正则表达式和re库
Posted Young的编程日记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式和re库相关的知识,希望对你有一定的参考价值。
基本语法
基本语法就直接搬运嵩天老师的课件了,这个没啥好说的,得多练才能熟!
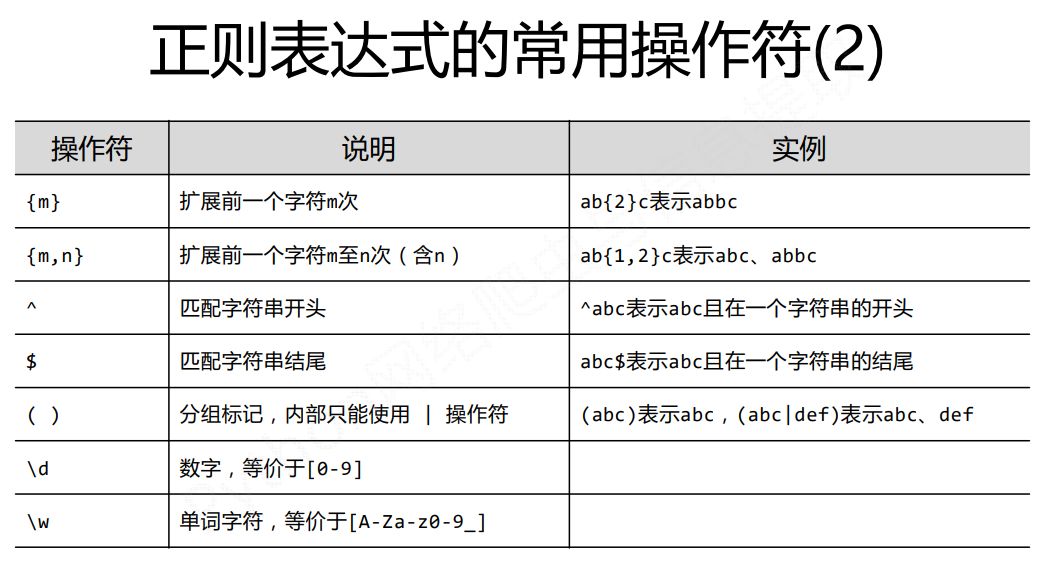
针对上面的图再补充几点:
.表示除了\n换行符以外的任何字符\s表示任何空白字符,包括空格。、制表符、换页符等,等价于[\f\n\r\t\v],(\f是换页符,\v是制表符)\S表示任何的非空白字符,等价于[^\f\n\r\t\v]
举几个例子
python+:对应字符串python,pythonn,pythonnn...
p(y|yt|yth|ytho)?n:对应字符串pn,pyn,pytn,pythn,python
py[th]on:对应字符串pyton,pyhon
py<a href="#footnote-th"><sup>[th]</sup></a>?:对应字符串on:pyon,pyaon,pybon...
py{:3}n:对应字符串pn,pyn,pyyn,pyyyn


re库
compile方法
我们上面写的正则表达式,他其实只是符合正则表达式规则的字符串,字符串我们是无法用来匹配其他文本的,所以在Python中,我们需要利用 re库将符合正则表达式的字符串编译成正则表达式对象,然后用它来匹配原始文本最终获取所需要的匹配文本。
我们可以用 compile()方法将正则表达式文本编译成正则表达式对象,来看个例子
>>> import re
>>> rex = r'a.d' #正则表达式文本
>>> type(rex)
<class 'str'> #rex是字符串类型
>>> text = 'and' #原始文本
>>> pattern = re.compile(rex) #利用compile方法将正则表达式文本编译成正则表达式对象
>>> pattern
re.compile('a.d')
>>> type(pattern)
<class 're.Pattern'> #这里可以看到使用compile方法后,rex的对象类型是正则表达式类型
>>> r = pattern.match(text) #利用match方法用正则表达式对象来匹配原始文本
>>> r
<re.Match object; span=(0, 3), match='and'>
>>> type(r)
<class 're.Match'> #使用match方法返回的是一个match对象
>>> r.group() #利用match对象的group方法获取匹配字符串
'and'
match方法
上面是一个完整的流程,但其实在日常编写中,我们可以直接利用match方法,省时省力,上面的代码等同于:
>>> r = re.match(r'a.d',text)
>>> r
<re.Match object; span=(0, 3), match='and'> #可以看到和上面代码效果是一样的
match方法是:从原始字符串的开始位置起匹配正则表达式,返回match对象
re.match(pattern,string,flags)
pattern:正则表达式
string:待匹配原始文本
flags:控制标记
控制标也没啥好说的,最常用的就是re.S,来看下 match方法的使用以及它返回的match对象的属性方法。
另外要注意下,就是re库中要用原生字符串的形式,就是 r'string',因为很多字符比如 \b在ASCII码中是退格键的意义,然而在正则表达式中他是匹配边界的意思,所以我们要用原生字符串来防止反斜杠 \对字符串进行转义,这个记住就好了。
看个例子:
>>> r = re.match(r'a.d',text)
>>> r
<re.Match object; span=(0, 3), match='and'>
>>> type(r)
<class 're.Match'>
>>> r = re.match(r'a.b',text)
>>> r
>>> type(r)
<class 'NoneType'> #r的类型事空
从上面我们可以看到当match方法从原始字符串中获取匹配字符串时,他返回的是match对象,当他没有获取到匹配字符串时,他返回的是空。
再看
>>> import re
>>> r = re.match(r'a.d','and and')
>>> r
<re.Match object; span=(0, 3), match='and'>
>>> r = re.match(r'a.d','and he is ...')
>>> r
<re.Match object; span=(0, 3), match='and'>
>>> r.group()
'and'
>>> r = re.match(r'a.d','this is and ...')
>>> r
>>> type(r)
<class 'NoneType'>
从上面这个例子中我们可以看到,match方法是从原始字符串的开头进行匹配的,如果开头不匹配,那么就算你后面有匹配的字符串,他也获取不到。
再来看下match对象的属性
>>> r = re.match(r'a.d','and he is ...and')
>>> r
<re.Match object; span=(0, 3), match='and'>
>>> r.pos #正则表达式搜索文本的开始位置
0
>>> r.endpos #正则表达式搜索文本的结束位置
16
>>> r.string #待匹配的原始文本
'and he is ...and'
>>> r.re
re.compile('a.d') #匹配时使用的正则表达式
match对象的方法
>>> r.start() #获取的匹配字符串在原始字符串中的开始位置
0
>>> r.end() #获取的匹配字符串在原始字符串中的结束位置
3
>>> r.span() #返回(.start(),.end())
(0, 3)
>>> r.group() #获取匹配后的字符串
'and'
>>> r.group(0) #同group(),还有group(1),group(2),但这个r变量没有,这个后面再说
'and'
search方法
我们发现match方法是从字符串开头进行匹配的,开头不匹配就获取不了,所以为了弥补这一缺陷,我们可以用 search()方法。
re.search(pattern,string,flags)
search方法是从在原始字符串中搜索匹配正则表达式的字符串,如果有多个匹配的字符串,则返回第一个,同样的,search方法返回的也是match对象
看个例子
>>> r = re.match(r'a.d','this is and and and')
>>> r
>>> type(r)
<class 'NoneType'> #可以看到,开头字符不匹配的话,match是获取不到字符串的
>>> r = re.search(r'a.d','this is and and and')
>>> r
<re.Match object; span=(8, 11), match='and'> #search方法是从开头进行搜索的,然后在寻找匹配字符串,所以search方法是可以获取后面的匹配字符串的,但是只获取第一个符合条件的字符串
>>> r.group()
'and'
其实我们通过 r.pos和 r.endpos可以发现,match方法和search方法都是从开头搜索,到末尾结束的,但是match是在开头就进行匹配,而search是在搜索过程中匹配的。这就是造成他们之间差异的原因(个人理解)
findall方法
search方法只能获得第一个符合条件的字符串,那么如果我们想获取所有的满足条件的字符串呢,用 findall()方法
re.findall(pattern,string,flags)
看个例子
>>> r = re.findall(r'a.d','this is a and and and')
>>> r
['and', 'and', 'and']
可以发现, findall方法可以获取所有的符合正则表达式的字符串,并且他返回的是一个列表。
匹配目标字符串
我们之前说过,group方法不仅有 geoup(0)还有 group(1), group(2),那么怎么获取 group(1)呢,很简单,往正则表达式中加括号 ()就行了。
看个例子:
>>> text = 'my telephone number is 18888888888,my email is 888888@qq.com'
>>> r = re.search(r'.*?(\d+).*?(\w+?@\w*?\.(com|cn))',text)
>>> r
<re.Match object; span=(0, 60), match='my telephone number is 18888888888,my email is 88>
>>> r.group(0)
'my telephone number is 18888888888,my email is 888888@qq.com'
>>> r.group(1)
'18888888888'
>>> r.group(2)
'888888@qq.com'
>>> r.group(3)
'com'
>>> r.group(4)
Traceback (most recent call last):
File "<pyshell#18>", line 1, in <module>
r.group(4)
IndexError: no such group
贪婪模式
这里再说一下贪婪模式,re库默认是使用贪婪模式的,什么是贪婪模式呢,贪婪模式下 *, +这类扩展类操作符会尽可能的匹配更多的字符,从而导致覆盖掉我们想要字符。想要取消贪婪模式的话,只需要在 *, +后面加个 ?就行了,比如 .*?, \d+?,这样他会让 *, +这类扩展类操作符匹配最小的长度。
看个例子:
>>> text = 'my telephone number is 18888888888'
>>> r = re.search(r'.*(\d+)',text)
>>> r
<re.Match object; span=(0, 34), match='my telephone number is 18888888888'>
>>> r.group(1)
'8'
>>> r = re.search(r'.*?(\d+)',text)
>>> r
<re.Match object; span=(0, 34), match='my telephone number is 18888888888'>
>>> r.group(0)
'my telephone number is 18888888888'
>>> r.group(1)
'18888888888'
sub、split函数
split()函数,将原始字符串按照正则表达式进行分割,返回列表类型
re.split(pattern,tring,maxsplit=0,flags=0)
maxsplit:最大分割数,剩余部分作为一个元素输出。就把它理解为将符合条件的字符串取出来,然后进行分割
>>> r = re.split(r'\d+','number_one:123456,number_two:987654') #默认是都取出来,等同于maxsplit=2
>>> r
['number_one:', ',number_two:', '']
>>> r = re.split(r'\d+','number_one:123456,number_two:987654',maxsplit=1) #只取一次字符串
>>> r
['number_one:', ',number_two:987654']
sub()函数,将原始字符串中符合正则表达式的字符串全部替换,返回替换后的字符串。
r = re.sub(pattern,repl,string,count=0,flags=0)
repl:替换匹配字符串的字符串
count:匹配的最大替换次数
>>> re.sub(r'\d+','abc','number_one:123456,number_two:987654')
'number_one:abc,number_two:abc'
>>> re.sub(r'\d+','abc','number_one:123456,number_two:987654',count=1) #只替换一次
'number_one:abc,number_two:987654'
来个test,获取下方html中的歌手名以及歌曲名
html = '''<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳">记事本</a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君"><i class="fa fa-user"></i>但愿人长久</a>
</li>
</ul>
</div>'''
代码:
>>> import re
>>> html = re.sub(r'<i.*?>|</i>','',html) #将li标签去掉
>>> print(html)
<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳">记事本</a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君">但愿人长久</a>
</li>
</ul>
</div>
>>> resoults = re.findall(r'<li.*?singer="(.*?)">(.*?)</a>',html,re.S)
>>> resoults
[('任贤齐', '沧海一声笑'), ('齐秦', '往事随风'), ('beyond', '光辉岁月'), ('陈慧琳', '记事本'), ('邓丽君', '但愿人长久')]
>>> for resoult in resoults:
... print(resoult[0],resoult[1])
...
任贤齐 沧海一声笑
齐秦 往事随风
beyond 光辉岁月
陈慧琳 记事本
邓丽君 但愿人长久
再来个test,获取下方HTML中的邮箱:
html = """
<style>
.qrcode-app{
display: block;
background: url(/pics/qrcode_app4@2x.png) no-repeat;
}
</style>
<div class="reply-doc content">
<p class="">34613453@qq.com,谢谢了</p>
<p class="">30604259@qq.com麻烦楼主</p>
</div>
<p class="">490010464@163.com<br/>谢谢</p>
"""
代码:
>>> resoults = re.findall(r'<p.*?>(\d+?@\w*?\.com).*?</p>',html,re.S)
>>> resoults
['34613453@qq.com', '30604259@qq.com', '490010464@163.com']
>>> for resoult in resoults:
... print(resoult)
...
34613453@qq.com
30604259@qq.com
490010464@163.com
Python中的正则差不多就这些了,主要还是要多练,用得多了就熟了。
以上是关于正则表达式和re库的主要内容,如果未能解决你的问题,请参考以下文章
Python 爬虫正则表达式和re库,及re库的基本使用,提取单个页面信息