Solr全文检索基本原理及评分机制
Posted ChangbaDev
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr全文检索基本原理及评分机制相关的知识,希望对你有一定的参考价值。
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比 Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进⾏了优化,并且提供了一个完善的功能管理界面,是一款⾮常优秀的全文搜索引擎。(来⾃百度百科) 这里主要介绍:
全⽂检索基本原理
评分机制
全文检索基本原理
Solr/Lucene采用的是一种反向索引(倒排索引) 下图是个很好的说明:
左边保存的是字符串序列,称之为字典
右边是字符串的文档(Document)编号链表,称为倒排表(Posting List)
譬如搜索”爱“,索引会找到,包含“爱”的文档有35,56,255,267,355,而不用在整个数据中去搜索了,如果我们搜索即有“爱”,又有“我”,那么取两个倒排表的交集即可(结果56,267)。
索引创建
索引的创建过程如下:
这里大致讲解一下数据录入到Solr中都发生了什么,创建的过程大致如下:
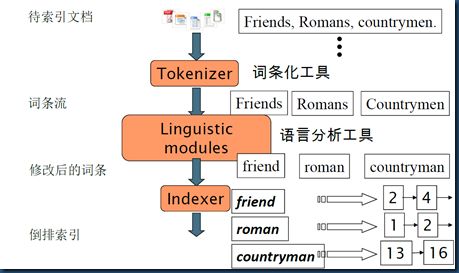
现在举个例子来讲解下
比如现在有以下两句歌词:
月亮代表我的心
借我借我一双慧眼吧
第一步:把原始文档交给分词组件(Tokenizer) 分词组件(Tokenizer)会做以下几个事情(这个过程称为: Tokenize),处理得到的结果是词汇单元(Token):(譬如我们整合分词组件是IK分词器)
将文档分成⼀个单独的单词(如果有分词器,则会按照分词器来进⾏分词)
去除标点符号
去除停止词(stop word)
第二步:词汇单元(Token)传给语言处理理组件(Linguistic Processor) 语⾔处理组件(linguistic processor)主要是 对得到的词元(Token)做一些语言相关的处理(英文的处理如:⼤小写转换,将单词缩转变或减为词根形式)。 语⾔处理组件(linguistic processor)处理得到的结果称为词(Term),例子中经过语言处理后得到的词(Term)如下:
月亮 代表 我 心 借我 我 借我 我 一双 一 双 慧眼
第三步:得到的词(Term)传递给索引组件(Indexer)
1.利用得到的词(Term)创建一个字典
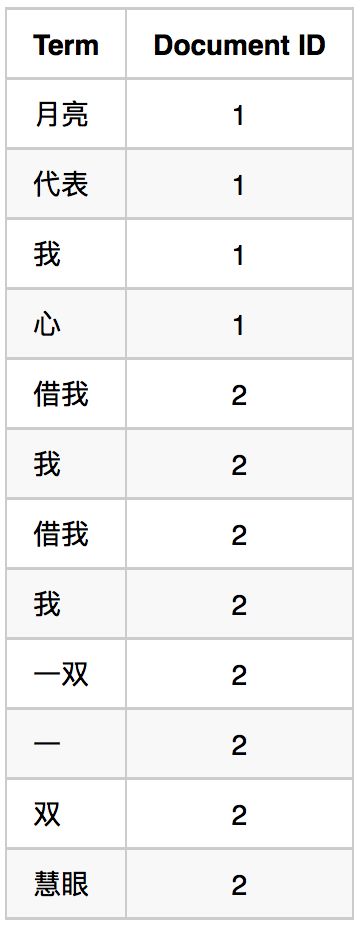
2.对字典按字母顺序排序
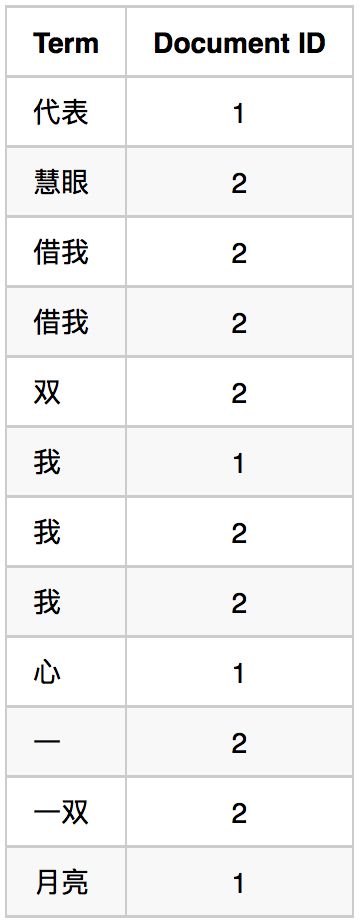
3.合并相同的词(Term)成为文档倒排(Posting List)链表
以上就是有关Solr索引的简介了,下面来说比较重要的Solr的打分规则,这里有两个重要的词
Document Frequency(df):⽂档频次,表示多少文档出现过此词(Term)
Term Frequency(tf):词频,表示某个文档中该词(Term)出现过⼏次
评分机制分析
评分机制的大致准则有两个:
整个文档集合中包含某个词的文档数量越少,这个词越重要(IDF)
某个词或短语在一篇文章中出现的次数越多,越相关(TF)
下面譬如在我们唱吧中搜索(告白气球),用querydebug取一条数据来分析(q:告白气球&&qf:name):
总打分计算
可见最后的得的总分是由在name域中搜索到的“告白”和“气球“得的分加上一个权重分
即:域的得分7.120619=3.3469656 + 3.773653 权重的分=0.30002856
总分 7.4206476 = 7.120619+0.30002856
每个域打分规则
field的score得分=域权重fieldWeight * 查询权重queryWeight
3.3469656 = 0.6829876 * 4.900478
3.773653 = 0.72521734 * 5.203479
queryWeight的计算
public void normalize(float queryNorm, float boost) {
this.boost = boost;
this.queryNorm = queryNorm;
this.queryWeight = queryNorm * boost * this.idf.getValue();
this.value = this.queryWeight * this.idf.getValue();
}
可以看出:
queryWeight = queryNorm * boost * idf ,而Lucene中boost默认为1
0.6829876 = 7.8407645 * 1 * 0.08710727
idf的计算
idf是项目在倒排文档中出现的频率,计算方式为
public float idf(long docFreq, long numDocs) {
return (float)(Math.log((double)numDocs / (double)(docFreq + 1L)) + 1.0D);
}
其中Math.log(number)这个方法相当于数学的ln(number)
其实就是:1 +ln(文档总数/(包含t的文档数+1))
idf(7.8407645)=1+ln(3145090/(3362+1))
这就是为什么计算方式是物以稀为贵的准则了(出现关键词t的结果d越少,结果率反比越高。)
docFreq是根据指定关键字进行检索,检索到的Document的数量,我们测试的docFreq=3362;
numDocs是指索引文件中总共的Document的数量,我们测试的numDocs=3145090 queryNorm的计算
public float queryNorm(float sumOfSquaredWeights) {
return (float)(1.0D / Math.sqrt((double)sumOfSquaredWeights));
}
Math.sqrt(number)这个方法相当于数学的√number 这里,sumOfSquaredWeights的计算是在org.apache.lucene.search.TermQuery.TermWeight类中的sumOfSquaredWeights方法实现:
public float sumOfSquaredWeights() {
queryWeight = idf * getBoost(); // compute query weight
return queryWeight * queryWeight; // square it
}
其实默认情况下,sumOfSquaredWeights = idf * idf,因为Lucune中默认的boost = 1.0。
由此算出:
sumOfSquaredWeights=7.8407645 * 7.8407645 + 8.325566 * 8.325566 = 130.792637
queryNorm = 1/√130.792637 = 0.08710727
fieldWeight的计算
fieldWeight = tf * idf * fieldNorm
简单说下tf的计算 tf就是只term frequency 其实就是结果中term出现的次数
tf=√1 (如果结果是“告白告白气球”,那针对“告白”的tf=√2)
fieldNorm的计算是在索引的时候确定了。如果使用ClassicSimilarity的话,它实际上就是lengthNorm,域越长的话Norm越小,在org/apache/lucene/search/similarities/ClassicSimilarity.java里面有关于它的计算:
public float lengthNorm(FieldInvertState state) {
int numTerms;
if(this.discountOverlaps) {
numTerms = state.getLength() - state.getNumOverlap();
} else {
numTerms = state.getLength();
}
return state.getBoost() * (float)(1.0D /Math.sqrt((double)numTerms));
}
fieldnorm(t,d)=d.getBoost() * lengthNorm(field) * f.getBoost()
lucene中getBoost默认都是1(和搜索时设置的权重有关),所以关键是lengthNorm(field),它的计算是1/sqrt(numTerms), 其中numTerms 表示的是分词的数量(如:告白气球分词为“告白”,“气球”,所以numTerms=2) 在实际中会发现计算出来的fieldNorm会和实际的结果有偏差,这里就不详细解释了,有兴趣可以参考下这篇文章
关于最后一项得分
其实就是bf参数,用函数来计算某个字段的权重,使用用户设置的公式来对文档的score进行计算。
到此为止,有关Solr的评分机制就已经介绍完了。
以上是关于Solr全文检索基本原理及评分机制的主要内容,如果未能解决你的问题,请参考以下文章