solr索引基本原理
Posted TECH flower
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了solr索引基本原理相关的知识,希望对你有一定的参考价值。
solr是一个全局检索引擎,能够快速地从大量的文本数据中选出你所需要的数据,而你只需要提供相应的关键词进行检索。solr的高效率查询靠的是底层强大的索引库,所以solr最关键的技术也是其底层的索引设计。solr工作的时候可以归结成两个过程:1.创建索引,2.搜索索引。
这是一张solr的基本工作图:
如图所示:
1.图中横线左边部分说明了solr中的数据来源,solr可以从数据库中获得数据,用户只需要简单的操作即可将数据库中的数据导入到solr中,除了数据库外solr可以从文件系统中保存数据,能直接保存互联网的数据,当然用户也可手动导入数据。
2.图中的index Documents就是前文所说的两个过程中的第一个创建索引,solr必须对导入的数据创建索引来保证查询的效率。
3.图上最底下有个index,表示一个索引库,索引库可以近似的看成是一个数据库,前面创建的索引必须保存在索引库中。
4.图中的横线上边右半部分表示了用户对solr的查询,用户通过各种方式对solr进行查询(如手动在solr管理页面上,通过solrj进行查询),查询到达solr后,solr进行search index(去索引库中对刚刚创建的索引进行检索)来找到用户想要得到的数据,并将数据集返回给用户。
solr索引
solr的索引类似如下图:
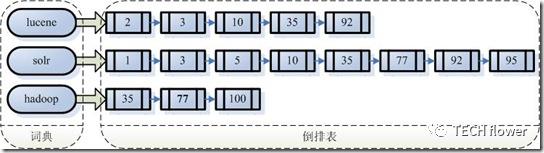
solr的索引是一个反向索引,比如说现在要找带solr这个词的数据,那么首先会在词典中找到solr这个词,在倒排表中会有一个链表与solr这个词关联着,这个链表就是带有solr这个词的文本集的序号集。
索引的创建过程
索引的创建过程可以分为:1.分词组件,2.语言处理组件,3.索引组件
1.分词组件:
当数据存入solr的时候首先会通过分词组件,分词组件的作用:
1.将数据分成一个个词汇,2.去除标点符号,3.去除停词(比如中文的“的”,“和”,“啦”等等)
比如存入“Students should be allowed to go out!”分词组件会先将句子分成多个单词“Students”,“should”,“be” ,“allowed”,“to”,“go”,“out”,“!”。随后会进行第二部将标点符号“!”去掉,最后第三步会将“to”,“be”去掉。最后留下的结果为:“Students”,“should”,“allowed”,“go”,“out”。
注意:可以看出我们在对solr进行搜索的时候应该尽量避免使用符号或者停顿词作为检索关键词。
2.语言处理组件:
语言处理组件的作用如下:
1.变为小写(Lowercase)。
2.将单词缩减为词根形式,如”cars”到”car”等。这种操作称为:stemming。
3.将单词转变为词根形式,如”drove”到”drive”等。这种操作称为:lemmatization。
注意:至此索引创建完成,搜索”drive”时,”driving”,”drove”,”driven”也能够被搜到。因为在索引中,”driving”,”drove”,”driven”都会经过语言处理而变成”drive”,在搜索时,如果您输入”driving”,输入的查询语句同样经过分词组件和语言处理组件处理的步骤,变为查询”drive”,从而可以搜索到想要的文档。Lowercase,stemming同理
3.索引组件
假设现在有两个文档:
文档一:Students should be allowed to go out with their friends, but not allowed to drink beer.
文档二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
经过前两个组件的处理后得到如下索引:
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2
jerry 2
go 2
school 2
see 2
his 2
student 2
find 2
them 2
drink 2
allow 2
对字典按字母顺序排序:
Term Document ID
allow 1
allow 1
allow 2
beer 1
drink 1
drink 2
find 2
friend 1
friend 2
go 1
go 2
his 2
jerry 2
my 2
school 2
see 2
student 1
student 2
their 1
them 2
合并相同的词(Term)成为文档倒排(Posting List)链表
Document Frequency:文档频次,表示多少文档出现过此词(Term)
Frequency:词频,表示某个文档中该词(Term)出现过几次
索引的检索
通过前几步索引的创建,现在就可以对创建的索引进行检索了。
当用户的检索关键词进入solr后,solr会对传入的关键词进行处理,具体处理过程类似创建索引时语言处理组件对文档词汇的处理过程。
将处理后的词在词典中搜索得到一个文档集。
将文档集根据词频将文档集进行相关性排序。
将结果集返回给用户。
以上是关于solr索引基本原理的主要内容,如果未能解决你的问题,请参考以下文章