干货 | 如何用Solr搭建大数据查询平台
Posted FreeBuf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 | 如何用Solr搭建大数据查询平台相关的知识,希望对你有一定的参考价值。
0x00 开头照例扯淡
自从各种脱裤门事件开始层出不穷,在下就学乖了,各个地方的密码全都改成不一样的,重要帐号的密码定期更换,生怕被人社出祖宗十八代的我,甚至开始用起了假名字,我给自己起一新网名”兴才”,这个看起来还不错的名字,其实是我们家乡骂人土话,意思是脑残人士…. -_-|||额好吧,反正是假的,不要在意这些细节。
好么,该来的终于还是来了,于是按名索骥,得知某某网站我用了这个名字,然后通过各种途径找,果然,那破站被脱裤子了。
果断Down了那个裤子,然后就一发不可收拾,走上了收藏裤子的不归路,直到有一天,我发现收藏已经非常丰富了,粗略估计得好几十亿条数据,拍脑袋一想,这不能光收藏啊,我也搭个社工库用吧……
0x01 介绍
社工库怎么搭呢,这种海量数据的东西,并不是简单的用mysql建个库,然后做个php查询select * from sgk where username like ‘%xxxxx%’这样就能完事的,也不是某些幼稚骚年想的随便找个4g内存,amd双核的破电脑就可以带起来的,上面这样的语句和系统配置,真要用于社工库查询,查一条记录恐怕得半小时。好在这个问题早就被一种叫做全文搜索引擎的东西解决了,更好的消息是,全文搜索引擎大部分都是开源的,不需要花钱。
目前网上已经搭建好的社工库,大部分是mysql+coreseek+php架构,coreseek基于sphinx,是一款优秀的全文搜索引擎,但缺点是比较轻量级,一旦数据量过数亿,就会有些力不从心,并且搭建集群做分布式性能并不理想,如果要考虑以后数据量越来越大的情况,还是得用其他方案,为此我使用了solr。
Solr的基础是著名的Lucene框架,基于java,通过jdbc接口可以导入各种数据库和各种格式的数据,非常适合开发企业级的海量数据搜索平台,并且提供完善的solr cloud集群功能,更重要的是,solr的数据查询完全基于http,可以通过简单的post参数,返回json,xml,php,python,ruby,csv等多种格式。
以前的solr,本质上是一组servlet,必须放进Tomcat才能运行,从solr5开始,它已经自带了jetty,配置的好,完全可以独立使用,并且应付大量并发请求,具体的架构我们后面会讲到,现在先来进行solr的安装配置。
0x02 安装和配置
以下是我整个搭建和测试过程所用的硬件和软件平台,本文所有内容均在此平台上完成:
软件配置: solr5.5,mysql5.7,jdk8,Tomcat8 Windows10/Ubuntu14.04 LTS
硬件配置: i7 4770k,16G DDR3,2T西数黑盘
2.1 mysql数据库
Mysql数据库的安装和配置我这里不再赘述,只提一点,对于社工库这种查询任务远远多于插入和更新的应用来说,最好还是使用MyISAM引擎。
搭建好数据库后,新建一个库,名为newsgk,然后创建一个表命名为b41sgk,结构如下:
id bigint 主键 自动增长
username varchar 用户名
email varchar 邮箱
password varchar 密码
salt varchar 密码中的盐或者第二密码
site varchar 数据库的来源站点
接下来就是把收集的各种裤子全部导入这个表了,这里推荐使用navicat,它可以支持各种格式的导入,具体过程相当的枯燥乏味,需要很多的耐心,这里就不再废话了,列位看官自己去搞就是了,目前我初步导入的数据量大约是10亿条。
2.2 Solr的搭建和配置
首先下载solr:

解压缩:

安装jdk8:

因为是java跨平台的,Windows下和linux下solr是同一个压缩包,windows下jdk的安装这里不再说明。
进入解压缩后的solr文件夹的bin目录,solr.cmd和solr分别是windows和linux下的启动脚本:
因为社工库是海量大数据,而jvm默认只使用512m的内存,这远远不够,所以我们需要修改,打开solr.in.sh文件,找到这一行:
SOLR_HEAP="512m"
依据你的数据量,把它修改成更高,我这里改成4G,改完保存. 在windows下略有不同,需要修改solr.in.cmd文件中的这一行:
set SOLR_JAVA_MEM=-Xms512m -Xmx512m
同样把两个512m都修改成4G。
Solr的启动,重启和停止命令分别是:

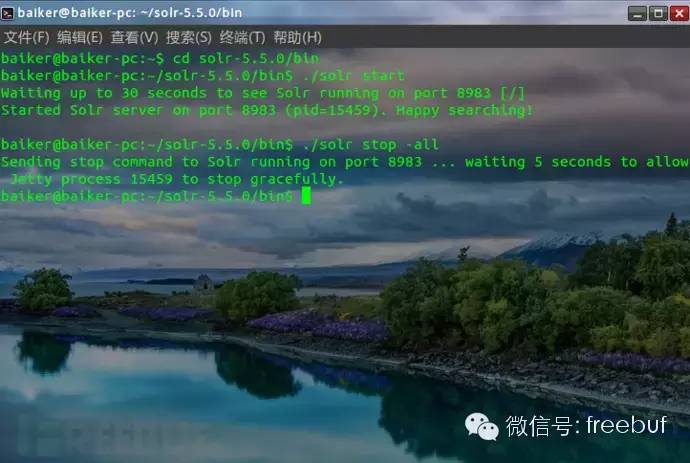
在linux下还可以通过install_solr_service.sh脚本把solr安装为服务,开机后台自动运行。
Solr安装完成,现在我们需要从mysql导入数据,导入前,我们需要先创建一个core,core是solr的特有概念,每个core是一个查询、数据,、索引等的集合体,你可以把它想象成一个独立数据库,我们创建一个新core:
在solr-5.5.0/server/solr子目录下面建立一个新文件夹,命名为solr_mysql,这个是core的名称,在下面创建两个子目录conf和data,把solr-5.5.0/solr-5.5.0/example/example-DIH/solr/db/conf下面的所有文件全部拷贝到我们创建的conf目录中.接下来的配置主要涉及到三个文件, solrconfig.xml, schema.xml和db-data-config.xml。
首先打开db-data-config.xml,修改为以下内容:
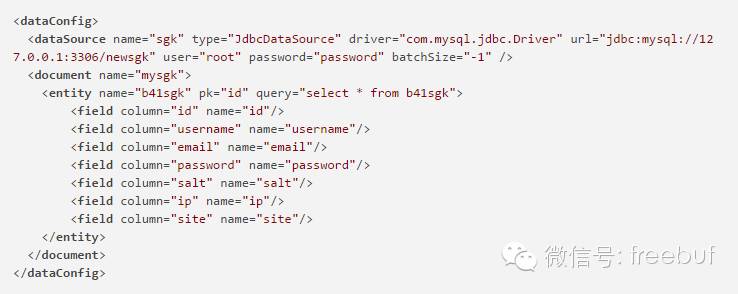
这个文件是负责配置导入数据源的,请按照mysql实际的设置修改datasource的内容,下面entity的内容必须严格按照mysql中社工库表的结构填写,列名要和数据库中的完全一样。
然后打开solrconfig.xml,先找到这一段:

把它全部注释掉,加上一行,改成这样:

这是因为solr5 以上默认使用managed-schema管理schema,需要更改为可以手动修改。
然后我们还需要关闭suggest,它提供搜索智能提示,在社工库中我们用不到这样的功能,重要的是,suggest会严重的拖慢solr的启动速度,在十几亿数据的情况下,开启suggest可能会导致solr启动加载core长达几个小时!
同样在solrconfig.xml中,找到这一段:

把这些全部删除,然后保存solrconfig.xml文件。
接下来把managed-schema拷贝一份,重命名为schema.xml (原文件不要删除),打开并找到以下位置:
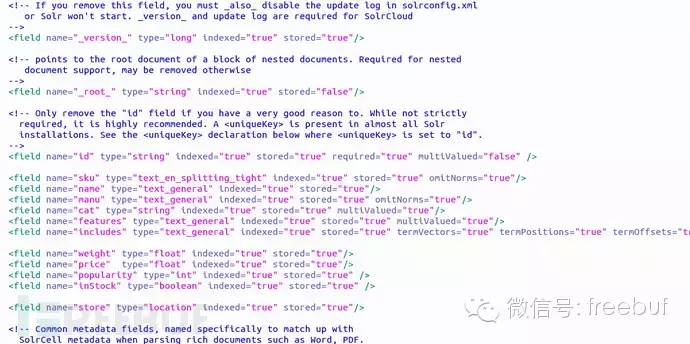
只保留_version_和_root_节点,然后把所有的field,dynamicField和copyField全部删除,添加以下的部分:

这里的uniqueKey是配置文件中原有的,用来指定索引字段,必须保留。新建了一个字段名为keyword,它的用途是联合查询,即当需要同时以多个字段做关键字查询时,可以用这一个字段名代替,增加查询效率,下面的copyField即用来指定复制哪些字段到keyword。注意keyword这样的字段,后面的multiValued属性必须为true。
username和email以及keyword这三个字段,用来检索查询关键字,它们的类型我们指定为text_ik,这是一个我们创造的类型,因为solr虽然内置中文分词,但效果并不好,我们需要添加IKAnalyzer中文分词引擎来查询中文。在https://github.com/EugenePig/ik-analyzer-solr5下载IKAnalyzer for solr5的源码包,然后使用Maven编译,得到一个文件IKAnalyzer-5.0.jar,把它放入solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib目录中,然后在solrconfig.xml的fieldType部分加入以下内容:

保存后,core的配置就算完成了,不过要导入mysql数据,我们还需要在mysql网站上下载mysql-connector-java-bin.jar库文件,连同solr-5.5.0/dist目录下面的solr-dataimporthandler-5.5.0.jar,solr-dataimporthandler-extras-5.5.0.jar两个文件,全部拷贝到solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib目录中,然后重启solr,就可以开始数据导入工作了。
2.3 数据导入
确保以上配置完全正确且solr已经运行,打开浏览器,访问http://localhost:8983/solr/#/ ,进入solr的管理页面,点击左侧Core Admin,然后Add Core:
name和instanceDir都填写前面我们命名的core名称solr_mysql,点击add core后,稍等片刻,core就建立完成了。此时在左边的下拉菜单选择创建的core,然后进一步选择Dataimport项,按照如下设置:
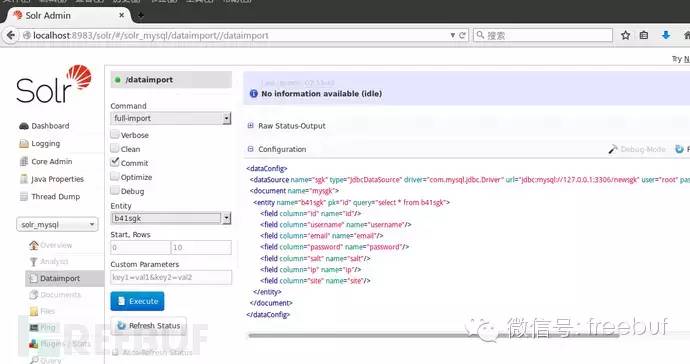
点击Execute,就会开始从mysql导入数据,选中Auto-Refresh Status会自动刷新进度,接下来就是漫长的等待……
导入完成后,我们就可以开始查询了,solr的查询全部使用post参数,比如:
http://localhost:8983/solr/solr_mysql/select?q=keyword:12345678&start=10&rows=100&wt=json&indent=true
因为前面已经建立了复合字段keyword,所以这里我们直接用keyword:12345678会自动查找username和email中包含12345678的所有结果,start=10&rows=100指定查询结果返回第11行到第110行的内容,因为solr采用的是分页查询,wt=json指定查询结果是json格式的,还可以是xml、php、python、ruby以及csv。
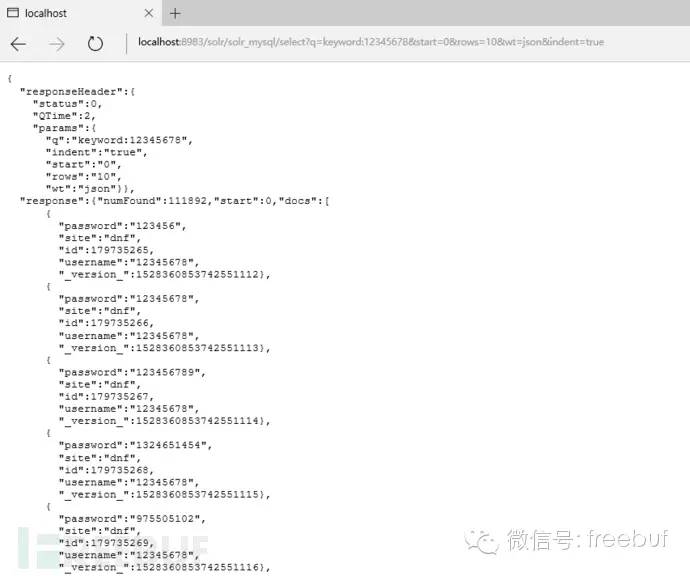
上图返回结果中的numfound:111892代表一共返回的结果数,不指定 start和rows的情况下默认只显示前十个结果。还需要注意IKAnalyzer引擎的几个问题,在以纯数字或者纯字母关键字查询时,IKAnalyzer会返回正确的结果,但在查询数字字母混合关键字时,需要在后面加*号,查询汉字时.默认会进行分词,即把一段关键字分成几个词查询,而社工库必须精确查询,所以汉字查询必须给关键字加双引号。
到这一步,如果只是搭建一个本地库,供自己使用,那么我们接下来只需写一个查询程序,post关键字,然后显示返回的结果即可,比如这样:
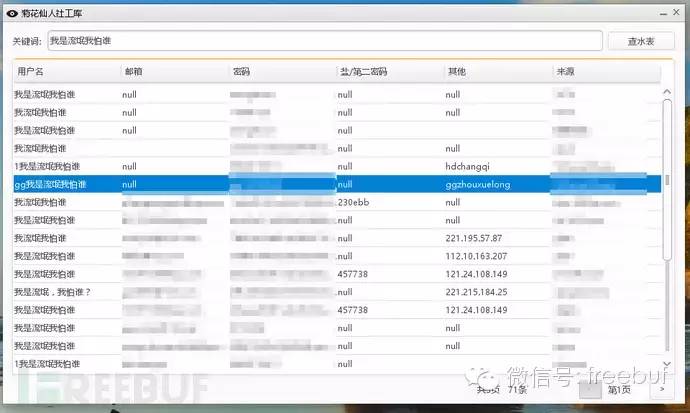
秒查,速度非常快,但如果要架设成服务器,提供给其他人使用,我们还有很多工作要做。
0x03 服务器架构和数据增量更新
尽管solr现在已经自带了jetty,jetty并不弱于tomcat,且没有后者那么臃肿,但是很多人在构建web应用时还是喜欢用以前的习惯,把solr整合进tomcat,然后和后台程序一锅乱炖,坦白说,在下并不喜欢这样的架构,对于大数据应用来说,各个功能组件各自独立,互相配合远比大杂烩要有效率和易于维护的多,所以,我理想中的社工库查询服务器,应该是以下的架构:
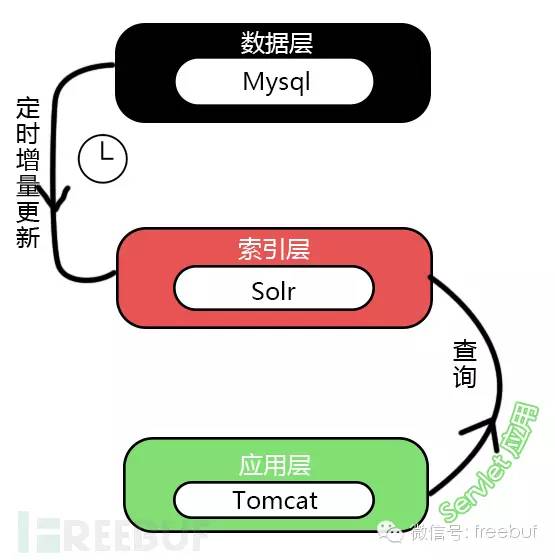
以上架构中,mysql只负责存储整理好的数据,并不提供查询服务,整理和导入新数据库时,只需操作mysql,solr利用自带的jetty独立运行,定期从mysql导入增量更新的数据,Tomcat作为应用服务器,运行提供查询的servlet应用,此应用通过http向solr post数据并获取结果,返回给前端页面,相互独立又相辅相成。
并且,solr并不依赖于mysql,它本身就是数据库可以独立运行,而社工库这种东西,并不是经常有新数据的,获取新数据的间隔可能很长,所以上面的定时增量更新可以改为手动增量更新,没有新数据时mysql完全可以关闭以节约资源。
那么我们先开始着手增量更新的设置,我们现在已有的数据表b41sgk并不动,在此基础上建立一个和b41sgk结构基本相同的表b41new,不同之处是增加了一个字段updatetime,用来自动存储添加数据的时间,以后的新数据全写入这个表,b41sgk不再做更新:
CREATE TABLE b41new (
id bigint NOT NULL auto_increment,
username varchar(255),
email varchar(255),
password varchar(255),
salt varchar(255),
ip varchar(255),
site varchar(255),
updatetime timestamp NOT NULL ON UPDATE CURRENT_TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY ('id')
)
用和前面同样的步骤建立一个core命名为solr_newsgk,在db-data-config.xml中做如下设置:
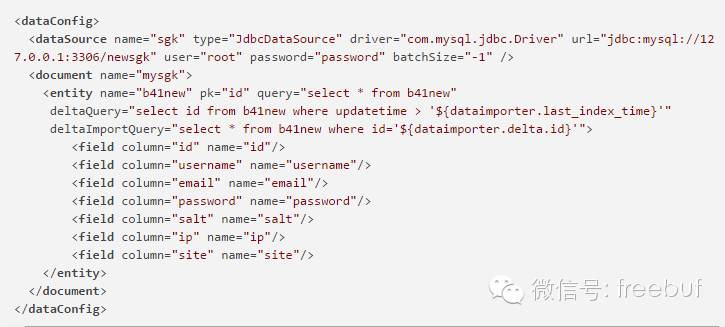
last_index_time和delta.id是两个自动变化的参数,分别记录最后一次导入数据的时间和已导入的最大id值,存储于当前core的conf目录下dataimporter.properties文件中,以上设置保存后,提交如下链接:
http://localhost:8983/solr/solr_newsgk/dataimport?command=delta-import&clean=false&commit=true
如果此时数据表b41new中已经添加了新数据,就会自动增量同步到solr中,如果要每天定时自动增量更新,执行:

增加一条:

保存后执行:

Solr就会在每天的零时自动增量导入数据,如果是windows系统,可以利用powershell和计划任务达到同样的目的。
现在我们的服务器搭建还剩下最后一件事:既然现在我们准备把solr查询提供给别人用,那么问题来了,我们只希望别人通过tomcat里的servlet查询,而不希望直接调用solr,我们需要屏蔽外部查询:


编辑/etc/network/interfaces,加入下面这行:
pre-up iptables-restore < /etc/iptables.up.rules
0x04 编写查询应用
Solr除了可以通过http post数据来查询之外,还提供了一套完整的api solrj,其实solrj底层还是通过http访问的,但如果你是用java开发,使用它会比直接http访问方便的多。
我们启动eclipse,配置好和tomcat的连接,新建一个项目sgk,在构建路径中添加solr-5.5.0/dist/solrj-lib下的全部jar包,然后添加solr-5.5.0/server/lib/ext中的log4j-1.2.17.jar,slf4j-api-1.7.7.jar,slf4j-log4j12-1.7.7.jar三个包。
在web.xml中添加如下设置:
新建一个servlet命名为searcher:
<查看更多代码,阅读原文>
0x05尾声
终于全都完成了,我在把狐朋狗友加基友加妹纸在社工库里查了个遍之后,心满意足的睡觉去了,梦中,我经过一条小河上的独木桥,刚走到桥正中,突然腰带一松,裤子掉进了河里,我正在发愁的时候,河面上冒出了一个猥琐的河神,手中拿着三件东西笑眯眯的问我:
“善良的少年哟! 你掉的,是这条金裤子,还是这条银裤子,还是这个装满了裤子的硬盘呢?”
“哈哈哈哈哈哈哈…..”
我对着河神哈哈大笑,笑着笑着,猛然从梦中醒来,睁眼一看,已经天光大亮了,回头看床头时钟,妈蛋! 上班要迟到了!!!.....
*作者b41k3r,本文属FreeBuf原创奖励计划,未经许可禁止转载
以上是关于干货 | 如何用Solr搭建大数据查询平台的主要内容,如果未能解决你的问题,请参考以下文章