IDL 871 机器学习框架
Posted ENVI技术殿堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IDL 871 机器学习框架相关的知识,希望对你有一定的参考价值。

IDL 8.7.1 带来了机器学习框架(IDL Machine Learning Framework)。IDL机器学习框架提供了一种强大而灵活的方式,能够将机器学习程序用于处理数字数据(Numerical Data)。 可以创建和训练模型并将其应用于分类、聚类或回归等分析。
友情提醒
本文将介绍IDL机器学习框架的基本概念和使用流程。
数据准备:如何准备数据用于机器学习;
分类:使用示例来训练一个模型,用于预测离散输出类别(只有有限数量的输出是可能的);
聚类:使用示例来训练一个模型,用于将数据集聚类到给定数目的群组或集群中;
回归:使用示例来训练一个模型,用于预测一个连续的输出值(有可能是无限多的输出值)。
-定义激活函数:激活函数对于神经网络至关重要,引入了非线性特征。
机器学习的第一步就是要定义输入数据。输入数据是一组数值属性,将其输入到模型中从而得到输出结果。在准备数据时有两个很重要的注意事项:
1) 数据归一化:机器学习算法在处理归一化数据时能够得到最好的结果,比如[0~1]、[-1~1]。可以使用归一化函数实现,例如:IDLmlLinearNormalizer, IDLmlRangeNormalizer,IDLmlTanHNormalizer,IDLmlUnitNormalizer,IDLmlVarianceNormalizer。将在下文示例中介绍。
2) 数据拆分:需要准备两组数据。一组用于训练模型,另一组用于验证精度。建议不要使用相同数据进行训练和验证。根据读取数据的方式,有两个程序可以帮助拆分数据:IDLmlShuffle 和IDLmlPartition。其中,IDLmlShuffle 可以打乱特征和值的顺序。IDLmlPartition可以将数据拆分为两个或多个组,每个组包含特定数量的元素。
为了说明这些步骤,首先需要读取一些数据:

注:read_seeds_example_data源码位于:
'…\IDL87\examples\machine_learning\read_seeds_example_data.pro'
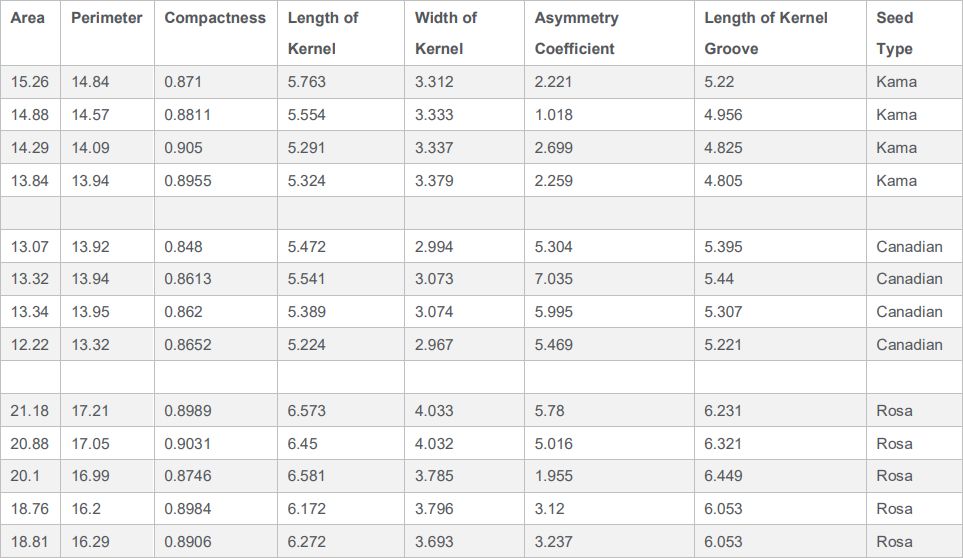
此程序通过读取一个CSV文件获取两个数组:特征(Features)和标签(Labels)。Features是一个7列210行的数组。每一列代表不同的属性(面积area、周长perimeter、紧密度compactness、长度length、宽度width、偏度系数asymmetry coefficient、谷纹长度length of kernel groove),210行表示有210个实例。Labels是含有210个元素的字符串数组,存储了种子类型(可能是Kama、Rosa或Canadian)。
下方展示了部分Features和Labels数组的值:
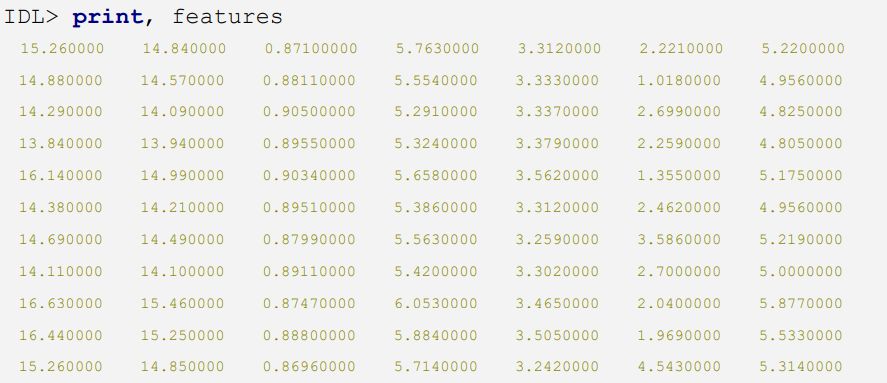
下方展示了Features数组前10行的内容:
下面的步骤将为分类示例准备数据,分类示例将在下个章节介绍。
首先将数据进行归一化处理:

然后打乱数据,并将其拆分为两个组。其中一组包含80%的样本,用于训练;另一组包含20%的样本,用于验证。

下面的变量是已经准备好的数据:
part.train.features: 一个7列168行的features数组,用于训练;
part.train.labels: 一个包含168个字符串元素的labels数组,用于训练;
part.test.features: 一个7列42行的features数组,用于验证;
part.test.labels: 一个包含42个字符串元素的labels数组,用于验证。
IDL提供了3种分类模型:
IDLmlFeedForwardNeuralNetwork
IDLmlSoftmax
IDLmlSupportVectorMachineClassification
下面展示一个使用Support Vector Machine模型的示例。
在加载和准备数据后,下一步需要定义一个分类器(classifier)。根据准备的数据可以知道:包含了7个输入属性和3种可能的字符串输出结果,所以定义分类器模型如下:

接下来训练模型。调用模型的Train方法,并传入训练features和labels即可:
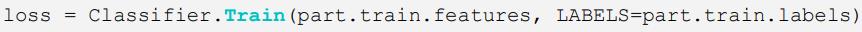
请注意SVM是唯一一个只需要调用一次Train方法的模型。其他分类器需要在循环中迭代训练。例如Softmax分类器:

在循环中可以检查损失值。当它稳定在尽可能低的值时,说明模型已经得到了充分的训练。
为了评估训练的分类模型质量,需要将验证样本传入另一个函数:IDLmlTestClassifier。此函数将返回一系列描述模型精度的指标。

结果是0.928571,表示利用样本数据得到的分类精度是92.8%(每次运行结果会有偏差,因为在拆分数据前是随机打乱的状态)。
现在模型已经训练完毕,可以用于分类了。下方代码是将验证样本中的第一个实例进行分类。

可以将训练好的模型保存为文件,之后可以导入继续使用,而不需要重新训练。同时,归一化模型也可以保存为文件。

使用下方的代码可以导入分类模型和归一化模型:

IDL提供了2种聚类模型:
IDLmlAutoEncoder
IDLmlKMeans
本节提供一个简单示例,介绍如何使用自动编码器(AutoEncoder)来执行分类。AutoEncoder是神经网络的一种,专门用于学习数据表达,可以将数据集分组或聚类到小类别中。
使用一个小的JPEG文件作为示例,基于RGB像素值将其聚类到5个不同类别中。
首先读取图像:

IDL机器学习算法的输入数据要求是2D数组,维度为n×m,n表示属性个数,m表示实例数。本例中有3个属性(即R、G、B三个波段的像素值),实例数即像元个数。输入数据原始维度为3×227×149,需要将其转换为3×33823的格式,代码如下:
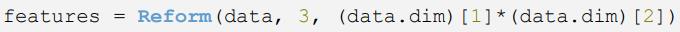
然后需要将数据进行归一化处理。可以使用任意一个归一化模型,这里使用IDLmlVarianceNormalizer,代码如下:

现在定义AutoEncoder。本例中使用2层。因为有3个属性,所以第1 个和最后一个大小必须为3。为了聚类为5个类别,中间大小为5。代码如下:

注:可以通过为每层定义激活函数(Activation Function)来微调AutoEncoder。可以查看下文“定义激活函数”章节内容获取更多信息。
现在可以训练模型了。在训练过程中,AutoEncoder将学习如何基于特征来处理输入图像。这些内部特征最终有效地转换为聚类图像。代码如下:

注:训练神经网络需要使用优化器(Optimizer)。优化器可以帮助神经网络调整训练过程中的学习速率,即模型收敛到解的速度。优化器包含: IDLmloptAdam、IDLmloptGradientDescent、IDLmloptMomentum、IDLmloptQuickProp和 IDLmloptRMSProp。
提示:一个优化器不能被用来重复训练不同的模型。
为了获取聚类图像,对输入数据进行分类。代码如下:

显示原始图像和聚类结果。聚类结果需要转换为原始二维数组(列×行),并使用索引色将其显示为彩色图。代码如下:

效果如下:

IDL提供了3种回归模型:
IDLmlFeedForwardNeuralNetwork
IDLmlSoftmax
IDLmlSupportVectorMachineRegression
本章节提供一个简单示例,展示如何使用前馈神经网络(Feed Forward Neural Network)模型。
首先,定义两个属性数组(xx和yy),以及一个特定形状(zz),供模型学习。代码如下:

注:xx、yy、zz都是100×100的二维数组。
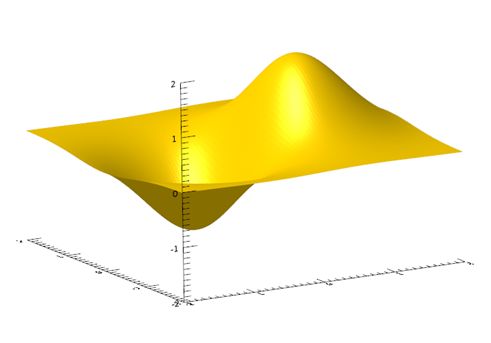
IDL机器学习算法的输入数据要求是2D数组,维度为n×m,n表示属性个数,m表示实例数。在本例中,属性个数为2(即xx和yy),实例数是数组中的元素个数。将xx和yy数组合并为1个二维数组,代码如下:
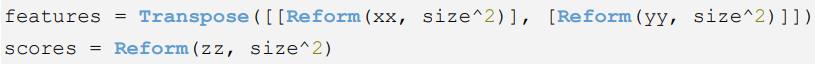
注:features变为2×10000的二维数组。第一列为xx,第二列为yy。scores变为10000个元素的向量。
现在随机打乱数据,并拆分为两组:一组用于训练,另一组用于验证。保证两组数据各占50%,代码如下:

然后需要将数据进行归一化处理。可以使用任意一个归一化模型,这里使用IDLmlVarianceNormalizer,代码如下:

将相同处理用于模型输出项。与分类不同(有限且固定的输出),回归的输出是连续的,所以保持归一化(规范化)很重要。

现在定义神经网络,并设置层数。本例使用3层。因为有2个属性,所以第一层大小为2。对于回归问题,最后一层大小为1,因为不需要分为不同的类别。

激活函数(Activation Functions)对于机器学习非常重要。激活函数将非线性特性引入到神经网络中,从而可以建模更复杂的函数。而如果没有激活函数,神经网络仅仅是一个线性系统。IDL中提供的激活函数如下所示:
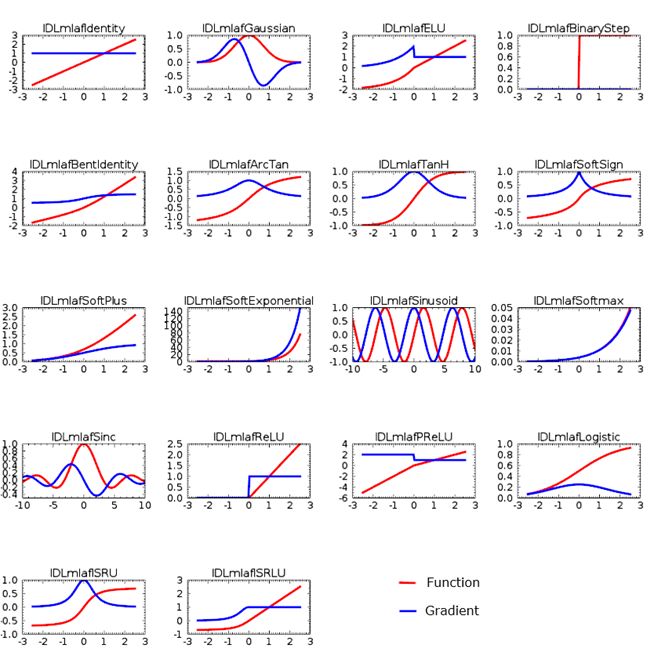
为每层选择合适的激活函数对于神经网络的准确度是至关重要的。但是指导意见很少,所以在大多数情况下可以考虑试错法。
下面开始训练模型:

注:训练神经网络需要使用优化器(Optimizer)。优化器可以帮助神经网络调整训练过程中的学习速率,即模型收敛到解的速度。优化器包含: IDLmloptAdam、IDLmloptGradientDescent、IDLmloptMomentum、IDLmloptQuickProp和 IDLmloptRMSProp。
提示:一个优化器不能被用来重复训练不同的模型。
现在将整个xx、yy数据集传入模型,并查看输出结果与它尝试学习的数据之间的相似程度。代码如下:

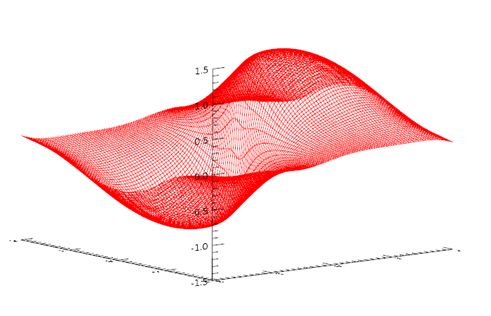
同样可以调用Evaluate方法,利用验证数据来评估模型的准确度。LOSS关键字返回的结果就是计算结果与真实值之间的均方根误差(RMSE,root mean square error)。代码如下:

loss输出结果是0.0981930。
可以将训练好的模型保存为文件,之后可以导入继续使用,而不需要重新训练。同时,归一化模型也可以保存为文件。

使用下方的代码可以导入机器学习模型和归一化模型:
更多IDL机器学习帮助请查看IDL帮助如下章节内容:
IDL Help > Routines (by topic) > Machine Learning
以上是关于IDL 871 机器学习框架的主要内容,如果未能解决你的问题,请参考以下文章
机器学习太棒了!8 个开源自动化机器学习框架,轻松搞定机器学习!