迭代速度慢?成熟的机器学习流如何设计:微博大规模机器学习框架Weiflow揭秘
Posted 高可用架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了迭代速度慢?成熟的机器学习流如何设计:微博大规模机器学习框架Weiflow揭秘相关的知识,希望对你有一定的参考价值。
本文从开发效率(易用性)、可扩展性、执行效率三个方面,介绍了微博机器学习框架 Weiflow 在微博的应用和最佳实践。
在机器学习流中,模型训练只是其中耗时最短的一环。如果把机器学习流比作烹饪,那么模型训练就是最后翻炒的过程;烹饪的大部分时间实际上都花在了食材、佐料的挑选,洗菜、择菜,食材再加工(切丁、切块、过油、预热)等步骤。
在微博的机器学习流中,原始样本生成、数据处理、特征工程、训练样本生成、模型后期的测试、评估等步骤所需要投入的时间和精力,占据了整个流程的 80% 之多。
如何能够高效地端到端进行机器学习流的开发,如何能够根据线上的反馈及时地选取高区分度特征,对模型进行优化,验证模型的有效性,加速模型迭代效率,满足线上的要求,都是我们需要解决的问题。
Weiflow 的诞生源自于微博机器学习流的业务需求,在微博的机器学习流图中(如图1所示),多种数据流(如发博流、曝光流、互动流)经过 Spark Streaming、Storm 的实时处理,存储至特征工程并生成离线的原始样本。
在离线系统,根据业务人员的开发经验,对原始样本进行各式各样的数据处理(统计、清洗、过滤、采样等)、特征处理、特征映射,从而生成可训练的训练样本;业务人员根据实际业务场景(排序、推荐),选择不同的算法模型(LR、GBDT、频繁项集、SVM、DNN 等),进行模型训练、预测、测试和评估;待模型迭代满足要求后,通过自动部署将模型文件和映射规则部署到线上。
线上系统根据模型文件和映射规则,从特征工程中拉取相关的特征值,并根据映射规则进行预处理,生成可用于预测的样本格式,进行线上的实时预测,最终将预测的结果(用户对微博内容的兴趣程度)输出,供线上服务调用。
Weiflow 的设计初衷就是将微博机器学习流的开发简单化、傻瓜化,让业务开发人员从纷繁复杂的数据处理、特征工程、模型工程中解脱出来。
开发人员可以将宝贵的时间和精力投入到业务场景的开发和优化当中,彻底解放业务人员的生产力,大幅提升开发效率。
考虑到微博业务场景越来越复杂、多样的趋势,Weiflow 在设计之初就充分考虑并权衡了框架的开发效率、可扩展性和执行效率。
Weiflow 通过统一格式的配置文件式开发(XML 流程文件),允许业务人员像搭积木一样灵活地将需要用到的模块(数据处理、特征映射、生成训练样本、模型的训练、预测、测试、评估等)堆叠到一起,根据依赖关系形成计算流图(Directed Acyclic Graph有向无环图),Weiflow 将自动解析不同模块之间的依赖关系,并调用每个模型的执行类进行流水线式的作业。
对于每一个计算模块,用户无需关心其内部实现、执行效率,只需关心与业务开发相关的参数调优,如算法的超参数、数据采样率、采样方式、特征映射规则、数据统计方式、数据清洗规则等等,从而大幅提升开发效率、模型迭代速度。
为了让更多的开发者(包括具有代码能力的业务人员)能够参与到 Weiflow 的开发中来,Weiflow 设计并提供了丰富的多层次抽象,基于预定义的基类和接口,允许开发者根据新的业务需求实现自己的处理模块(如新的算法模型训练、预测、评估模块)、计算函数(如复杂的特征计算公式、特征组合函数等),从而不断丰富、扩展 Weiflow 的功能。
在框架的执行效率方面,在第二层 DAG 中(后面将详细介绍 Weiflow 的双层 DAG 结构),充分利用各种计算引擎(Spark、Tensorflow、Hive、Storm、Flink 等)的优化机制,同时结合巧妙的数据结构设计与开发语言(如 Scala 的 Currying、Partial Functions 等)本身的特性,保证框架在提供足够的灵活性和近乎无限的可扩展性的基础上,尽可能地提升执行性能。
为了应对微博多样的计算环境(Spark、Tensorflow、Hive、Storm、Flink等),Weiflow 采用了双层的 DAG 任务流设计,如图 2 所示。

外层的 DAG 由不同的 node 构成,每一个 node 具备独立的执行环境,即上文提及的 Spark、Tensorflow、Hive、Storm、Flink 等计算引擎。外层 DAG 设计的初衷是让最合适的锤子去敲击最适合的钉子,大多数计算引擎因其设计阶段的历史局限性,都很难做到兼顾所有的工作负载类型,而是在不同程度上更好地支持某些负载(如批处理、流式实时处理、即时查询、分析型数据仓库、机器学习、图计算、交易型数据库等),因此我们的思路是让用户选择最适合自己业务负载的计算引擎。
内层的 DAG,根据计算引擎的不同,利用引擎的特性与优化机制,实现不同的抽象作为 DAG 中计算模块之间数据交互的载体。例如在 Spark node 中,我们会充分挖掘并利用 Spark 已有的优化策略和数据结构,如 Datasets、Dataframe、Tungsten、Whole Stage Code Generation,并将 Dataframe 作为 Spark node 内 DAG 数据流的载体。
在每一个 node 内部,根据其在 DAG 中上下游的位置,提供了三种操作类型的抽象,即Input、Process、Output。Input 基类定义了 Spark node 中输入数据的格式、读取和解析规范,用户可以根据 Spark 支持的数据源,创建各种格式的 Input,如图 2 中示例的 Parquet、Orc、Json、Text、CSV。当然用户也可以定义自己的输入格式,如图 2 中示例的 Libsvm。
在微博的机器学习模型训练中,有一部分场景是需要 Libsvm 格式数据作为训练样本,用户可以通过实现Input中定义的规范和接口,实现 Libsvm 格式数据的读入模块。通过 Input 读入的数据会被封装为Dataframe,传递给下游的 Process 类处理模块。
Process 基类定义了用户计算逻辑的通用规范和接口,通过实现 Process 基类中的函数,开发者可以灵活地实现自己的计算逻辑,如图 2 中示例的数据统计、清洗、过滤、组合、采样、转换等,与机器学习相关的模型训练、预测、测试等步骤,都可以在 Process 环节实现。通过 Process 处理的数据,依然被封装为 Dataframe,并传递给下游的 Output 类处理模块。
Output 类将 Process 类传递的数据进一步处理,如模型评估、输出数据存储、模型文件存储、输出 AUC 等,最终将结果以不同的方式(磁盘存储、屏幕打印等)输出。需要指出的是,凡是 Input 支持的数据读入格式,Output 都有对应的存储格式支持,从而形成逻辑上的闭环。
在使用方面,业务人员根据事先约定好的规范和格式,将双层 DAG 的计算逻辑定义在 XML 配置文件中。依据用户在 XML 指定的依赖关系和处理模块类,Weiflow 将自动生成 DAG 任务流图,并在运行时阶段调用处理模块的实现类来完成用户指定的任务流。
代码1展示了微博应用广泛的 GBDT+LR 模型训练流程的开发示例(由于篇幅有限,示例中只保留了第一个 node 的细节),代码 1 示例的训练流程所构成的双层 DAG 依赖及任务流图如图 3 所示。通过在 XML 配置文件中将所需计算模块按照依赖关系(外层的 node 依赖关系与内层的计算逻辑依赖关系)堆叠,即可以搭积木的方式完成配置化、模块化的流水线作业开发。
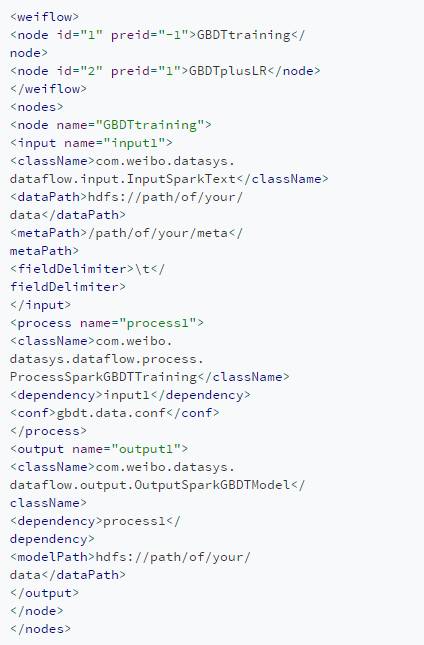
代码1 用Weiflow完成微博GBDT+LR模型训练流程

通过灵活的模块化开发,业务人员大幅提升了机器学习、数据科学作业的效率。随着微博的业务场景越来越复杂,业务需求也呈多样化的发展趋势,为了让更多的开发者灵活地扩展 Weiflow 的功能,Weiflow 在设计之初便充分考量了框架的可扩展性。Weiflow 通过多层次、模块化的抽象,提供近乎无限的扩展能力。
多层次的抽象是为了满足DAG外层计算引擎(上文提及的 Spark、Tensorflow、Hive、Storm、Flink等)的可扩展性,通过 Top level abstraction 提供的高度抽象定义,DAG 外层的各个计算引擎只需继承 Top level 抽象中定义的属性和方法,即可实现对计算引擎层面抽象的实现。
如图4所示,黑色文本框中的 Top level abstraction 提供了多个抽象 Base,蓝色文本框中不同的执行引擎通过继承其属性和方法,提供更加具体的抽象实现。当有新的计算引擎(如 Apache Flink)需要添加至 Weiflow 时,用户只需将新定义的计算引擎类继承 Top level 的抽象类,即可提供该引擎的抽象实现。
模块化的抽象是从业务处理的角度出发,从业务需求中抽象出基础、通用的模块概念,进而定义这些基本模块的基础属性和基础方法。如图 4 所示各文本框中分别定义、继承、实现了四大基础模块,即 Node、Input、Process 和 Output。
Node 基础类定义了计算引擎相关的基础属性,如数据流通媒介、执行环境、运行时数据流方式、运行参数抽象等。
Input 基础类为计算引擎定义了该引擎内支持的所有输入类型,如 Spark 引擎中支持 Parquet、Orc、Json、CSV、Text 等,并将输入类型转换为数据流通媒介(如 Spark 执行引擎的 Dataframe、RDD)。在 Weiflow 的实现过程中(后文将详细介绍 Weiflow 实现与优化的最佳实践),每个 node 内部的模块实现都充分利用了现有引擎的数据结构与优化机制,如在 Spark node 中,我们充分利用了 Spark 原生支持的功能(如对各种数据源的支持)和性能优化(如 Tungsten 优化机制、二进制数据结构、Whole Stage Code Generation 等)。
例如在 Input 基础类中,我们通过 Spark 原生数据源的支持,提供了多种压缩、纯文本格式的输入供用户选择。通过实现 Input 基础类中定义的对象和方法,开发者可以灵活地实现业务所需的数据格式,如前文提及的 Libsvm 格式。
Process 基础类囊括了所有业务处理逻辑,在实现方面,同样利用了所在引擎所提供的各种原生支持。如在 Spark node 中,通过 Spark SQL 或 Dataframe DSL(Domain Specific Language) 可以轻松地实现大部分处理逻辑,如数据统计、清洗、过滤、联接等操作。当开发者需要实现新的业务逻辑时,如对数据按比例进行向上、向下采样,只需继承 Process 基础类中定义的属性和方法,充分利用 Spark Dataframe 和 RDD 的开放 API,将采样的具体实现封装到既定的接口内,即可完成开发,进而扩展 Weiflow 功能,供业务人员使用。
与 Input 相对应,Output 基础类定义了 Weiflow 在计算引擎内的各种数据格式的输出,提供了与 Input 相对应的接口,如 Input 提供了 read 接口,Output 则提供了 write 接口,形成逻辑层面的闭环。
通过 Weiflow 多层次、模块化的抽象机制,开发者可以轻松地在执行引擎和业务功能方面进行扩展,从而满足不断变化的业务需求。前文提到,自 2016 年以来,微博业务步入了二次繁荣,微博的业务呈多样、复杂的发展趋势,用户、博文、互动相关的数据呈爆炸式增长,机器学习规模化的挑战迫在眉睫。为了满足微博机器学习规模化的需求,Weiflow 在设计之初就充分考虑到实现中的执行效率问题。

Weiflow 在实现方面分别从语言特性、数据结构、引擎优化等几个方面考虑,优化任务执行性能。考虑到 Scala 函数式编程语言的灵活性、丰富算子、超高的开发效率及其并发能力,Weiflow 框架的主干代码和 Spark node 部分业务实现都采用 Scala 来实现。
对于业务人员来说,XML 配置开发文件即是 Weiflow 的入口。Weiflow 通过 Scala 的 XML 内置模块对用户提供的 XML 文件进行解析并生成相应的数据结构,如 DAG node,模块间依赖关系等。
在成功解析各模块的依赖关系后,Weiflow 通过 Scala 语言的懒值特性和 Call By Name 机制,将依赖关系转化为 DAG 网络图,并通过调用 Output 实现类中提供的 Action 函数(Output.write),触发整个 DAG 网络的回溯执行。在回溯执行阶段,Weiflow 调取用户 XML 文件中提供的实现类,通过 Scala 语言提供的反射机制,在运行时生成实现类对象,完成计算逻辑的执行。
在执行效率方面,Weiflow 充分利用了 Scala 的语言特性来大幅提升整体执行性能。在微博的大部分机器学习应用场景中,需要利用各种处理函数(如log10、hash、特征组合、公式计算等)将原始特征映射到高维特征空间。
其中一部分复杂函数(如 pickcat,根据字符串列表反查字符串索引)需要多个输入参数。这类函数首先通过第一个参数,如 pickcat 函数所需的字符串列表(在规模化机器学习应用中会变得异常巨大),生成预定义的数据结构,然后通过第二个参数反查该数据结构,并返回其在数据结构中的索引。对于这样的需求,如果采用传统编程语言中的函数来实现,将带来巨大的计算开销。
处理函数被定义后,通过闭包发送到各执行节点(如 Spark 中的 Executor),在执行节点遍历数据时,该函数将每次执行读取第一个字符串列表参数、生成特定数据结构的任务;然后读取第二个字符串参数,反查数据结构并返回索引。但业务人员真正关心的是第二个参数所返回的索引值,无需每次遍历数据都运行生成数据结构的任务,因此该函数在执行节点的运行带来大量不必要的计算开销。然而通过 Scala 语言中的 Currying 特性,可以很容地解决上述问题。
在 Scala 中,函数为一等公民,且所有函数均为对象。通过将 pickcat 函数柯里化,将 pickcat 处理第一个参数的过程封装为另一个函数(pickcat_),然后将该函数通过闭包发送到执行节点,执行引擎在遍历数据时,其所见的函数 pickcat_ 将只接收一个参数,也即原函数 pickcat 的第二个参数,然后处理反查索引的计算即可。
当然,柯里化只是 Scala 函数式编程语言丰富的特性之一,其他特性诸如 Partial functions、Case class、Pattern matching、Function chain 等都被应用到了 Weiflow 的实现之中。
在数据结构的设计和选择上,Weiflow 的实现经历了从简单粗暴到精雕细琢的变迁。在 Weiflow 的初期版本中,因为当时还没有遇到规模化计算的挑战,出于开发效率的考虑,数据结构大量采用了不可变长数组,此时并未遇到任何性能瓶颈。但当 Weiflow 承载大规模计算时,执行性能几乎无法容忍。
经过排查发现,原因在于特征映射过程中,存在大量根据数据字典,反查数据值索引的需求,如上文提及的 pickcat 函数。面对千万级、亿级待检索数据,当数据字典以不可变长数组存储时,通过数据值反查索引的时间复杂度显而易见。后来通过调整数据字典结构,对多种数据结构进行对比、测试,最终将不可变长数组替换为 HashMap,解决了反查索引的性能问题。
在特征映射之后的生成 Libsvm 格式样本阶段中,也大量使用了数组数据结构,以稠密数组的方式实现了 Libsvm 数据值的存储。当特征空间维度上升到十亿、百亿级时,几乎无法正常完成生成样本的任务。通过仔细的分析业务场景发现,几乎所有的特征空间都是极其稀疏的,以 10 亿维的特征空间为例,其特征稀疏度通常都在千、万级别,将特征空间以稠密矩阵的方式存储和计算,无疑是巨大的浪费。最后通过将稠密矩阵替换为稀疏矩阵,解决了这一性能问题。
前文提到过,在 Weiflow 的双层 DAG 设计中,内存的 DAG 实现会充分地利用执行引擎已有的特性来提升执行性能。以 Spark 为例,在 Weiflow 的业务模块实现部分,充分利用了 Spark 的各种性能优化技巧,如 Map Partitions、Broadcast variables、Dataframe、Aggregate By Key、Filter and Coalesce、Data Salting 等。
经过多个方面的性能优化,Weiflow 在执行效率方面已经完全能够胜任微博机器学习规模化的需求,如表 1 中所示对比,Weiflow 优化后执行性能提升 6 倍以上。
表 1 中同时列举了 Weiflow 在开发效率、易用性、可扩展性方面的优势和提升。
本文从开发效率(易用性)、可扩展性、执行效率三个方面,介绍了微博机器学习框架 Weiflow 在微博的应用和最佳实践,希望能够对读者提供有益的参考。
作者简介:
吴磊,新浪微博算法平台高级工程师,主要负责以 Spark 为核心的大数据计算框架、机器学习平台的设计和实现。曾任职于IBM、联想研究院,从事数据库、数据仓库、大数据分析相关工作。
颜发才,新浪微博机器学习研发部门算法工程师,毕业于上海交通大学,为 Spark,Pandas,Scikit-learn 提交过代码贡献。
本文为《程序员》原创文章,经 CSDN 授权高可用架构发表。
推荐阅读
高可用架构
改变互联网的构建方式
以上是关于迭代速度慢?成熟的机器学习流如何设计:微博大规模机器学习框架Weiflow揭秘的主要内容,如果未能解决你的问题,请参考以下文章