Julia推出新机器学习框架MLJ,号称超越机器学习pipeline
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Julia推出新机器学习框架MLJ,号称超越机器学习pipeline相关的知识,希望对你有一定的参考价值。
新智元报道
新智元报道
来源:Julia
编辑:元子
【新智元导读】Julia新推出了完全用Julia写成的机器学习框架MLJ,团队希望将其打造成一个灵活的、用于组合和调整机器学习模型、具备高性能、快速开发的框架。
Julia新推出了一个超高纯度的机器学习框架MLJ,团队希望把MLJ打造成一个灵活的、用于组合和调整机器学习模型、具备高性能、快速开发的框架。Julia团队之所以推出MLJ,部分原因也是受到MLR的影响。
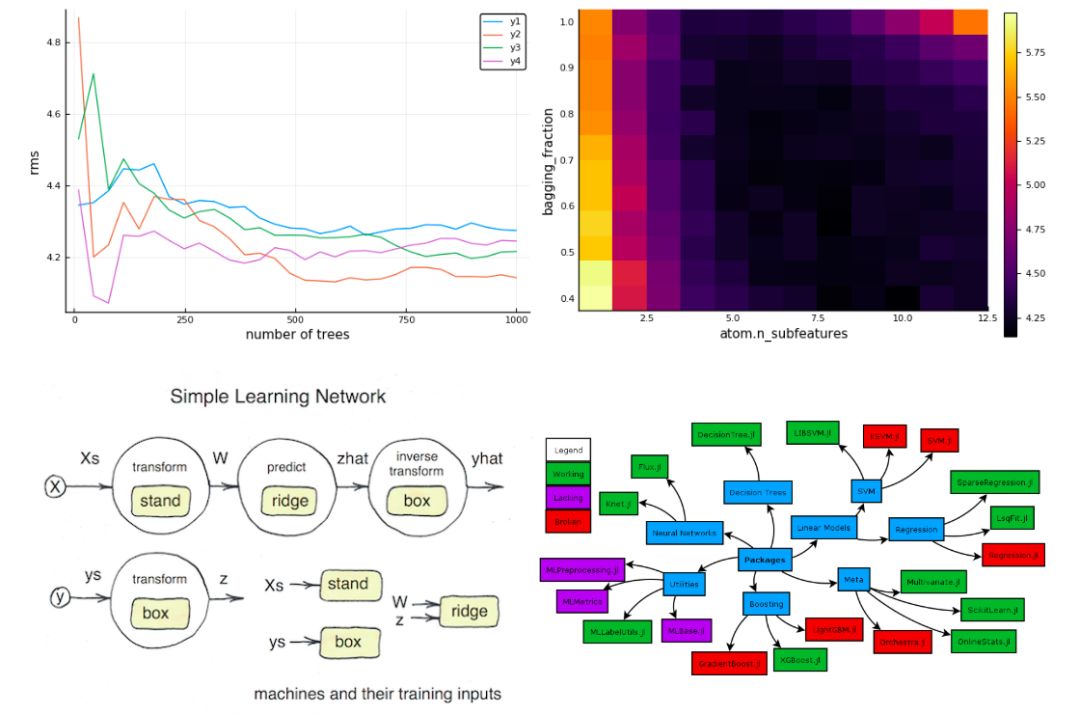
所以MLJ纯度有多高呢?它是完全用Julia写的开源机器学习工具箱,提供了统一的界面,用于和目前分散在不同Julia软件包中的有监督、无监督学习模型进行交互。
MLJ目前已具备以下特性:
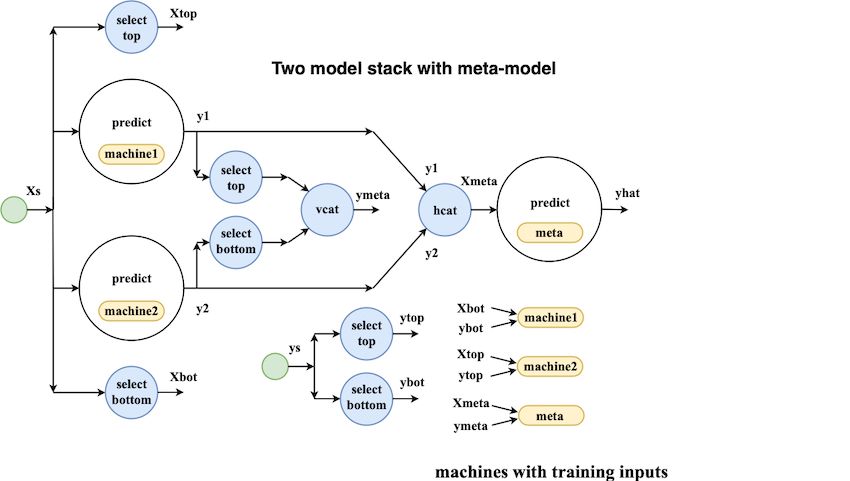
Learning networks:超越传统Pipeline的灵活模型组合
自动调参。自动调整超参数,包括复合模型。调整实现为与其他元算法组合的模型包装器
同质模型集成
模型元数据的注册表。无需加载模型代码元数据即可用。“任务”界面的基础并促进模型组合
任务界面。自动将模型与指定的学习任务相匹配,以简化基准测试和模型选择
清爽的概率接口。改进了对贝叶斯统计和概率图形模型的支持
数据容器不可知。以用户自己喜欢的Tables.jl格式显示和操作数据
普遍采用分类数据类型。使模型实现能够正确地考虑训练中看到的类而不是评估中的类
团队还计划在不久的将来继续增强特性,包括Flux.jl深度学习模型的集成,以及使用自动微分的连续超参数的梯度下降调整。
scikit-learn是一个非常强大的机器学习Python库,基本包含了所有机器学习的方式,涵盖了数据预处理到训练模型的各个方面,可以极大的节省代码量。Julia已经有了一个很棒的机器学习工具箱ScitkitLearn.jl,为Julia用户提供了对成熟且庞大的机器学习模型库的访问,那为什么我要抛弃ScitkitLearn.jl用MLJ呢?
MLJ纯
ScitkitLearn.jl最初是用作流行的python库scikit-learn的Julia包装器,对要求性能的例程又封装了C代码元算法仍然是python代码,纯度太低,而MLJ则完全用Julia实现,速度可以与C媲美。
同时,这种单一语言的设计提供了卓越的互操作性。例如,可以使用自动微分库(例如Flux.jl)实现:(i)超参数的梯度下降调整; (ii)使用CuArrays.jl,GPU性能提升而无需重大代码重构。
模型元数据的注册表
在ScikitLearn.jl中,必须从文档中收集可用模型的列表,以及模型元数据(模型是否处理分类输入,是否可以进行概率预测等)。在MLJ中,这些信息更加结构化,MLJ可通过外部模型注册表访问(无需加载模型)。这形成了“任务”界面的基础,并促进了模型组合。
任务界面
一旦MLJ用户指定“任务”(例如,“基于特征x,y,z进行房屋价值的概率预测”),MLJ就可以自动搜索、匹配该任务的模型,从而协助系统基准测试和模型选择。
灵活的API
scikit-learn中的Pipeline更像是一种亡羊补牢的做法。相比之下,MLJ的用户交互API基于灵活的“learning network”API的要求,该API允许模型以基本上任意的方式连接(包括目标变换和逆变换)。在作为独立模型导出之前,可以分阶段构建和测试网络。
网络具有“智能”训练,即在参数更改后仅重新训练必要的组件;并且最终将使用DAG调度程序进行训练。在Julia的元编程功能的帮助下,构建通用架构(如线性pipeline和堆栈)将是单线操作。
清爽的概率API
scikit-learn API没有为概率预测的形式指定通用标准。通过沿着skpro项目的路线修复概率API,MLJ旨在改进对贝叶斯统计和概率图形模型的支持。
普遍采用分类数据类型
Python的科学数组库NumPy没有用于表示分类数据的专用数据类型,即没有跟踪所有可能类的池的类型。scikit-learn模型的解决之道是将数据重新标记为整数。
Julia团队宣称当用户在重新标记的分类数据上训练模型之后,由于分类特征出现了在训练中未观察到的值,导致代码崩溃。而MLJ则通过坚持使用分类数据类型,并坚持MLJ模型实现保留类池来缓解此类问题。例如,如果训练目标包含池中实际上不出现在训练集中的类,则概率预测将预测其支持包括缺失类但但是以概率零适当加权的分布。
https://github.com/alan-turing-institute/MLJ.jl
不过最近因为Github遭遇黑客攻击,访问过程可能会出现一些小问题。
下面是一些相关的资源链接:
通过一些示例代码来对MLJ有一个大致印象:
https://github.com/alan-turing-institute/MLJ.jl/blob/master/docs/src/tour.ipynb
视频介绍,demo在21’39’’:
https://www.youtube.com/watch?v=CfHkjNmj1eE
构建一个自动调参的随机森林:
https://github.com/alan-turing-institute/MLJ.jl/blob/master/examples/random_forest.ipynb
一个dacker镜像:
https://github.com/ysimillides/mlj-docker
为新模型实现一个MLJ界面:
https://alan-turing-institute.github.io/MLJ.jl/dev/adding_models_for_general_use/
Slack频道:#mlj
http://julialang.slack.com/
为项目贡献青春:
https://github.com/alan-turing-institute/MLJ.jl/blob/master/CONTRIBUTE.md
新智元春季招聘开启,一起弄潮 AI 之巅!
岗位详情请戳:
【加入社群】
以上是关于Julia推出新机器学习框架MLJ,号称超越机器学习pipeline的主要内容,如果未能解决你的问题,请参考以下文章
机器学习研究趋势分析:TensorFlow已超越Caffe成研究最常用框架
学界 | 机器学习研究趋势分析:TensorFlow已超越Caffe成研究最常用框架