Elasticsearch7.8.0版本进阶——倒排索引
Posted 小志的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch7.8.0版本进阶——倒排索引相关的知识,希望对你有一定的参考价值。
目录
一、Elasticsearch的概述
- Elasticsearch 使用一种称为 倒排索引的结构,它适用于快速的全文搜索。
二、正向索引
- 正向索引,就是搜索引擎会将待搜索的文件都对应一个文件 ID,搜索时将这个ID 和搜索关键字进行对应,形成 K-V 对,然后对关键字进行统计计数。
三、倒排索引
3.1、倒排索引的概述
- 倒排索引,就是把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。

- 一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文
档列表。
3.2、倒排索引的示例
-
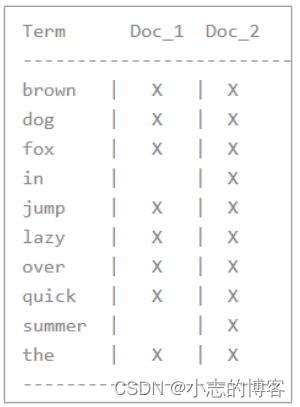
假设我们有两个文档,每个文档的 content 域包含如下内容:
The quick brown fox jumped over the lazy dog Quick brown foxes leap over lazy dogs in summer -
为了创建倒排索引,我们首先将每个文档的 content 域拆分成单独的 词(我们称它为 词条
或 tokens ),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文
档。结果如下所示:

-
如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:

-
由上图可知:两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单相似性算法,那么我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
3.3、上述示例中倒排索引的问题
3.3.1、上述示例中的倒排索引的一些问题
- Quick 和 quick 以独立的词条出现,然而用户可能认为它们是相同的词。
- fox 和 foxes 非常相似, 就像 dog 和 dogs ;他们有相同的词根。
- jumped 和 leap, 尽管没有相同的词根,但他们的意思很相近。他们是同义词。
3.3.2、上述示例需求
- 如果想使用前面的索引搜索 +Quick +fox 不会得到任何匹配文档。(+ 前缀表明这个词必须存在)。只有同时出现 Quick 和 fox 的文档才满足这个查询条件,但是第一个文档包含quick fox ,第二个文档包含 Quick foxes 。
3.3.3、上述示例需求的解决
-
将词条规范为标准模式,那么我们可以找到与用户搜索的词条不完全一致,但具有
足够相关性的文档。例如:
(1)、 Quick 可以小写化为 quick 。
(2)、 foxes 可以 词干提取 --变为词根的格式-- 为 fox 。类似的, dogs 可以为提取为 dog 。
(3)、jumped 和 leap 是同义词,可以索引为相同的单词 jump 。 -
现在索引看上去如下图所示:我们搜索 +Quick +fox 仍然 会失败,因为在我们的索引中,已经没有 Quick了。
-
如果我们对搜索的字符串使用与 content 域相同的标准化规则,会变成查询+quick +fox,这样两个文档都会匹配!分词和标准化的过程称为分析。但是只能搜索在索引中出现的词条,所以索引文本和查询字符串必须标准化为相同的格式。
以上是关于Elasticsearch7.8.0版本进阶——倒排索引的主要内容,如果未能解决你的问题,请参考以下文章