详解JMeter正则表达式提取器
Posted 玩转jmeter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解JMeter正则表达式提取器相关的知识,希望对你有一定的参考价值。
每日感悟:
想法决定人生的高度。
一件事能不能做成功,关键不在于有没有能力,而在于有没有要做成功的想法。
JMeter后置处理器中的正则表达式提取器也是最常使用的一个元件,非常简单方便,功能也很强大。
最近我在调脚本时对它又有了更深刻的认识,发现jmeter的每个看似普通的元件都做的非常出色,值得用心研究。在此总结个人经验分享给大家。
应用场景:

应用场景:
在一个线程组中,B请求需要使用A请求返回的数据,也就是常说的关联,将上一个请求的响应结果作为下一个请求的参数,则需要对A请求的响应报文使用后置处理器,其中最方便最常用的就是正则表达式提取器了。
正则表达式提取器:
允许用户从作用域内的sampler请求的服务器响应结果中通过正则表达式提取值所需值,生成模板字符串,并将结果存储到给定的变量名中。
先上个图:
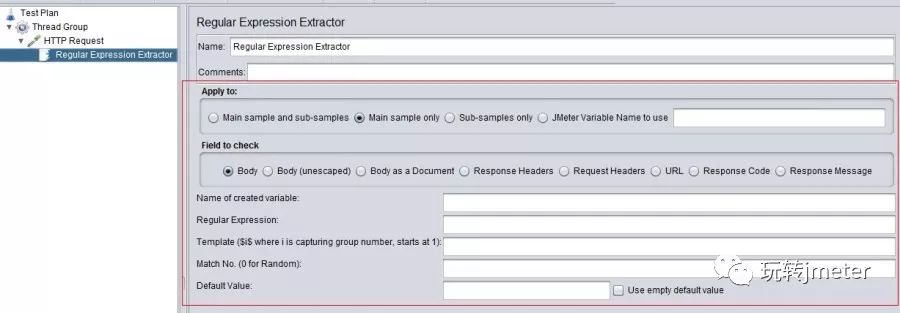

各配置项介绍:
APPly to:作用范围(返回内容的断言范围)
1、Main sample and sub-samples:作用于主节点的取样器及对应子节点的取样器
2、Main sample only:仅作用于主节点的取样器
3、Sub-samples only:仅作用于子节点的取样器
4、JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称),从指定变量值中提取需要的值。
Field to check:要检查的响应报文的范围
1、主体:响应报文的主体,最常用
2、Body(unescaped):主体,是替换了所有的html转义符的响应主体内容,注意html转义符处理时不考虑上下文,因此可能有不正确的转换,不太建议使用
3、Body as a Document:从不同类型的文件中提取文本,注意这个选项比较影响性能
4、Response Headers:响应信息头(如果你使用的是中文版的Jmeter,会看到这一项是信息头,这是中文翻译问题,应以英文为准)
5、Request Headers:请求信息头
6、URL:请求url
7、Response Code:响应状态码,比如200、404等
8、Response Message:响应信息
***可以看出,这里已经提供了各种场景下的提取功能,非常全面!
引用名称(Reference Name):
Jmeter变量的名称,存储提取的结果;即下个请求需要引用的值、字段、变量名,后文中引用方法是${引用名称}
正则表达式(Regular Expression):
使用正则表达式解析响应结果,()括号表示提取字符串中的部分值,前后是提取的边界内容。
***正则的基本使用方法可参考正则表达式的官方说明,本文下方也会有更详细介绍。
模板(Template):
正则表达式的提取模式。
如果正则表达式有多个提取结果,则结果是数组形式,模板$1$,$2$等等,表示把解析到的第几个值赋给变量;从1开始匹配,以此类推。
若只有一个结果,则只能是$1$;
匹配数字(Match No):
正则表达式匹配数据的结果可以看做一个数组,表示如何取值:0代表随机取值,正数n则表示取第n个值(比如1代表取第一个值),负数则表示提取所有符合条件的值。
缺省值:
匹配失败时候的默认值;通常用于后续的逻辑判断,一般通常为特定含义的英文大写组合,比如:ERROR等。
重点分析:
下面重点分析一下正则表达式的匹配规则及注意事项:
一、下面是常用的正则表达式操作符
二、贪婪和非贪婪
提到正则表达式,必须要说一下匹配的两种模式:贪婪和非贪婪。
1、贪婪与非贪婪模式是两种不同的表达式匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。
2、下面举个例子,假设有如下响应结果(只截取了其中一部分):
"code":"0","msg":"请求成功","bizSeqNo":"1804242UD01154300109392900987311" ,"result":{"bizSeqNo":"1804242UD01154300109423800987316","transactionTime":"20180424094239"
3、现在从中提取bizSeqNo的值:
"bizSeqNo":"(.*)":贪婪模式,提取结果是:1804242UD01154300109392900987311" ,"result":{"bizSeqNo":"1804242UD01154300109423800987316","transactionTime":"20180424094239
"bizSeqNo":"(.*?)":非贪婪模式,提取结果是:1804242UD01154300109392900987311
大家可以自行体会一下其中的差别。
三、进阶匹配问题
1、如何获取数组结果?
如果有多个匹配的结果,则获取到的是个数组,此时若要提取其中的内容,调用方式为${ bizSeqNo _1},${bizSeqNo _2}...,如果想要得到匹配出的结果的个数,用${bizSeqNo _matchNr},如果想随机选取一个,只需要将匹配数字设为0,使用${bizSeqNo}调用即可。
2、如何获取唯一的匹配结果?
如果想要避免上面获取多种结果的情况,则需要注意把正则表达式写成非贪婪模式,或者增加正则表达式的前后边界,使结果唯一匹配既可。
最后告诉大家一个小技巧:
在调试过程中可使用察看结果树和Debug PostProcessor来帮助分析结果。
------------------END------------------
----yolanda
以上是关于详解JMeter正则表达式提取器的主要内容,如果未能解决你的问题,请参考以下文章