了一系列排序(sort)方法,帮助使用者对各种不同数据类型的数组进行排序. 在1.7之后的版本中, Arrays.sort()方法在操作过程中实际调用的是DualPivotQuicksort类下的sort方法,DualPivotQuicksort和Arrays一样,都在java.util包下,按字面翻译过来,就是双(Dual)基准(Pivot)快速排序(Quicksort)算法.
双基准快速排序算法于2009年由Vladimir Yaroslavskiy提出,是对经典快速排序(Classic Quicksort)进行优化后的一个版本, Java自1.7开始,均使用此方法作为默认排序算法. 接下来,本文就将对此方法的具体实现过程进行简单的介绍.
在正式进入对DualPivotQuicksort的介绍之前,我们先来对经典快速排序的实现思路进行一下简单的了解:
经典快速排序在操作过程中首先会从数组中选取一个基准(Pivot),这个基准可以是数组中的任意一个元素;
随后,将这个数组所有其他元素和Pivot进行比较,比Pivot小的数放在左侧,大的数放在右侧;
如此,我们就在Pivot的左侧和右侧各得到了一个新的数组;
接下来我们再在这两个新的数组中各自选取新的Pivot,把小的放在左侧,大的放在右侧,循环往复,最终就会得到由小到大顺序排列的数组.
下图(via wiki)便是Quicksort的一个具体实现:
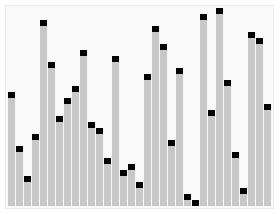
在对Quicksort的基本思路有了一定了解之后,下一步我们就来看Java中DualPivotQuicksort.sort是如何实现的;
本方法在实际工作过程中, 并不是对任何传入的数组都直接进行快速排序, 而是会先对数组进行一系列测试, 然后根据数组的具体情况选择最适合的算法来进行排序,下面我们结合源码来看:
首先, 以一个int数组为例,
当一个数组int[] a被传入DualPivotQuicksort.sort()时,该方法还会要求其他一系列参数:
static void sort(int[] a, int left, int right, int[] work, int workBase, int workLen)
其中,int[] a是需被排序的int数组, left和right是该数组中需要被排序的部分的左右界限. 而后面的work, workBase和workLen三个参数其实并不会参与双基准快速排序, 而是当系统认为本数组更适合使用归并排序(merge sort)的时候, 供归并排序使用.
但是,在实际使用中,我们并不希望为了排序设置这么多的参数,因此:
Arrays.sort()在调用DualPivotQuicksort.sort()之前,对int数组的排序提供了两种参数列表:
public static void sort(int[] a)
直接对int[] a 进行排序,以及:
public static void sort(int[] a, int fromIndex, int toIndex)
对int[] a 中从fromIndex到toIndex(包头不包尾)之间的元素进行排序.
在这里,Arrays.sort()会自动将int[] work, int workBase, int workLen设置为null,0,0 省去了使用者的麻烦.
紧接着,DualPivotQuicksort.sort()会对传入的int数组进行检测, 具体流程如下:
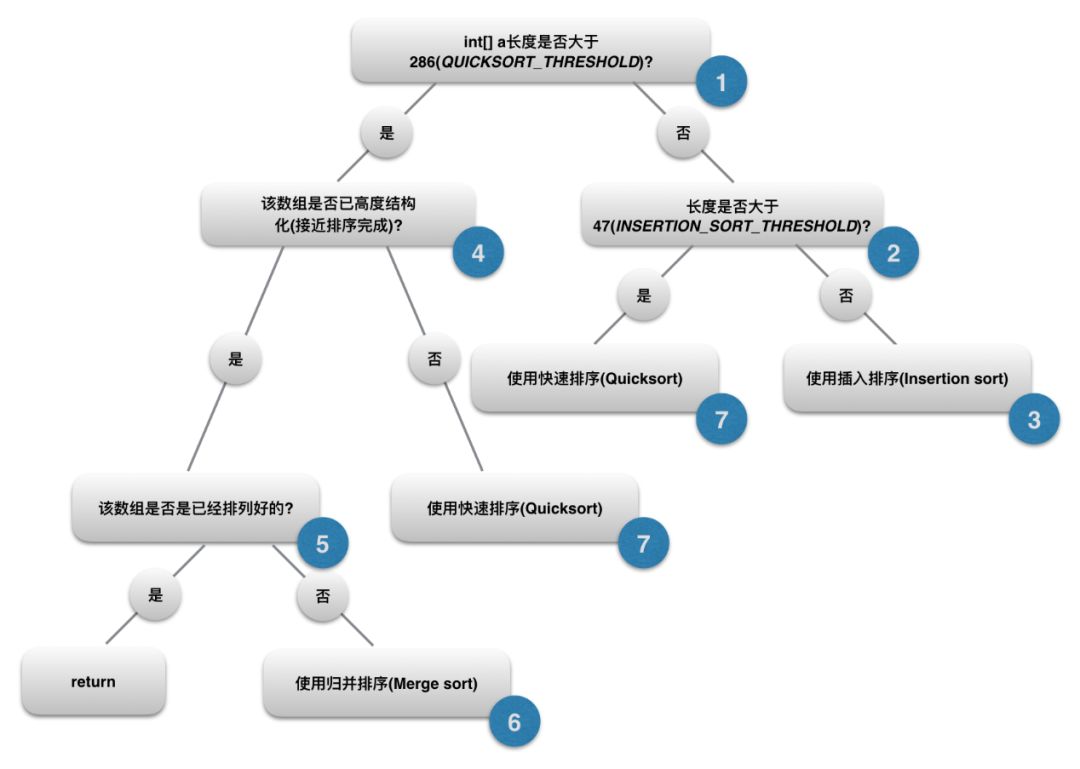
这里先贴上整个方法的完整源码, 然后按上图中的流程逐步分析, 只想看DualPivotQuicksort的话可以直接跳到下面第7点:













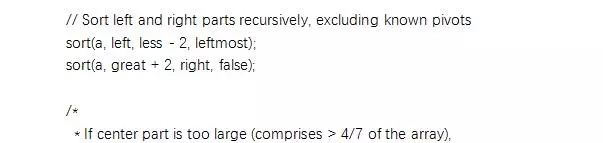







1. 判断数组int[] a的长度是否大于常量QUICKSORT_THRESHOLD, 即286:
286是java设定的一个阈值,当数组长度小于此值时, 系统将不再考虑merge sort, 直接将参数传入本类中的另一个私有sort方法进行排序


2. 继续判断int[] a的长度是否大于常量INSERTION_SORT_THRESHOLD, 即47:
3. 若数组长度小于47, 则使用insertion sort:
数组传入本类私有的sort方法后, 会继续判断数组长度是否大于47, 若小于此值, 则直接使用insertion sort并返回结果, 因为插入算法并非本文重点, 此处不再展开叙述

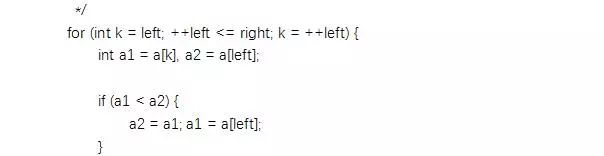

值得注意的是, java在这里提供了两种不同的插入排序算法, 当传入的参数leftmost真假值不同时, 会使用不同的算法.
leftmost代表的是本次传入的数组是否是从最初的int[] a的最左侧left开始的, 因为本方法在整个排序过程中可能会针对数组的不同部分被多次调用, 因此leftmost有可能为false.
Quicksort的情况我们放到最后再谈, 这里先回过来看第一步判断中数组长度大于286的情形, 这种情况下, 系统会
4.继续判断该数组是否已经高度结构化(即已经接近排序完成):
这里的基本思路是这样的:
a. 定义一个常量MAX_RUN_COUNT = 67;
b. 定义一个计数器int count = 0; 定义一个数组int[] run 使之长度为MAX_RUN_COUNT + 1;
c. 令run[0] = left, 然后从传入数组的最左侧left开始遍历, 若数组的前n个元素均为升序/降序排列, 而第n + 1个元素的升/降序发生了改变, 则将第n个元素的索引存入run[1], 同时++count, 此时count的值为1;
d. 从n + 1开始继续遍历, 直至升/降序再次改变, 再将此处的索引存入run[2], ++count, 此时count的值为2, 以此类推...
......
e. 若将整个数组全部遍历完成后, count仍然小于MAX_RUN_COUNT (即整个数组升降序改变的次数低于67次), 证明该数组是高度结构化的, 则使用merge sort进行排序;
若count == MAX_RUN_COUNT时, 还未完成对数组的遍历, 则证明数组并非高度结构化, 则调用前文所述私有sort方法进行quicksort.

5. 判断该数组是否是是已经排列好的:
若该数组是高度结构化的, 在使用merge sort进行排序之前, 会先检验数组是否本身就是排序好的, 思路很简单, 如果在前面的检测中一次就完成了遍历, 就证明该数组是排序好的, 则直接返回结果:

*当然, 在具体实现中还有不少其他要考虑的因素, 有兴趣了解的话可以结合上一部分代码进行阅读.
6. 进行归并排序(merge sort):
此处不再展开叙述, 值得注意的是, 由于归并算法在操作过程中需要使用一块额外的存储空间, 本方法参数列表中要求的work, workBase和workLen三个参数就是在此处使用的:


7. 进行双基准快速排序(dual pivot quicksort):
只有在上述情况都不满足的情况下, 本方法才会使用双基准快速排序算法进行排序,
算法本身的思路并不复杂, 和经典快速排序相差不大, 顾名思义, 比起经典快排, 该算法选取了两个Pivot, 我们姑且称之为P1和P2.
P1和P2都从数组中选出, P1在P2的右侧, 且P1必须小于P2, 如果不是, 则交换P1和P2的值;
接下来令数组中的每一个元素和基准进行比较, 比P1小的放在P1左边, 比P2大的放在P2右边, 介于两者之间的放在中间.
这样, 最终我们会的得到三个数组, 比P1小元素构成的数组, 介于P1和P2之间的元素构成的数组, 以及比P2大的元素构成的数组.
最后, 递归地对这三个数组进行排序, 最终得到排序完成的结果.
思路上虽然, 并不复杂, 但Java为了尽可能的提高效率, 在对这个算法进行实现的过程中增加了非常多的细节, 下面我们就来大致看一下其中的部分内容:











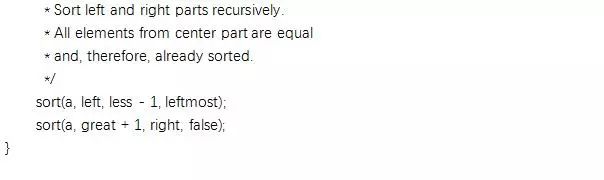
先贴上这部分完整的代码
首先, 也是本方法中最具特色的部分, 就是对Pivot的选取:
在这里, 系统会先通过位运算获取数组长度的1/7的近似值(位运算无法精确表示1/7)
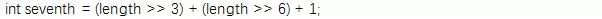
然后获取本数组中间位置的索引e3:
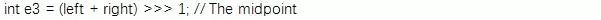
在中间位置的左右1/7, 2/7处各获取两个索引(e1, e2, e4, e5):

将这五个索引对应的值用插入算法进行有小到大的排序后, 再放回五个索引的位置

对索引的值排序
接下来进行判断, 若这五个索引对应的元素值各不相同, 则选取e2的值作为Pivot1, e4的值作为Pivot2(特别注意基准是值而不是元素), 然后进行双基准快排, Java声称这种选法比其他方式更加高效;
但如果这五个值中有相同的存在, 则本轮排序选取e3的值作为Pivot, 进行单基准快排, 同样, Java声称这种选取方式要比随机选取更加高效.
至于具体排序的部分, 其实并没有太多可以叙述的内容, 值得注意的是, 由于在递归的过程中会不断地调用私有的sort方法, 所以在递归中获得的子数组长度小47时, 会改为调用插入排序.
此外, 源码中还有一些可以借鉴的用来提高效率的小窍门, 比如在对元素进行交换位置之前先过滤掉头尾处已经在正确位置的元素等, 有兴趣的话可以再对源码进行仔细阅读.
至此, 关于DualPivotQuicksort.sort()的大致实现过程的介绍也就基本结束了, 最后我们不妨进行一个简单的测试, 看看它是否真的比经典快排更加高效:
首先, 我们先来测试一下经典Quicksort的性能, 对包含一亿个Random.nextInt()随机数的数组进行排序, 重复十次求平均排序运行时间,
具体代码如下, 其中经典快排的代码摘自wiki快速排序条目:


经典快排测试
经过测试, 我们得到结果, 十次排序的运行时间分别为2405 3017 3021 2972 2993 2967 2992 2954 3001 2984(ms),
平均时间则是2930ms
接下来, 再对DualPivotQuicksort.sort()使用同样的方法进行测试, 直接用Arrays.sort()进行排序,代码如下:
双基准快排测试
十次运行时间分别是115 16 31 21 28 118 62 78 78 63(ms).
平均时间则达到了惊人的61ms.
当然, 之所以会产生如此巨大的差距, 一方面是因为双基准快排本身性能更加优秀, 另一方也是因为Java对该方法进行了大量的优化, 而选取测试的经典快排则相当粗糙, 只是这种算法思想的体现, 并不是说两种算法本身性能上存在着这种程度的差距.
Reference:
Quicksort - wiki
https://en.wikipedia.org/wiki/Quicksort
快速排序 - wiki
https://zh.wikipedia.org/zh-cn/%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F
java.util.Arrays
java.util.DualPivotQuicksort
再一次的分割线
===========================================================
1:常同学的原文博客在:http://www.cnblogs.com/chang4/
2:师徒班持续招生中,想成为像刘同学一样的优秀学员,请来这里报名:http://www.zuikc.com
以上是关于学员优秀博文赏析:双基准快速排序实现的主要内容,如果未能解决你的问题,请参考以下文章