Solr---有趣的全文检索(原理篇)
Posted 与JAVA邂逅的点滴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr---有趣的全文检索(原理篇)相关的知识,希望对你有一定的参考价值。
(原创)今天我想和大家介绍一下全文检索,看起来好像很高级,那就引来了一个问题,那到底什么才是全文检索呢?
首先,这里给出百度百科的解释:全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文搜索搜索引擎数据库中的数据。
那么以上这段文字介绍的比较学术,所以直接拿例子来讲:比方说百度大家都很熟悉,还有Google大家也都很熟悉。当我们在搜索引擎里面输入“曼彻斯特的天气像坨屎”这句话,那么包含“曼彻斯特”,“天气”,“像”,“坨屎”,的关键字的文章(包括标题和内容)就会出现在我们的搜索列表里面,如下:
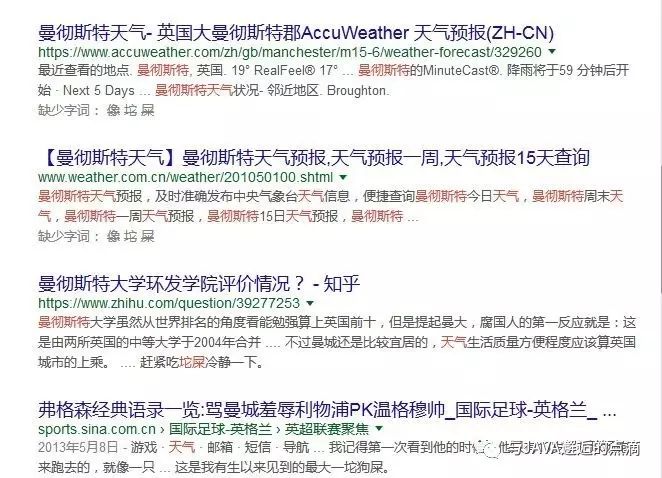
看这些红色的字就是关键字。
1.第一步---使用分词分析器将输入的句子进行分析处理。
也就是说,当我们输入“曼彻斯特的天气像坨屎”这句话之后,会有一个叫做分词分析器的东东帮我们把这句话拆分,它很智能(其实并不是,它包含它自己的接受词库和拒绝词库)的将这句话中的连接词比方说“的”去掉,因为“的”在它的拒绝词库里(其实像标点符号这样的符号也会被去掉),然后“曼彻斯特”,“天气”,“像”,“坨屎”,这几个关键字都在它的接受词库里,那么在输入的句子中最后留下的这几个关键字将作为搜索的关键字,进行对文章的搜索。
2.第二步---用第一步拿到的关键字去和索引库中的文章进行对比,从而得到所相关的文章。这里我们就会想到一个问题,这个索引库是什么?那又如何创建索引库呢?其实方法有很多,其中一种方法叫做倒排索引法创建,让我借用别人ppt上的图阐述一下:
也就是说,当我们在Google输入框中输入“I live in ,shanghai”时,这句话被分词分析器去掉了“,”,“in”,从而拆分成了“I”,“live”,“shanghai”这几个关键字。
然后先用“I”去和关键词那一列进行比对,发现文章号是1,并且出现1次。
再用“live”去和关键词那一列进行比对,发现文章号是1,和2,分别出现2次和1次。
再用“shanghai”和关键词那一列进行比对,发现文章号是2,出现1次。
最后将匹配到的文章显示出来,并且将关键词在文章的部位标红。所以,到此为止我们的搜索结果就显现出来了。
怎么样是不是很神奇?像一些大型网站的 站内搜索的原理也就如此。其实,像某度它们为什么能获取如此大的数据量,其实某度拥有自己的爬虫工程师,时时刻刻从互联网上“爬取”有用的文章信息,并且导入索引库。这样用户搜索起来就搜索到呈现出来的界面了。
今天就到这里,况且Andy今天网开一面放我们出来享受阳光,来迎接“屎一样”的曼彻斯特的未来天气。
这个全文检索个人感觉比较有意思,所以最近会再次发布有关全文检索的文章。
大概是关于:1.简单的介绍一下lucene。
2.简单介绍一下Solr(lucene的一个框架)
3.solr在linux环境下的搭建。
以上是关于Solr---有趣的全文检索(原理篇)的主要内容,如果未能解决你的问题,请参考以下文章