再谈Spark Streaming Kafka反压
Posted data之道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了再谈Spark Streaming Kafka反压相关的知识,希望对你有一定的参考价值。
0x01 前言
上篇文章介绍了Spark Streaming的基本内容及和kafka的集成,其中也提到了开启反压的缘由:一个批次的数据应该在一个批次内处理完,即batch process time应该接近于batch Duration,如果batch处理时间总是比batch间隔时间长,就会不断增加调度延迟时间而且数据也会在内存里堆积,进而增加系统不稳定性;另一方面,如果batch处理时间总是远远小于batch间隔时间,则集群资源利用率不高,也是一种资源浪费。
控制批处理时间的关键在batch接收的数据量和业务逻辑处理复杂度,往往前者起了决定性作用,反压机制就可以动态控制batch接收消息速率,来适配集群处理能力。
0x02 速率预估
启用反压也比较简单:sparkConf.set("spark.streaming.backpressure.enabled", "true") 。spark会在作业执行结束后,调用RateController.onBatchCompleted更新batch的元数据信息:batch处理结束时间、batch处理时间、调度延迟时间、batch接收到的消息量等.
然后基于上述参数,使用PID估计算法预估速率,具体实现是PIDRateEstimator的compute方法。
0x03 Kafka限流实现
从上篇文章已经了解到,Spark Streaming是先从broker里查询到每个分区的latestOffset,这样就可以得到每个分区的offset range,再用range和上一步预估的速率做对比计算就可以确定每个分区的处理的消息量。整个计算步骤:
1、offset range的消息量 totalLag
2、有效速率=取设置的maxRatePerPartition和预估的速率最小值
3、一个batch的每个分区每秒接收到的消息量=batchDuration*有效速率
主要代码见下:
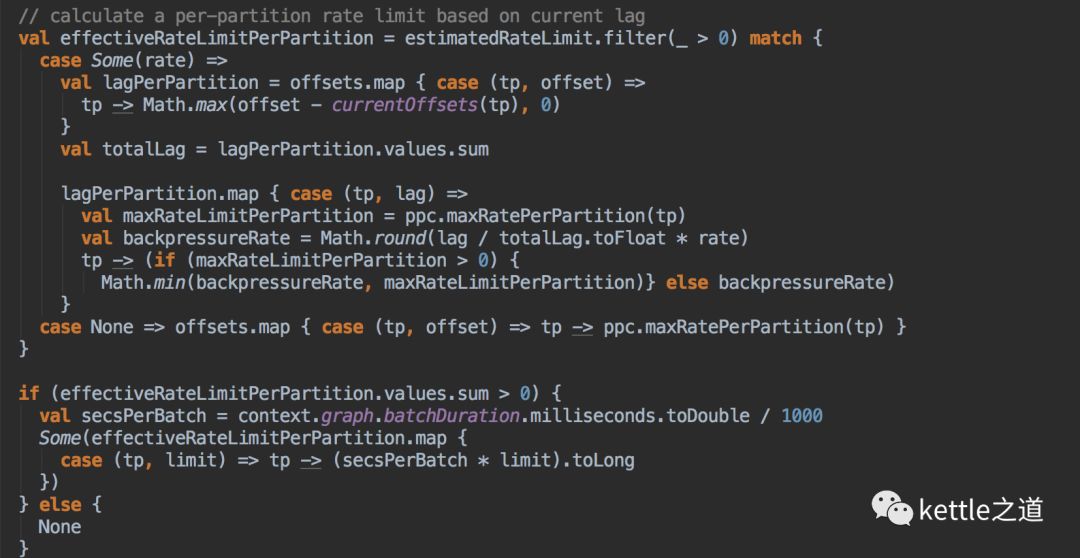
spark.streaming.kafka.maxRatePerPartition控制spark读取的每个分区最大消息数。从上面的分析过程可以预见到,每个分区接收到的消息量<=batchDuration * spark.streaming.kafka.maxRatePerPartition.
以下两种场景需要启用反压,可以有效防止应用程序过载:
1、首次启动Streaming应用,kafka保留了大量未消费历史消息,并且auto.offset.reset=latest,可以防止第一个batch接收大量消息、处理时间过长和内存溢出
2、防止kafka producer突然生产大量消息,一个batch接收到大量数据,导致batch之间接收到的数据倾斜
0x04 走过的弯路
在之前没有用Streaming自身的反压机制,但又要限制处理的每个分区消息量,就自己实现了类似的限流机制,实现思想也很简单,增加一个spark.streaming.kafka.maxPollCount参数,表示batch接收到的每个分区最大消息数,然后再spark取topic partition的last position时,和这个值做比较,如消息量大于maxPollCount,就把last position设置为current position + maxPollCount。实现代码:
这种方式相较spark的反压,简单粗暴,接收的最大消息量是一成不变的,和batch处理时间、batch延迟调度时间等没有相关性,但是其他因素是动态的,这就会出现性能瓶颈:
1、消息的大小等消息特性会随着时间推移而改变,导致同一数量的消息处理时间不尽相同
2、集群服务器的资源(cpu/内存/io...)在不同时间的负载也不一样
以上是关于再谈Spark Streaming Kafka反压的主要内容,如果未能解决你的问题,请参考以下文章
面试题:Flink反压机制及与Spark Streaming的区别
面试题:Flink反压机制及与Spark Streaming的区别
Spark 系列(十六)—— Spark Streaming 整合 Kafka