《艳遇SOLR》8--倒排索引
Posted 金沙数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《艳遇SOLR》8--倒排索引相关的知识,希望对你有一定的参考价值。
倒排索引是整个搜索系统的核心,上一篇中讨论了关系型数据库不适合做全文检索。本文讨论讨论3个问题,我们常说的文档是指什么,正排索引是什么,倒排索引是什么。
1
文档(document)
如果拿数据库来比较的话,在数据库中一行数据代表一条完整的信息。solr是一个文档类型的存储和检索引擎,所以solr处理的每一条的数据都是一个文档(document),这个文档可以是一篇文章文章,一个简历,或者一整本书。
在数据库中,使用column来定义一列数据,同样在solr中使用field来定义具有相同属性的数据。一个文档可以有一个或者多个field。
数据库中,每一个column需要定义一个类型,number,varchar等。同样在solr中,这些field需要一个type:string ,tokenized text,Boolean,date/time,long等。solr需要知道如何去处理她收到的内容。
solr中一个文档的定义
solr和数据库做了一个对比,到此我们有些好奇,solr仍然需要定义field,定义field type,如何体现它的非结构化的索引与查询呢。
微观上看,搜索引擎仍然需要我们数据进行归类,抽取共同点来建索引。比如要给10w本电子书创建一个索引,需要剥离出书名,作者,出版年份,内容等。但从宏观上看,搜索引擎只是需要这些信息来创建索引,提供查询,而真正的内容或者说整个文档(document)仍然是以一个文件的形式存储在磁盘中的。
2
正排索引
部分内容摘自《走进搜索引擎》
假定存在文档docId=1 内容是“走进搜索引擎,学习搜索引擎”,分词结果为“走进/搜索引擎/学习/搜索引擎”。
得到如下索引结构
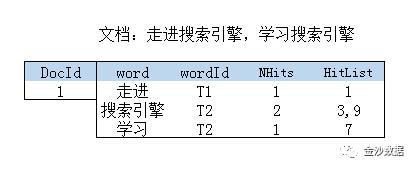
结论:正排索引是通过文档编号去查找索引词,找到对应的文档。全文检索是通过关键词来检索,所以正排索引不能满足全文检索的要求。
3
倒排索引
依然使用“buying a home” 的例子
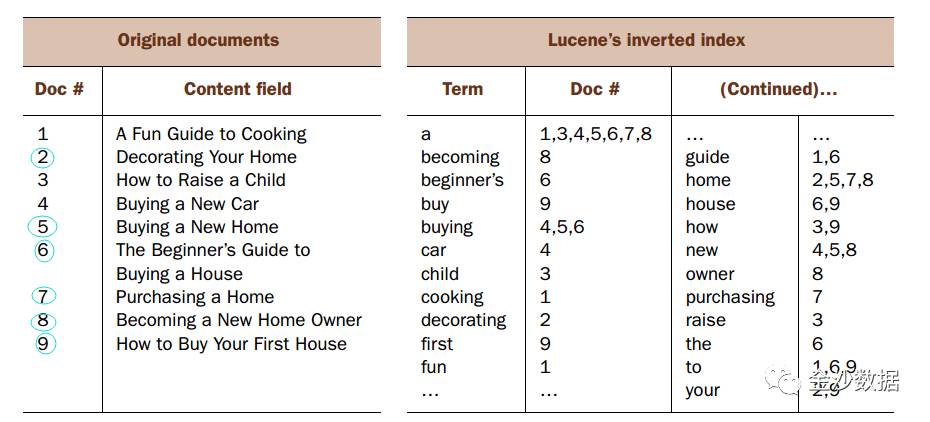
如果存在一个右边这样子的字典(字典里面会有一些处理,比如buy = buying,purchase = buy),在查找时找到这些词对应的文档编号,最后做并集运算,就可以查找出全部的文档。
这种以关键词和文档编号集合,键的索引结构称之为倒排索引
倒排索引分为两个部分
1)不同索引词(index term)组成的索引表,称为“词典”(lexicon),其中保存了各种词汇,以及这些词汇的统计信息(例如出现的频率),这些信息用于各种排名算法(Ranking Algorithm)[Salton 1989;witten 1994]
2)由每个索引词出现过的文档集合,以及命中位置等信息构成,也称为记录表(posting file)或者记录列表(posting list)。
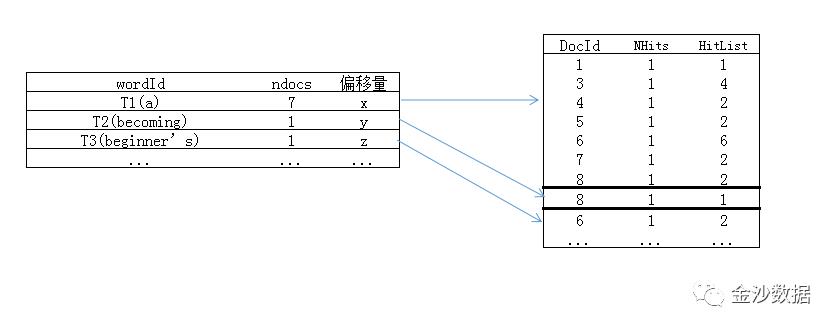
上例中的倒排索引表结构如下:
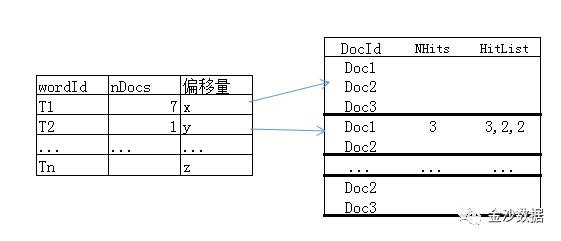
抽象如下:
名词解释
wordId:索引词ID号
nDocs:匹配该索引词的文档的数量
偏移量:文档在记录文件内的偏移量
docId:文档编号
NHits:某个索引词在文档中出现的次数
HitList:某个索引词在文档中出现的位置,即相对于正文的偏移量
总结:
正排索引可以理解成一个定义在文档空间到索引词组空间的一个映射,任意一个文档对应唯一的一组索引词
倒排索引可以理解成一个定义在索引词空间到文档组空间的一个映射,任意一个索引词对应唯一的一组该索引词命中的文档
所以顺着文档—>正排索引—>倒排索引这个过程可以实现一个索引词能通过倒排索引找到其命中的文档,以及位置信息即可实现全文检索
预告:solr是如何使用倒排索引进行索引和查询的
小王子:言语是误解的根源

今天的推送将会开启留言板的功能,说实话,这一个月来无数次的期待着,现在却很紧张。anyway,鲁迅爷爷曾经说过,真正的勇士敢于直面惨淡的人生,come on!
群
以上是关于《艳遇SOLR》8--倒排索引的主要内容,如果未能解决你的问题,请参考以下文章