阿里程序员带你全面深入了解正则表达式
Posted 码洞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里程序员带你全面深入了解正则表达式相关的知识,希望对你有一定的参考价值。
在日常工作中,经常会用到正则操作。但是对于大多数人来说,操作正则表达式简直就是抓瞎。
本篇文章主要整理了正则表达式匹配的规则,使用中的一些要点,以及用图形化的方式列举出一些常见的正则表达式,希望能给大家带来一定的帮助,能在以后的工作中,用上正则,爱上正则。
PS:不同语言中的正则表达式的规则不完全相同,但是大部分都可以适用。
正则是什么
正则表达式是为了对字符串进行有效 数据提取 以及 匹配 的一种机制,字符串在匹配的过程中将会从第一个位置开始匹配,然后从左往右进行依次匹配,每尝试匹配一次,就会把控制权交由下一个位置,直到匹配结束。
正则表达式是由 普通字符(例如字符 a 到 z)以及 特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
正则的诞生
正则表达式的“祖先”可以一直上溯至对人类神经系统如何工作的早期研究。Warren McCulloch 和 Walter Pitts 这两位神经生理学家研究出一种数学方式来描述这些神经网络。
1956 年, 一位叫 Stephen Kleene 的美国数学家在 McCulloch 和 Pitts 早期工作的基础上,发表了一篇标题为「神经网事件的表示法」的论文,引入了正则表达式的概念。
正则表达式就是用来描述他称为“正则集的代数”的表达式,因此采用“正则表达式”这个术语。
随后,人们发现可以将这一工作应用于使用Ken Thompson 的计算搜索算法的一些早期研究,Ken Thompson是Unix 的主要发明人。正则表达式的第一个实用应用程序就是 Unix 中的qed 编辑器。从那时起直至现在正则表达式都是基于文本的编辑器和搜索工具中的一个重要部分。具有完整语法的正则表达式使用在字符的格式匹配方面上,后来被应用到熔融信息技术领域。自从那时起,正则表达式经过几个时期的发展,现在的标准已经被ISO(国际标准组织)批准和被Open Group组织认定。
匹配规则
下面将正则中的一些基本的匹配规则列出来如下表所示:
要点
贪与不贪
举个例子,假设有以下这段html字符,我想拿到a标签中的内容:
<a>南京长江大桥</a>哈哈<a>南京市长江大桥</a>
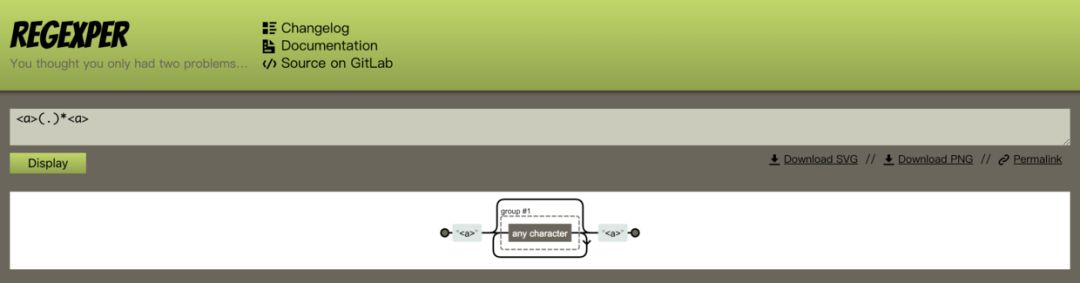
然后我写了这样一个正则: <a>(.)*</a>
在线测试的结果如下:
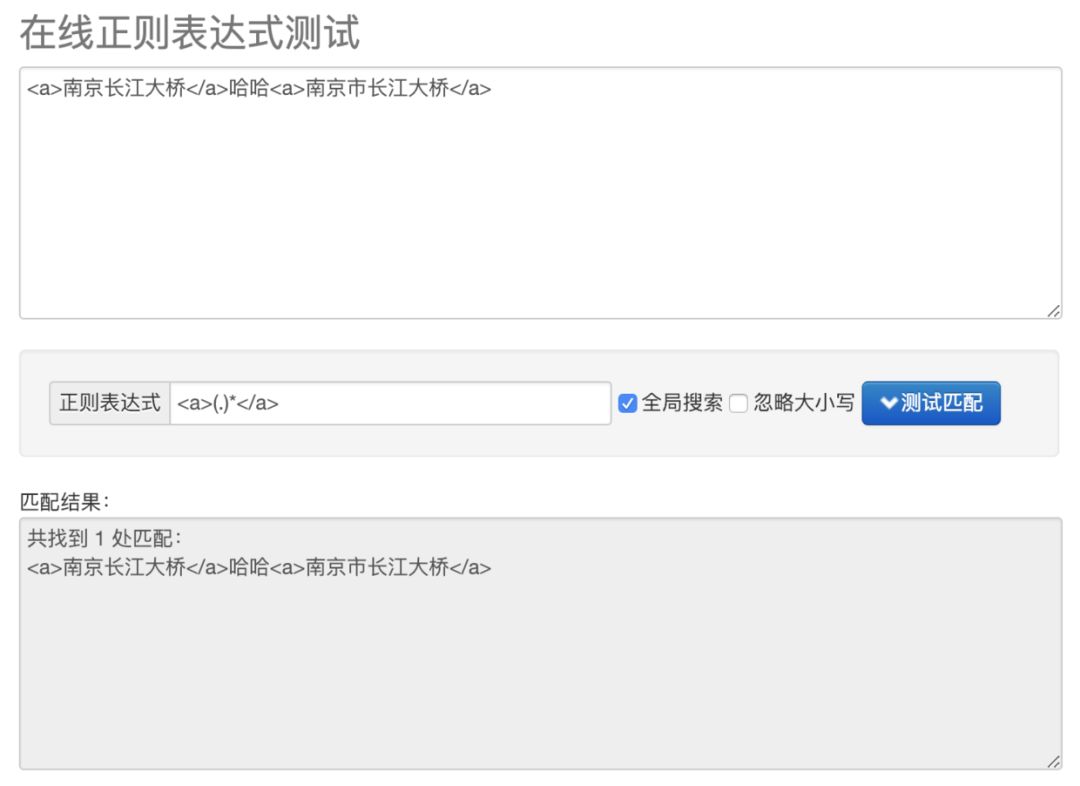
这个结果与我们的预期不符,正常我应该得到两个匹配的结果才对,但是现在却只匹配到一个结果。
现在把刚刚的正则改成这样: <a>(.)*?</a>
在线测试的结果如下:
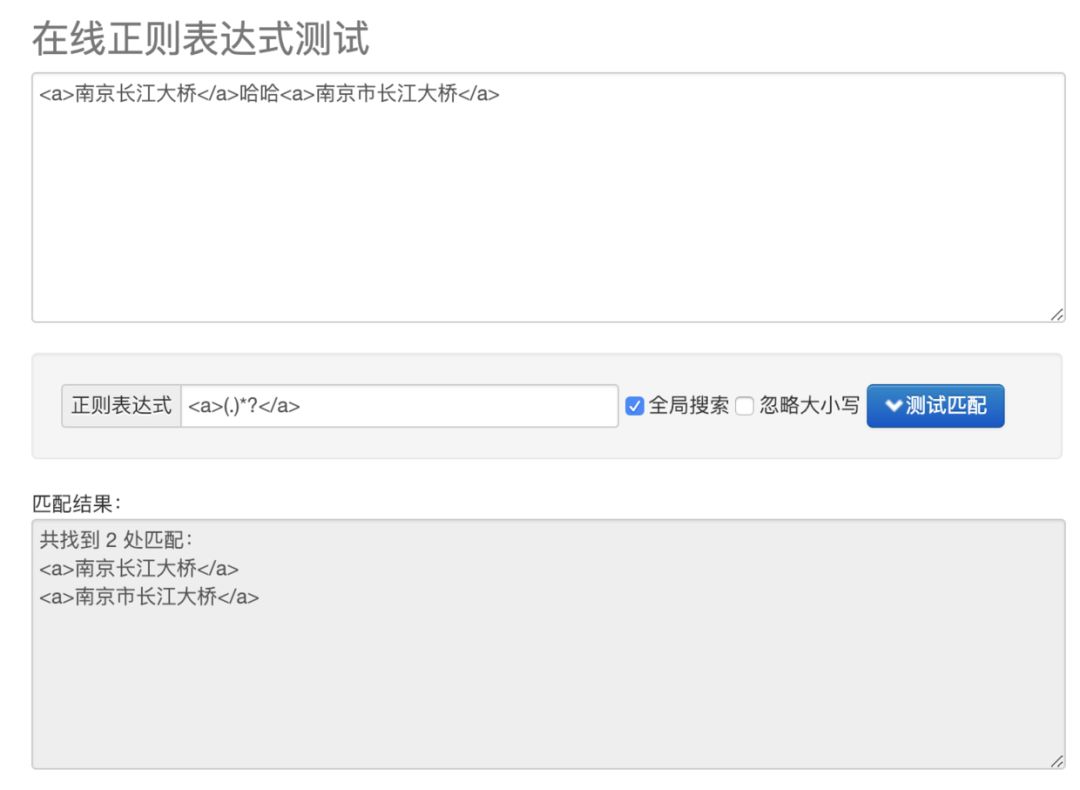
贪 说的是正则在不约束的情况下会继续自动向右进行匹配,直到匹配结束,只要匹配的数据与正则的最后一个值匹配就算是匹配到了。
不贪 说的是只要匹配到就结束,不继续向右进行匹配了。
问号 ? 就解决了贪婪的问题,使得问号前面的字符匹配到之后就结束,但是并不是把 ?放在哪里都可以解决贪婪的,在正则里,有一些属于贪婪模式量词,比如以下这些:
{m,n}
{m,}
?
*
+
断言与零宽
在java中我们知道 断言 可以用来声明一个应该为 true 的事实,只有当断言为真时才会继续进行后续的操作。
在正则中也有 断言 的概念,但是在正则中除了 断言 还有 零宽 的概念。
断言:
通俗点将断言就是 “我断定某某情况是真的” ,而正则中的断言,就是说正则可以断定在 指定的内容 的 前面 或 后面 会出现满足指定规则的内容。比如 "aa1bb2cc3",正则可以用断言找出 bb2 前面有 aa1,也可以找出 bb2 后面有 cc3。
零宽:
零宽就是没有宽度,在正则中,断言只是匹配位置,不占字符,也就是说,匹配结果里是不会返回断言本身的。
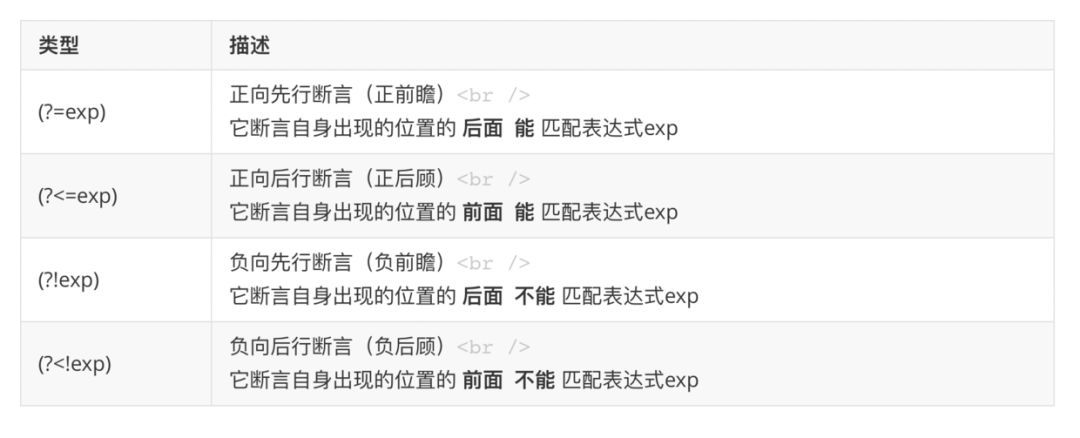
断言一共有四种情况:
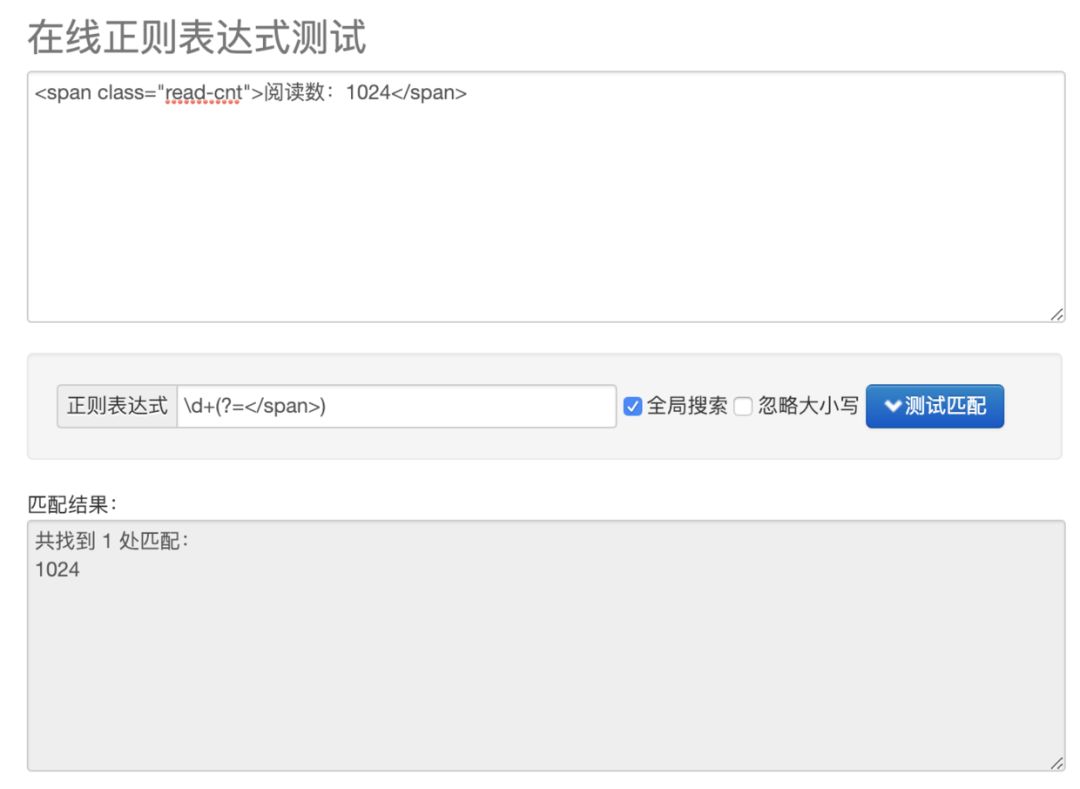
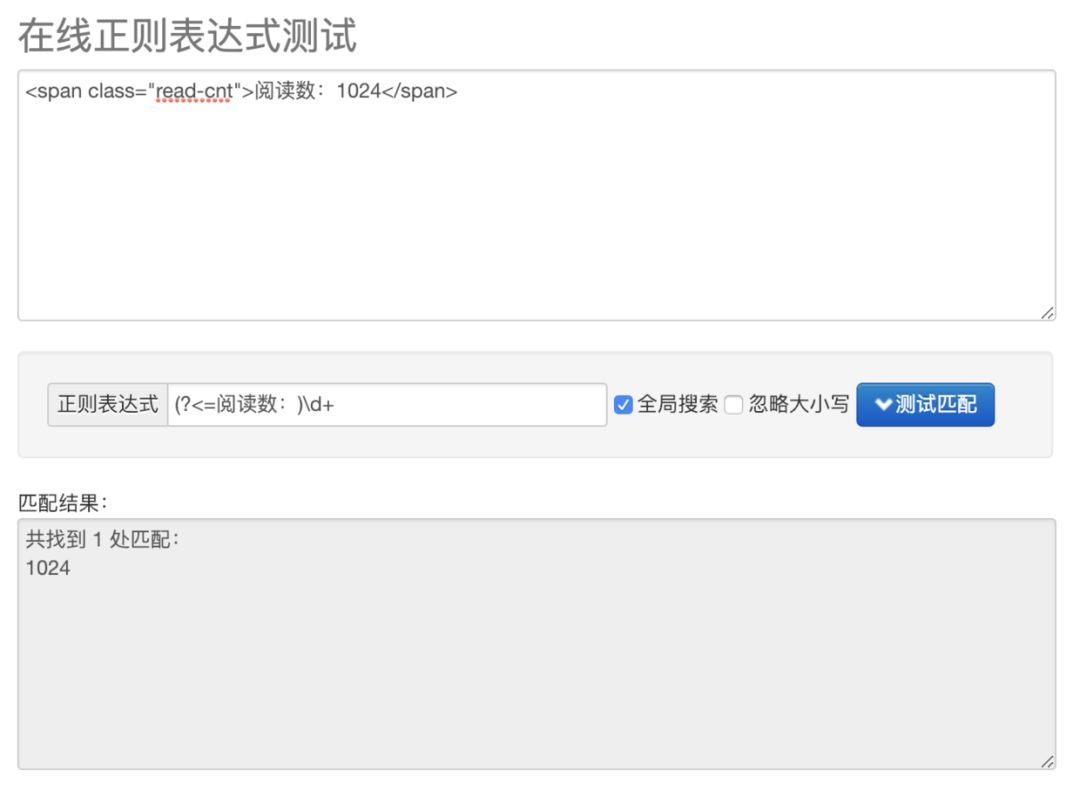
让我们来举个例子来说明吧,假设我们现在拿到了某个网页的html,里面有个阅读数的标签:
<span class="read-cnt">阅读数:1024</span>
现在我们要获取到这个阅读数,该怎么办呢?
如果用正向先行断言来匹配的话,可以这样来写:
\d+(?=</span>)
上述的表达式就是说明,我现在断言整数 \d+ 的 后面 能 匹配表达式: </span>
让我们来验证下结果:
相应的正向后行断言可以这样写表达式:
(?<=阅读数:)\d+
上述的表达式就是说明,我现在断言整数 \d+ 的 前面 能 匹配表达式: 阅读数:
验证下结果如下:
分组
正则表达式中用小括号 () 来做分组,也就是括号中的内容作为一个整体。
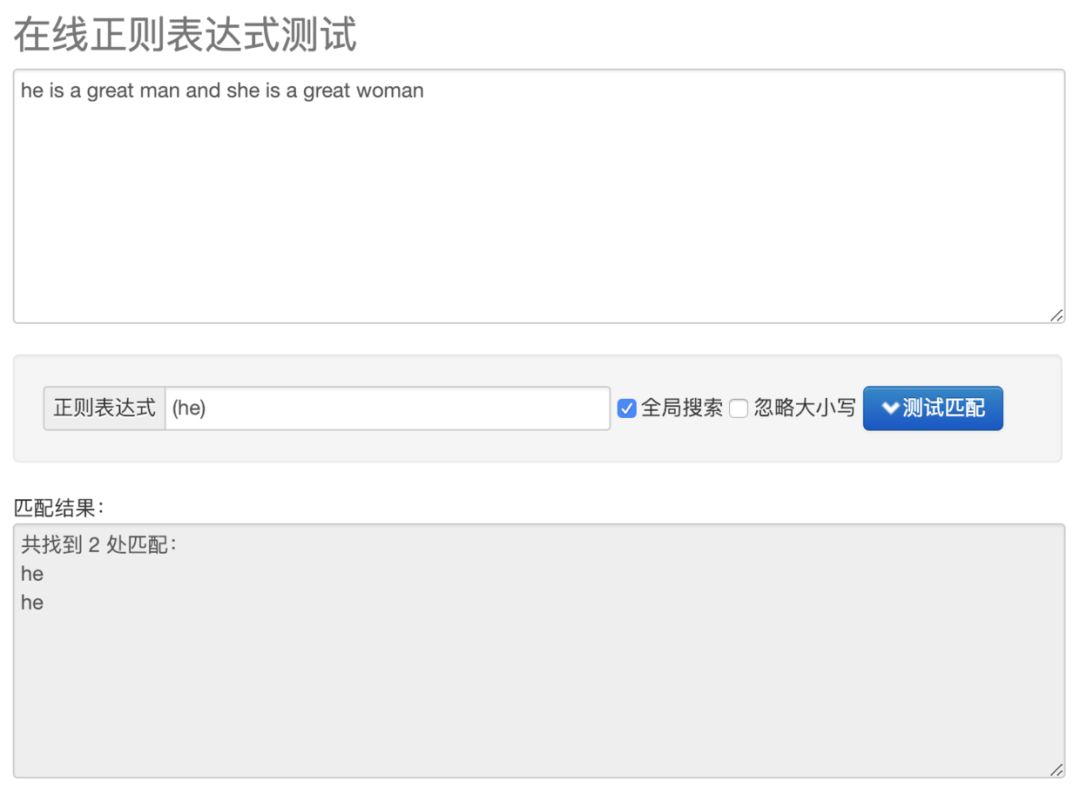
因此当我们要匹配分组 he 的时候,可以用下面这个表达式 :
(he)
我们看到正则表达式用小括号来做分组,那么问题来了:
如果要匹配的字符串中本身就包含小括号,那应该怎么办?
针对这种情况,正则提供了转义的方式,也就是要把这些元字符、限定符或者关键字转义成普通的字符,做法很简单,就是在要转义的字符前面加个斜杠(\)即可。
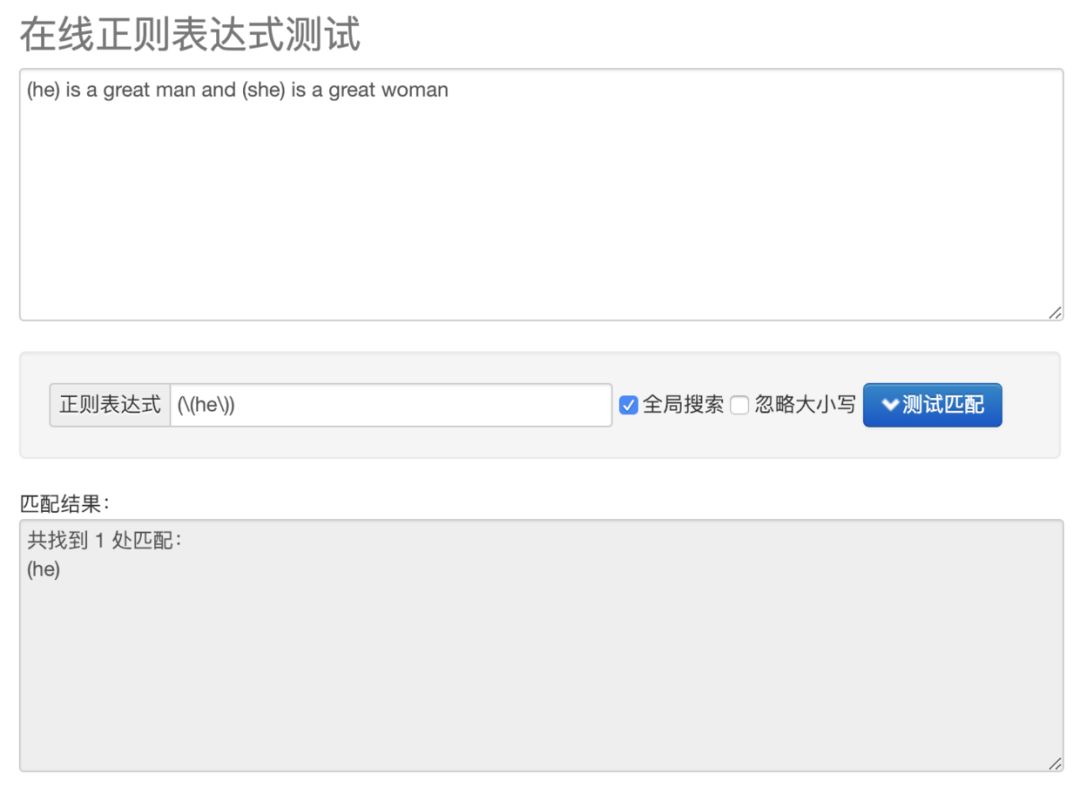
因此当我们要匹配分组 (he) 的时候,可以用下面这个表达式 :
(\(he\))
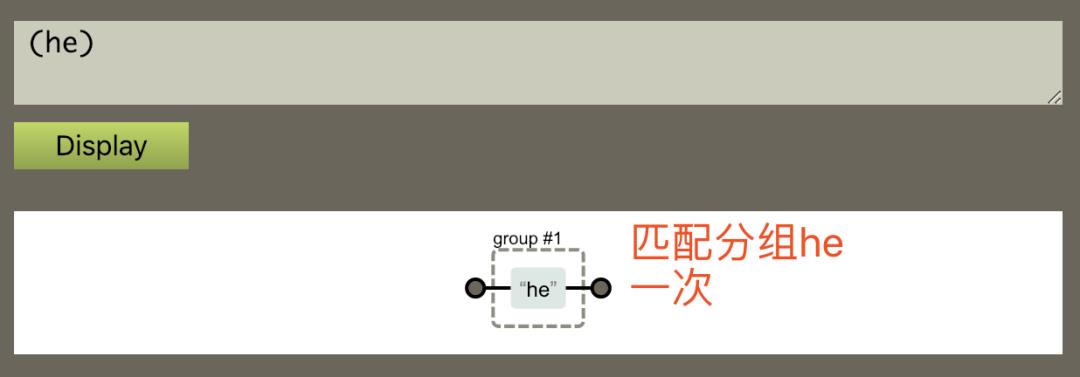
下面我们用一个正则表达式的图形生成工具,做一个对比的实验,让我们对分组和定位有个了解。
1:匹配 he 分组一次 ;
2:匹配 he 分组零或多次;
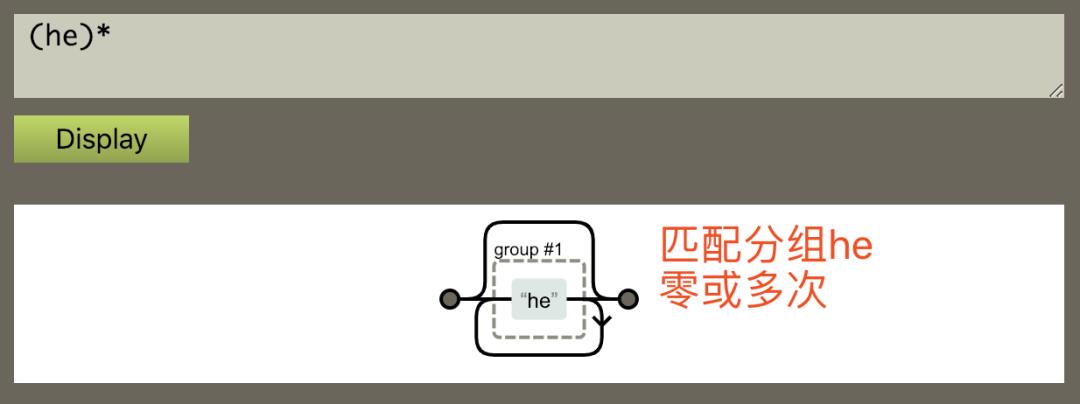
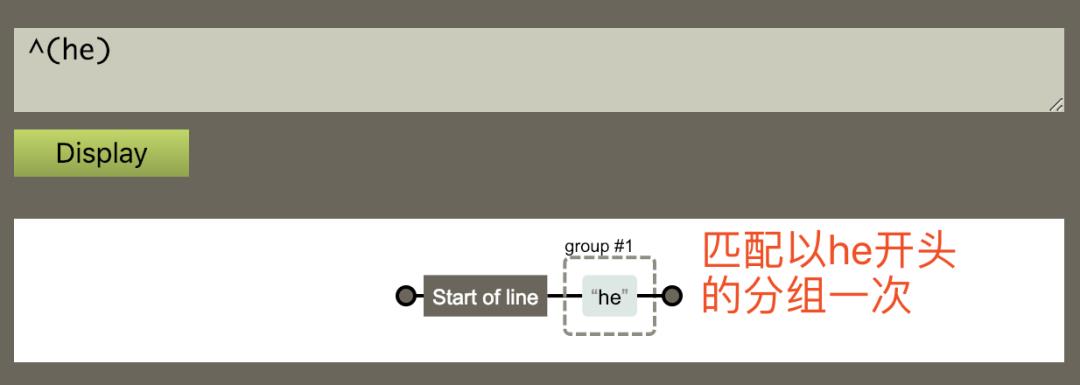
3:匹配以 he 开头的分组一次;
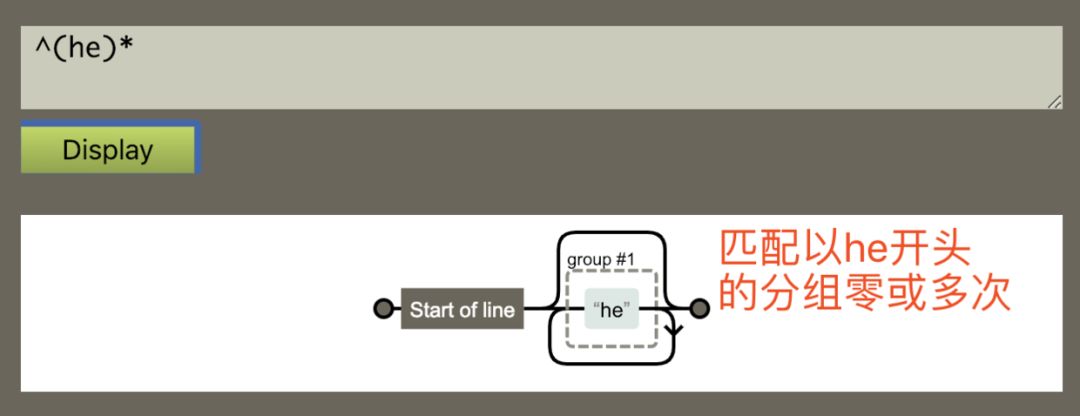
4:匹配以 he 开头的分组零或多次
捕获与反向引用
单纯说到捕获,他的意思是匹配表达式,但捕获通常和分组联系在一起,也就是“捕获组”。
捕获组:
匹配子表达式的内容,把匹配结果保存到内存中以数字编号或显示命名的组里(可以把它想象为java中的array和map),以深度优先进行编号,之后可以通过序号或名称来使用这些匹配结果。
捕获组的表达式为: (exp) ,这个语法跟上面讲到的分组的概念是一样的,只是捕获将匹配到的分组,保存在了内存中,留待后面使用。具体怎么时候他不管,他只需要把匹配到的分组保存在内存中就可以了。
有一种情况当在匹配的过程中,需要与已经捕获到的分组进行匹配,这时就需要使用到保存在内存中的捕获组了,这种使用方式就被称为: 反向引用 。
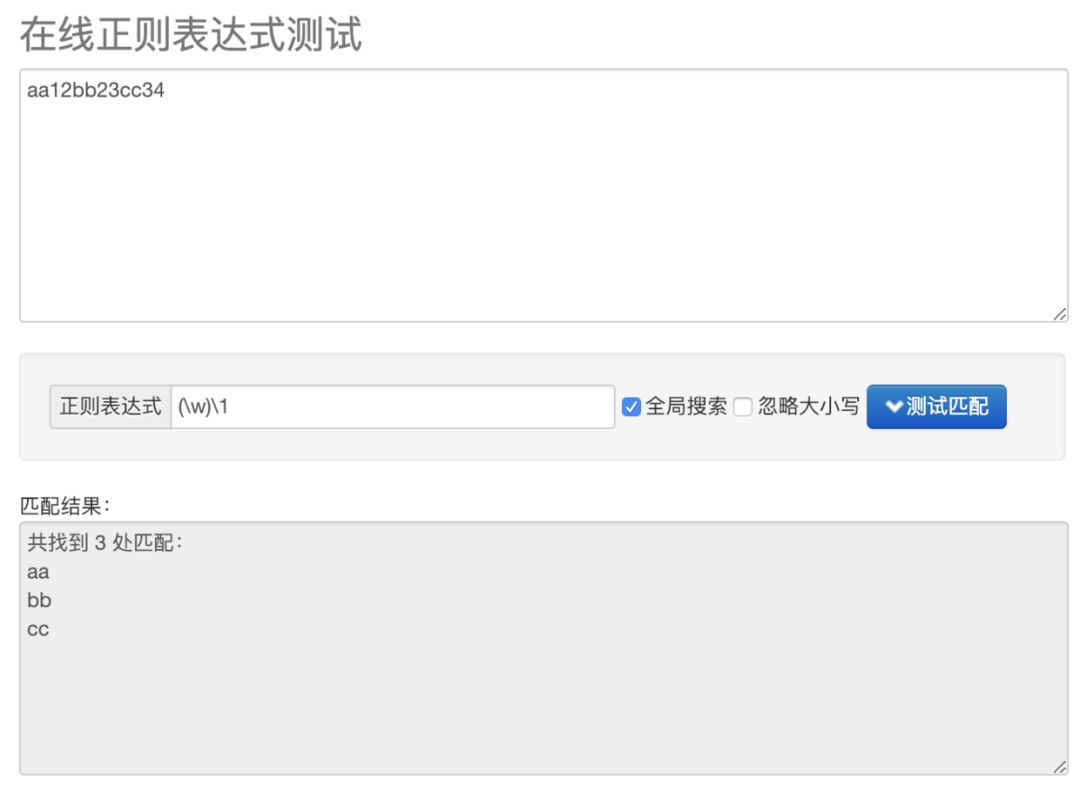
假设我有这样一段文字:
aa12bb23cc34
现在我想拿到成对的字符,该怎么做呢?这种情况下通过断言或者其他方式是办不到的,那我们能否在匹配的过程中将匹配到的一个字符先保存在内存中,然后匹配下一个字符时再与上一个字符相比较,如果相等,就说明匹配成了,拿到了成对的字符了。
那首先我们先要写一个匹配单个字符分组的表达式:
(\w)
那当匹配时捕获到一个字符分组时,我们需要将该字符引用出来,与下一个字符想比较,我们期望匹配的下一个字符也与我当前保存的字符相等,那么表达式就变成了这样:
(\w)\1
这里的 \1 表示的是,当前正则表达式匹配到的 第1个 分组,那就意味着, \2 表示 第2个 分组。
做个测试,结果如下:
那如果我想再匹配复杂一点的结果,比如:XYY 这种的结果,又该怎么写呢?
其实有了上面的基础之后就很简单了,我们需要做的就是 对捕获到的第2个分组进行反向引用 就可以了!
具体的表达式为:
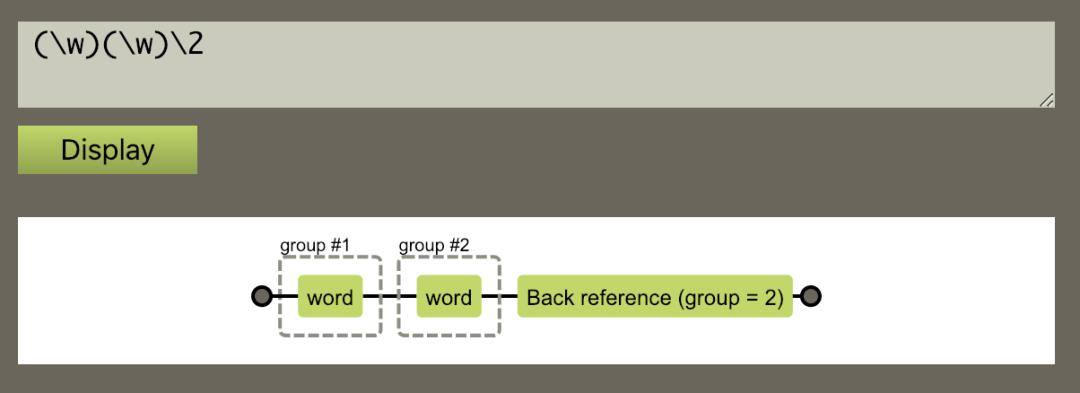
(\w)(\w)\2
测试结果如下:
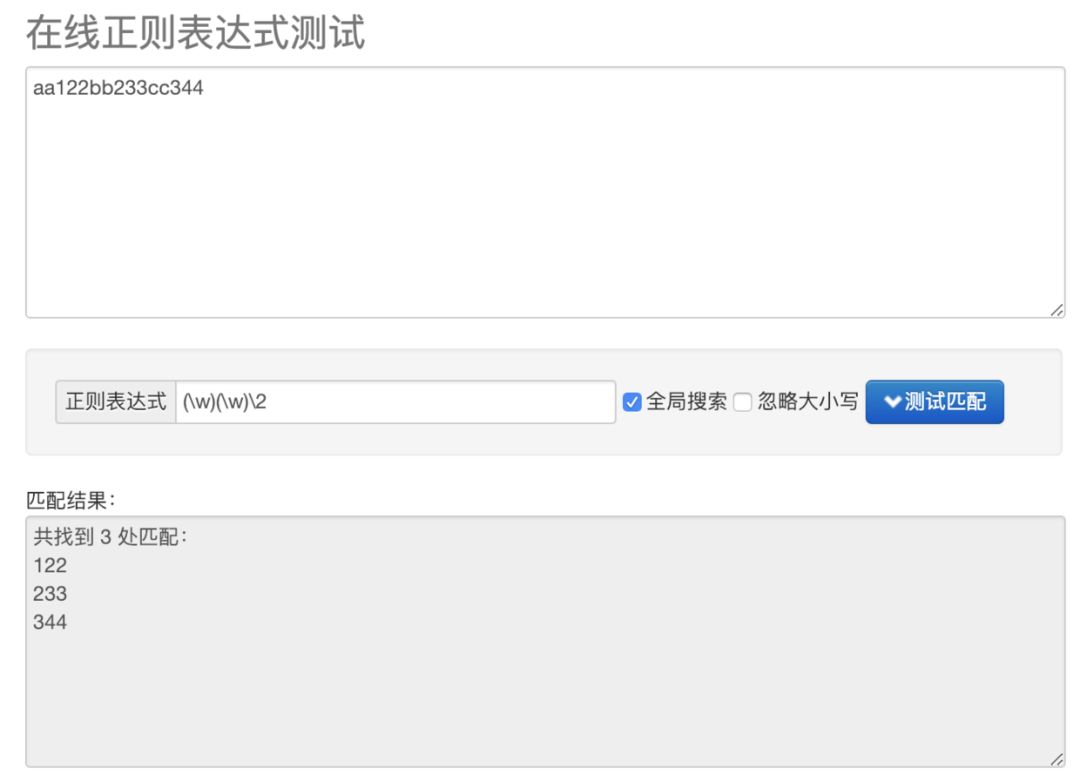
表示成图形就是这样:
常见正则
为了更加形象的了解正则表达式,我们最后通过图形的方式来了解一些常见的正则表达式,使用图形的目的是希望能对冷冰冰的表达式有个更深刻的认识。
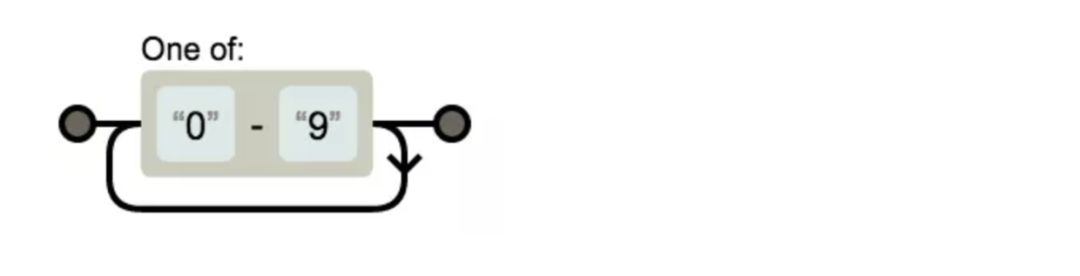
整数
[0-9]+
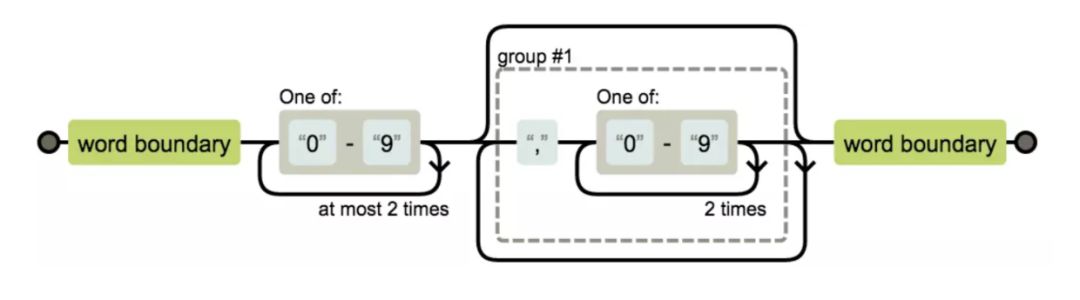
逗号分隔的整数
\b[0-9]{1,3}(,[0-9]{3})*\b
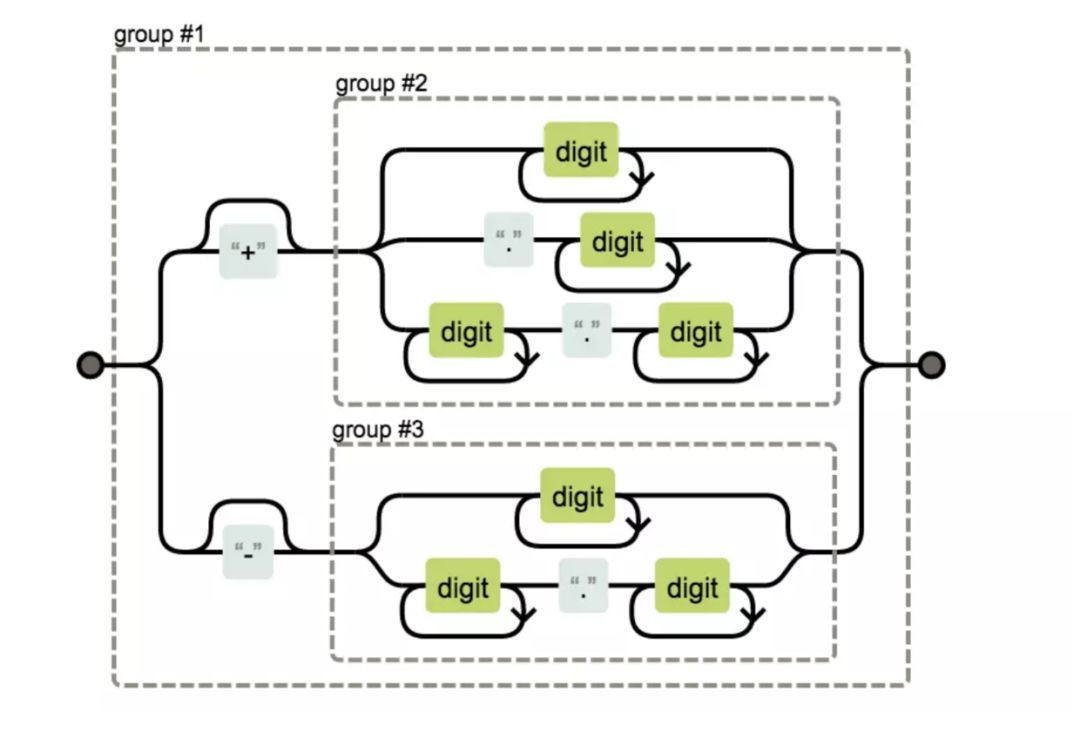
浮点数
(\+?(\d+|\.\d+|\d+\.\d+)|-?(\d+|\d+\.\d+))
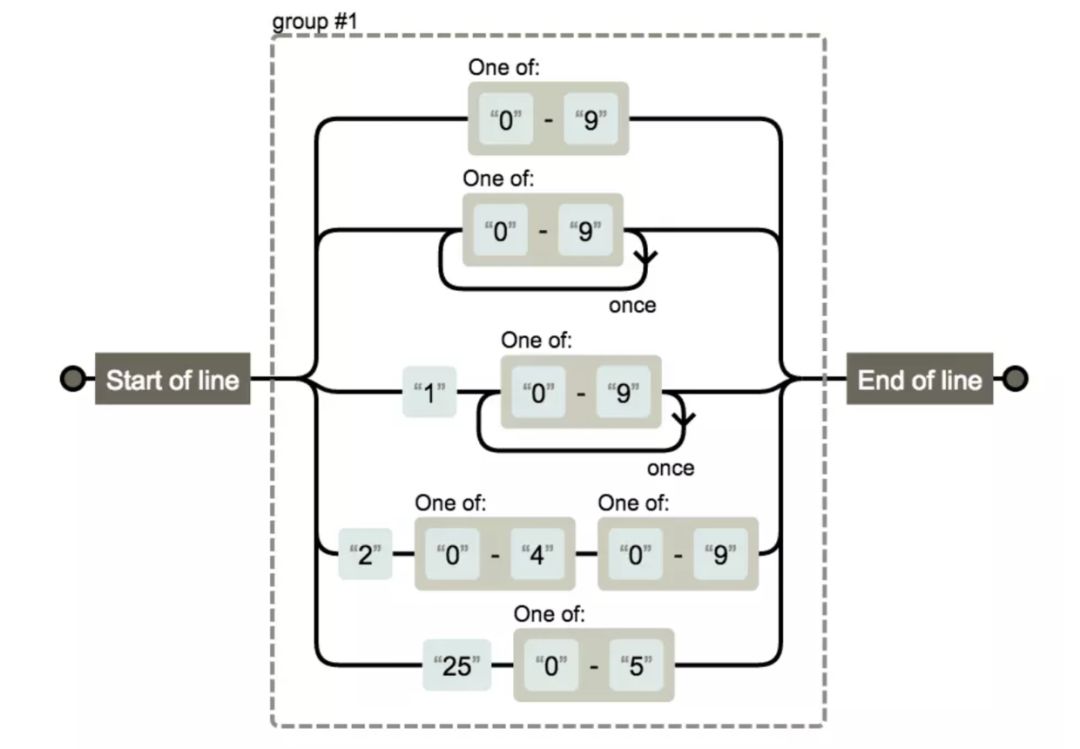
0-255之间的数字
^([0-9]|[0-9]{2}|1[0-9]{2}|2[0-4][0-9]|25[0-5])$
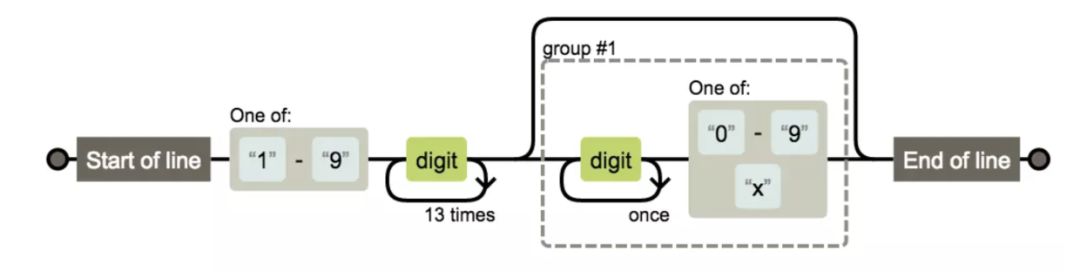
身份证
^[1-9]\d{14}(\d{2}[0-9x])?$
邮箱
^[-\w.]{0,64}@([a-zA-Z0-9]{1,63}\.)*[-a-zA-Z0-9]{1,63}$
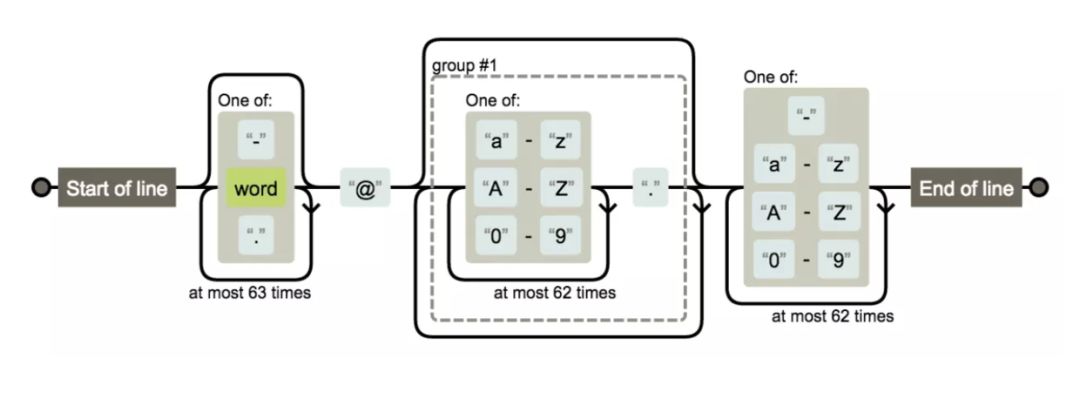
固定电话
(\(?0[1-9]{2,3}\)?-?)?[1-9][0-9]\{6,7}(-[0-9]{1,6})?

邮编
[1-9][0-9]{5}
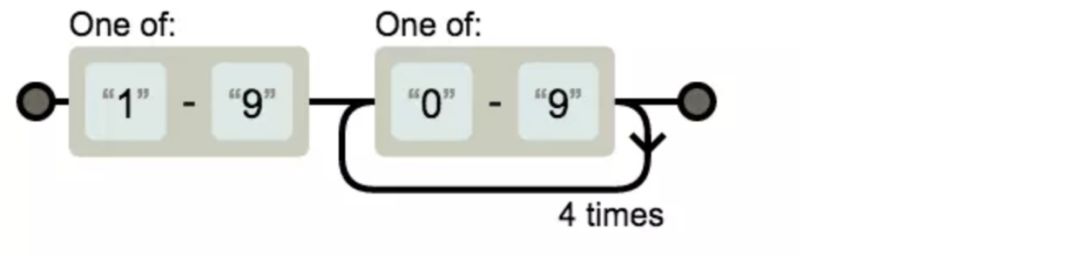
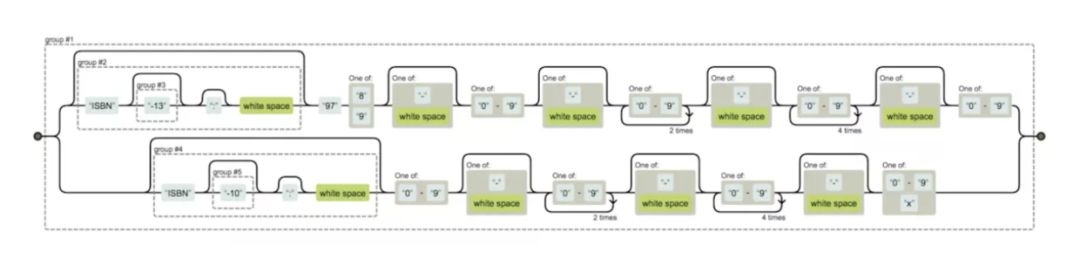
ISBN
((ISBN(-13)?:?\s)?97[89][-\s]?[0-9][-\s]?[0-9]{3}[-\s]?[0-9]{5}[-\s]?[0-9]|(ISBN(-10)?:?\s)?[0-9][-\s]?[0-9]{3}[-\s]?[0-9]{5}[-\s]?[0-9x])
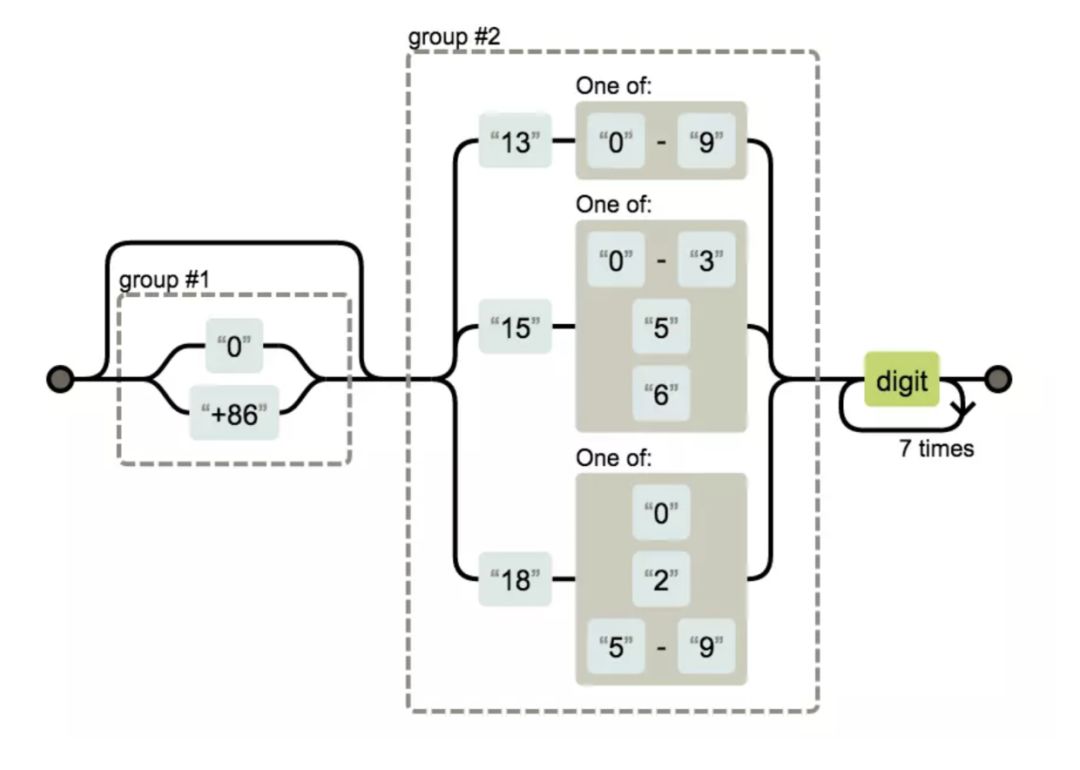
手机号
(0|\+86)?(13[0-9]|15[0-356]|18[025-9])\d{8}
成对的html标签
如 test
<([^>]+)>[\s\S]*?<\/\1>

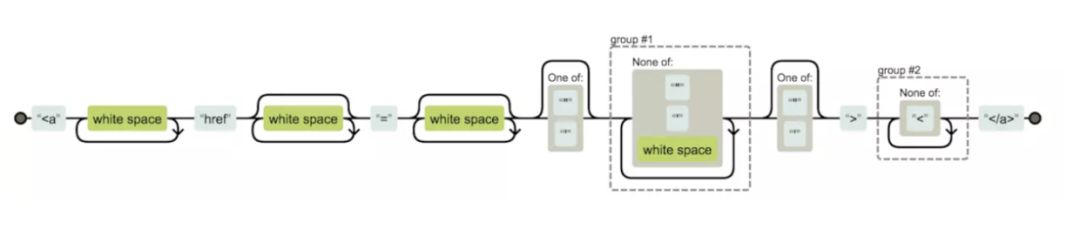
a标签
<a\s+href\s*=\s*["']?([^"'\s]+)["']?>([^<]+)<\/a>
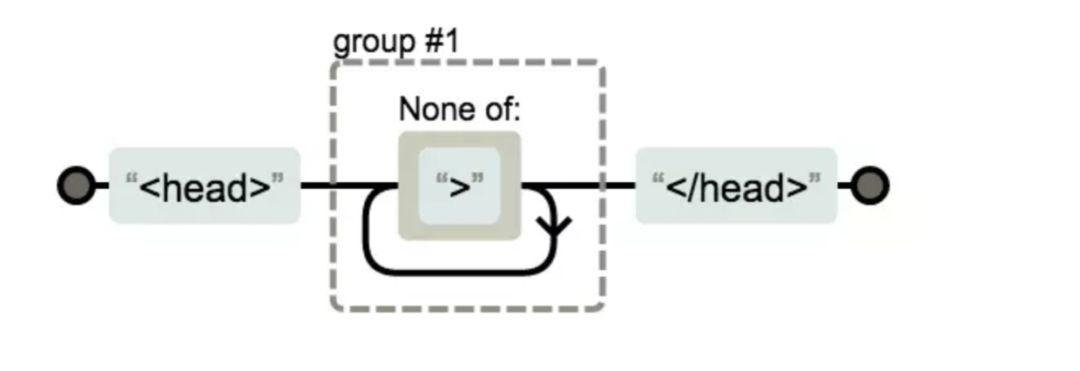
head标签
<head>([^>]+)<\/head>
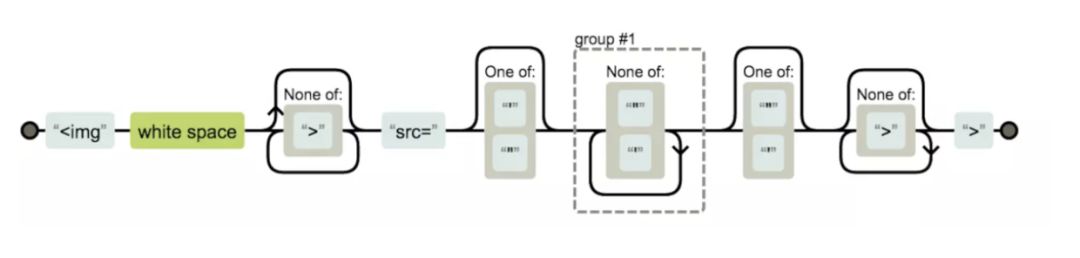
image标签
<img\s[^>]*?src=['"]?([^"']+)["']?[^>]*>
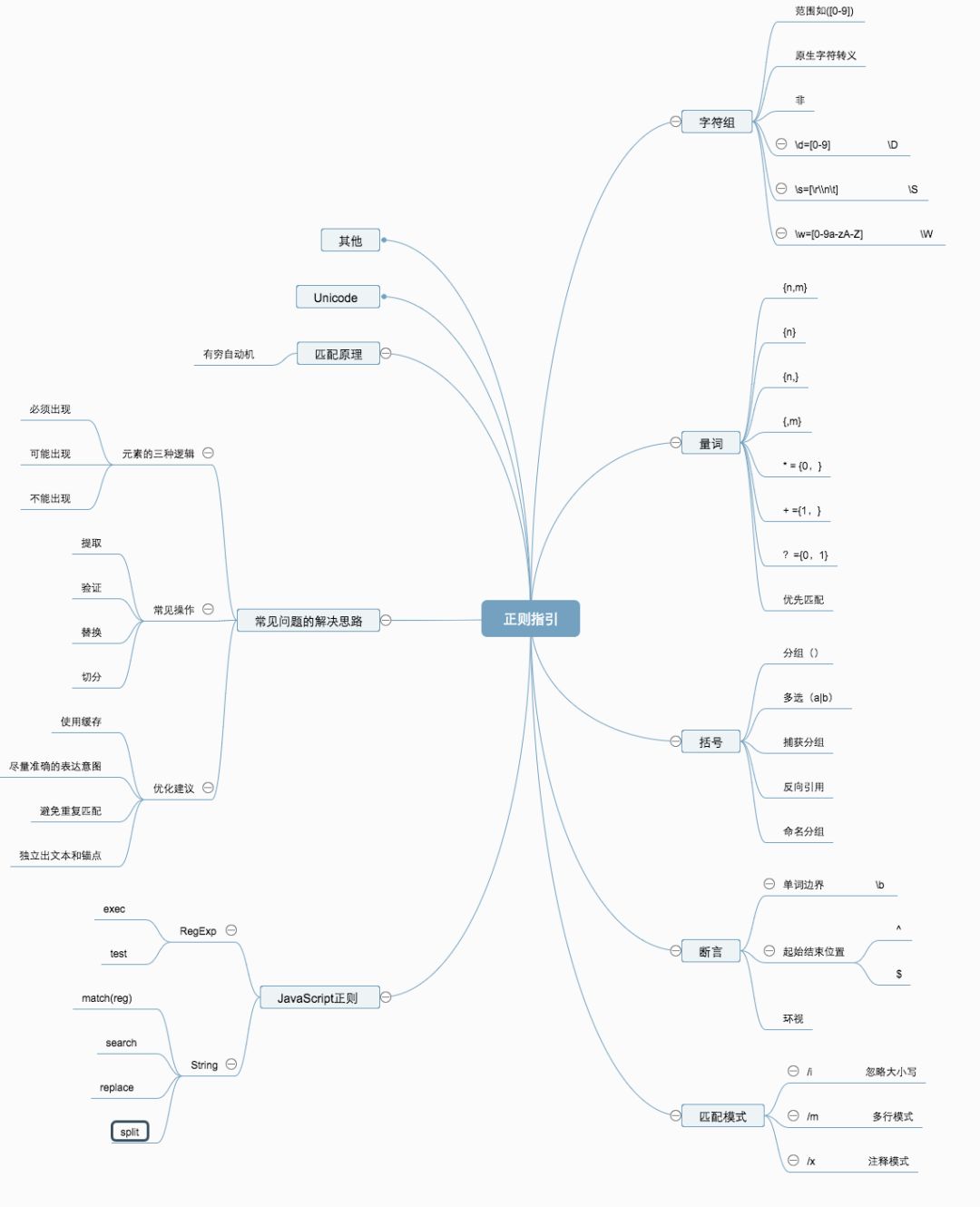
正则思维导图
附常用工具:
在线正则测试:http://tool.oschina.net/regex/
生成正则图片:https://regexper.com
关注「码洞」,老钱带你码出个未来
关注阿里程序员「后羿逐码」
以上是关于阿里程序员带你全面深入了解正则表达式的主要内容,如果未能解决你的问题,请参考以下文章