Kafka进阶
Posted 码上攻城
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka进阶相关的知识,希望对你有一定的参考价值。
内容为将要在公司分享Kafka的PPT,推荐在wifi环境下阅读
本次分享内容包括
1.Message delivery guarantee 分场景进行可能性的描述
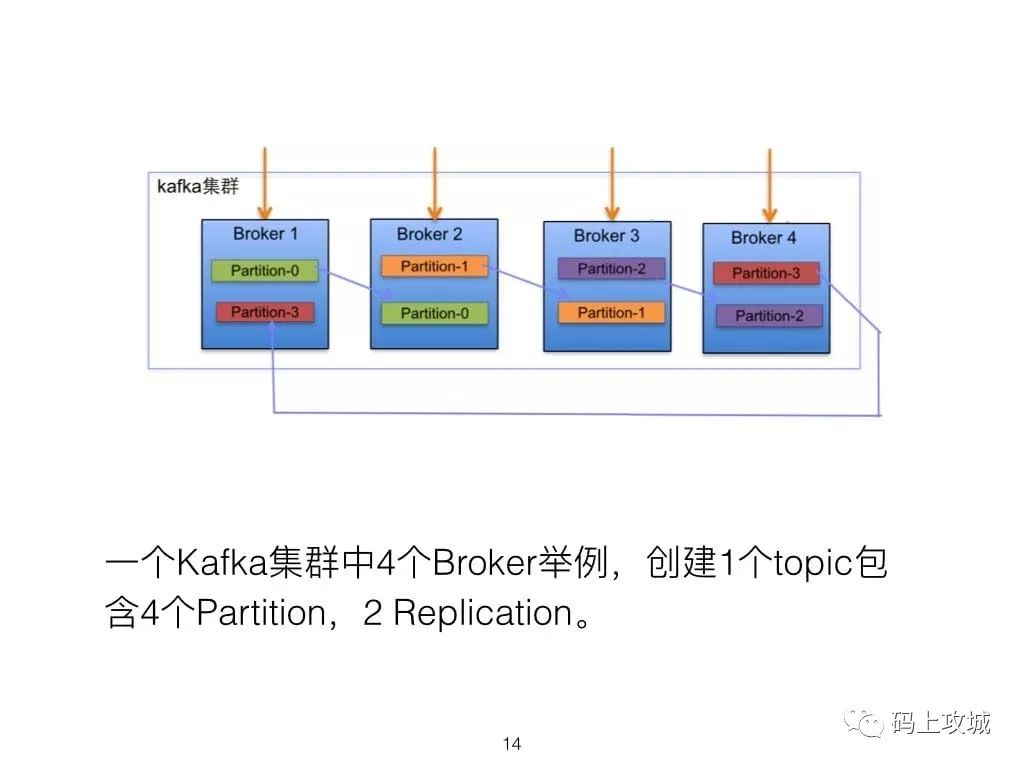
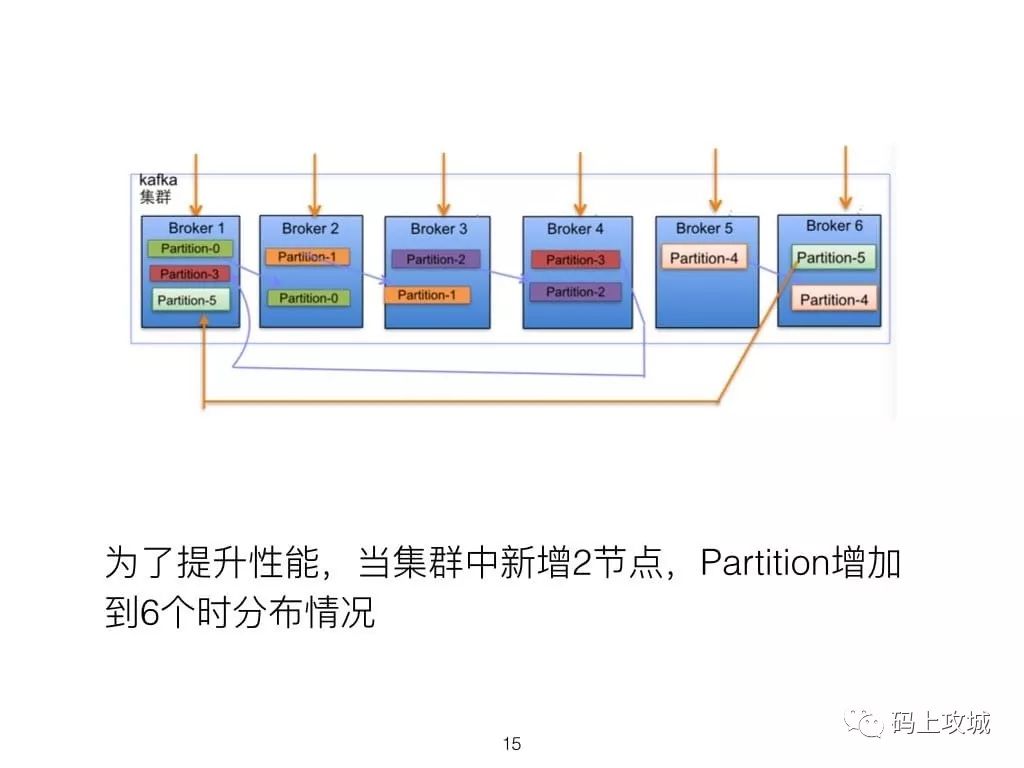
2.Partition的重要性及在什么情况下会Rebalance
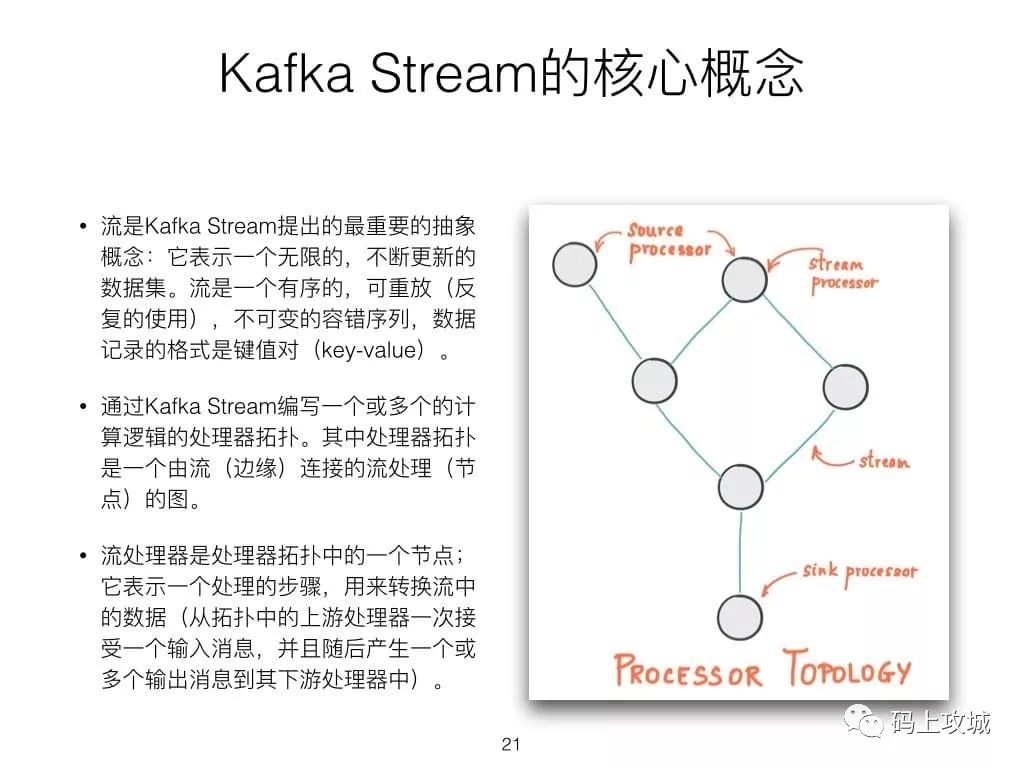
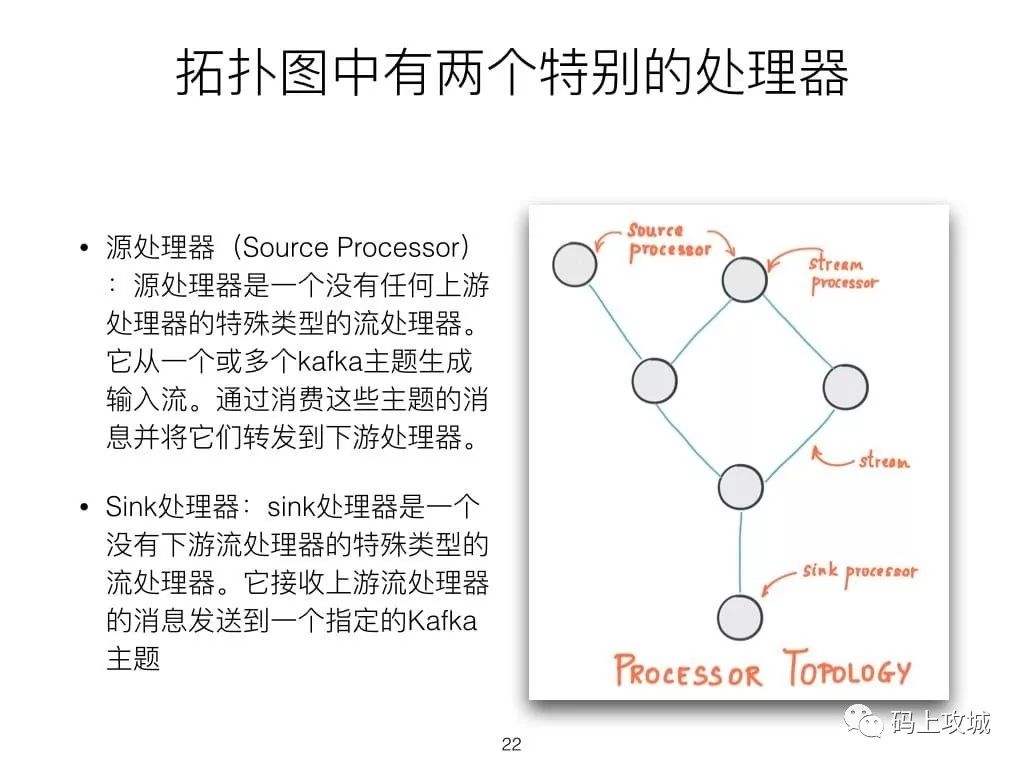
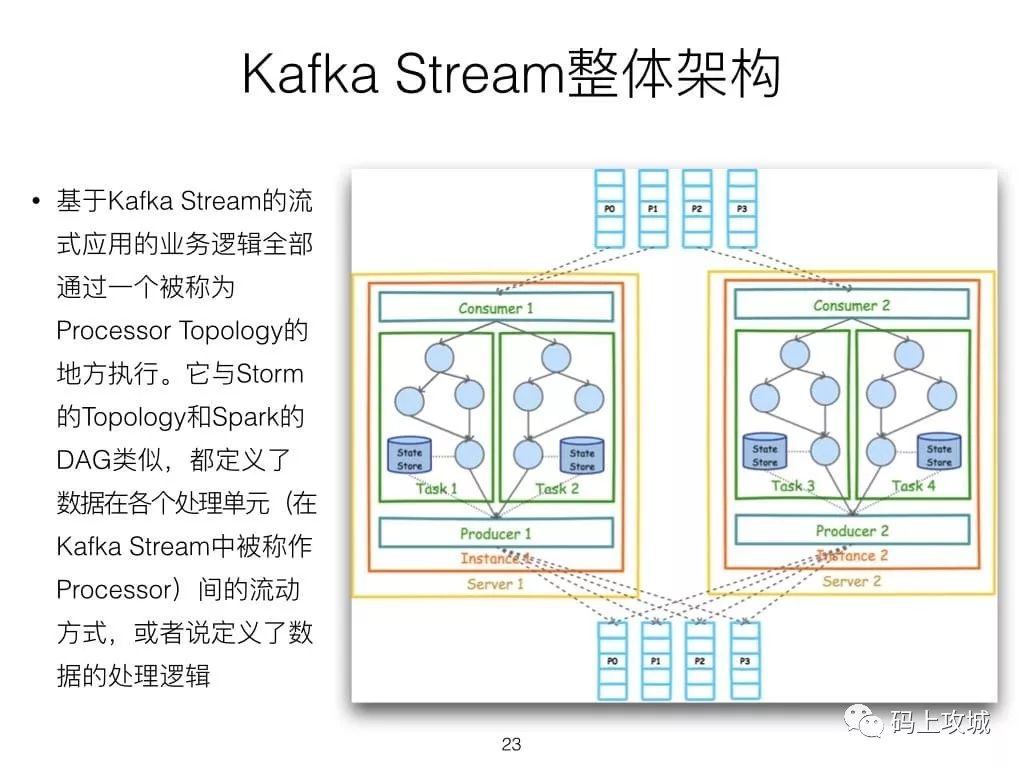
3.Kafka Stream介绍
4.运行一下Kafka Stream WordCount的demo
Kafka Stream 的优势
第一,Spark和Storm都是流式处理框架,而Kafka Stream提供的是一个基于Kafka的流式处理类库。框架要求开发者按照特定的方式去开发逻辑部分,供框架调用。开发者很难了解框架的具体运行方式。而Kafka Stream作为流式处理类库,直接提供具体的类给开发者调用,整个应用的运行方式主要由开发者控制,方便使用和调试。
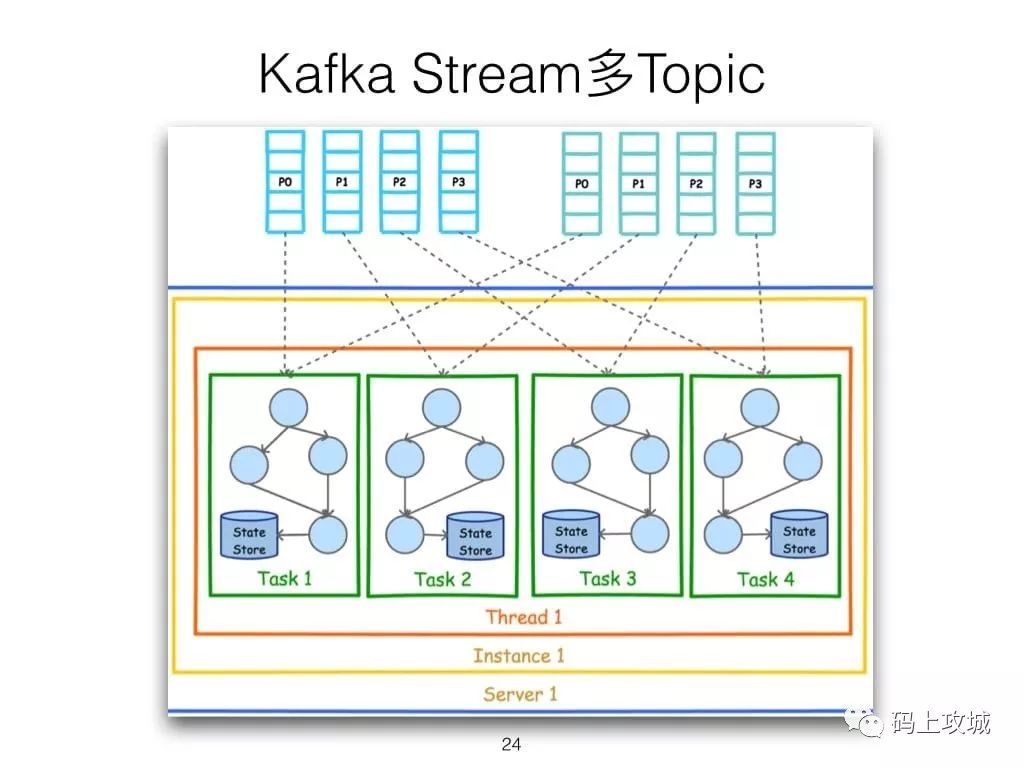
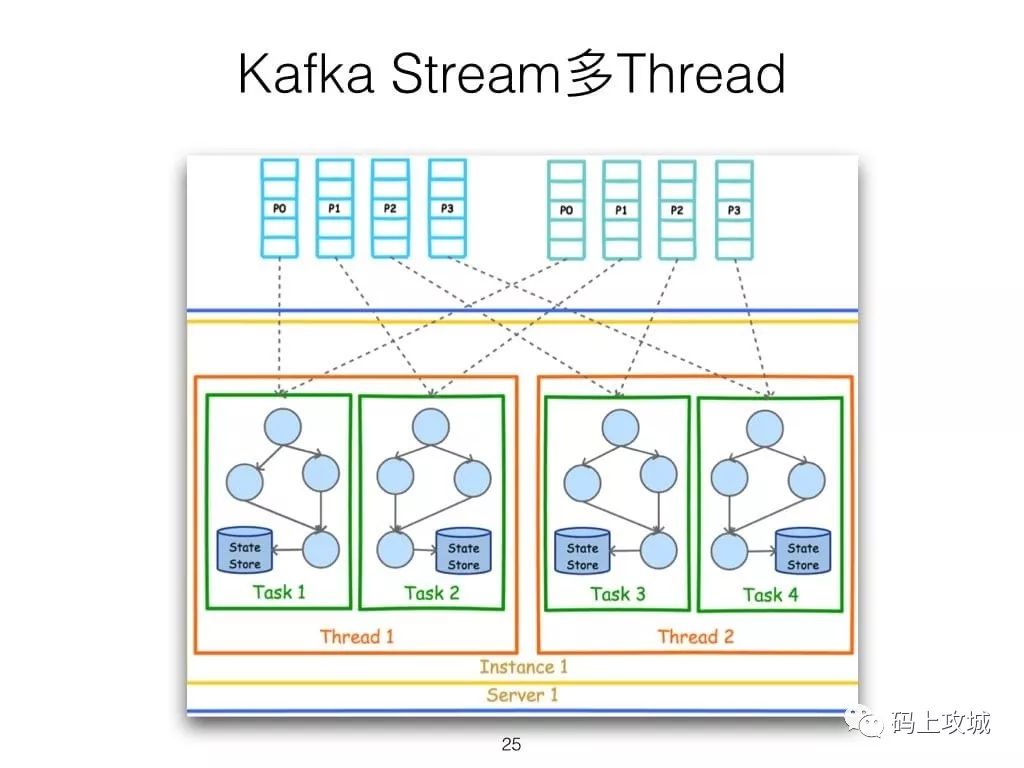
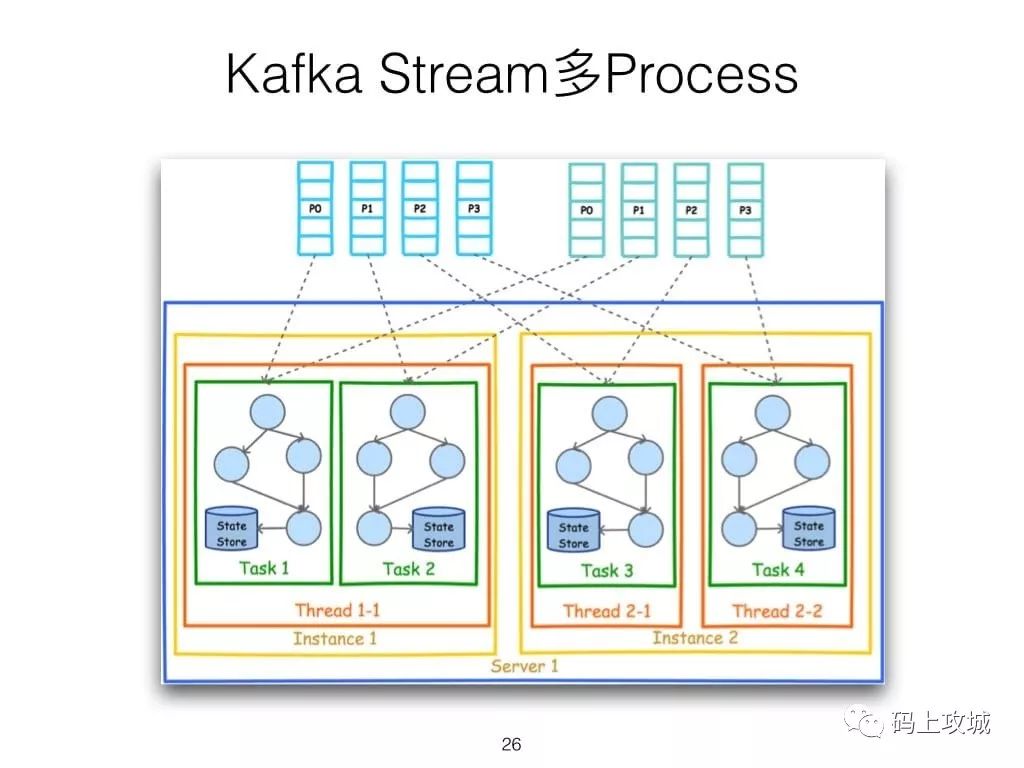
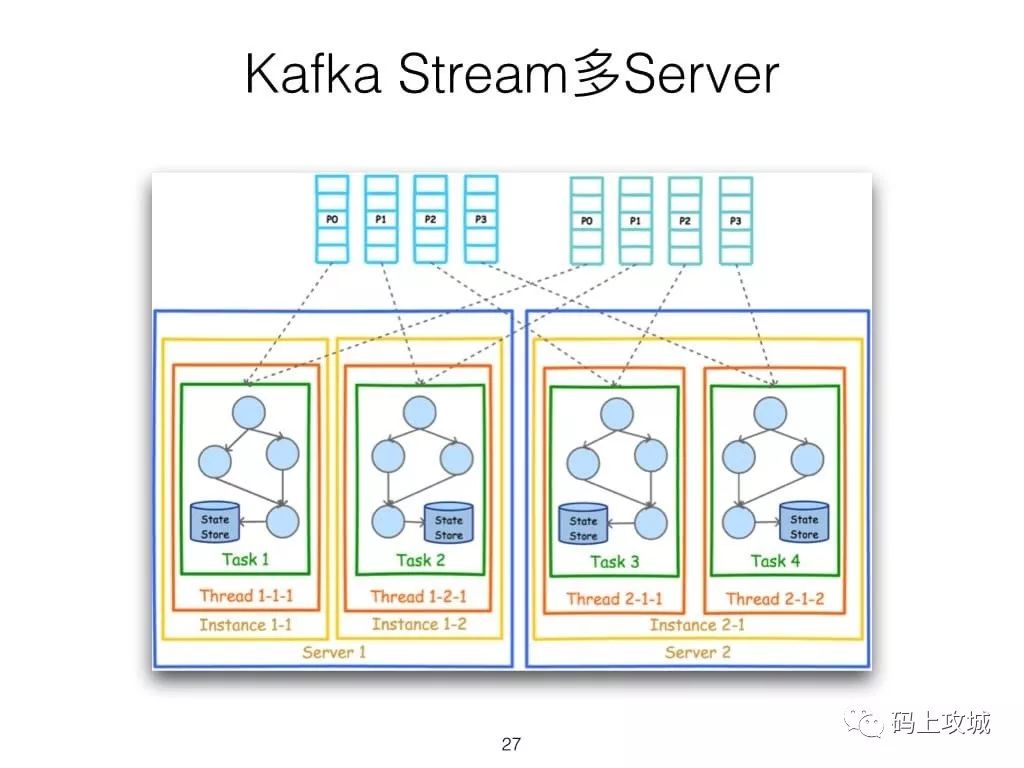
第二,虽然Cloudera与Hortonworks方便了Storm和Spark的部署,但是这些框架的部署仍然相对复杂。而Kafka Stream作为类库,可以非常方便的嵌入应用程序中,它对应用的打包和部署基本没有任何要求。更为重要的是,Kafka Stream充分利用了Kafka的分区机制和Consumer的Rebalance机制,使得Kafka Stream可以非常方便的水平扩展,并且各个实例可以使用不同的部署方式。具体来说,每个运行Kafka Stream的应用程序实例都包含了Kafka Consumer实例,多个同一应用的实例之间并行处理数据集。而不同实例之间的部署方式并不要求一致,比如部分实例可以运行在Web容器中,部分实例可运行在Docker或Kubernetes中。
第三,目前流式处理系统,基本都支持Kafka作为数据源。例如Storm具有专门的kafka-spout,而Spark也提供专门的spark-streaming-kafka模块。事实上,Kafka基本上是主流的流式处理系统的标准数据源。大部分流式系统中都已部署了Kafka,此时使用Kafka Stream的成本非常低。
第四,使用Storm或Spark Streaming时,需要为框架本身的进程预留资源,如Storm的supervisor和Spark on YARN的Node manager。框架本身也会占用部分资源,如Spark Streaming需要为shuffle和storage预留内存。
第五,由于Kafka本身提供数据持久化,因此Kafka Stream提供滚动部署和滚动升级以及重新计算的能力。
第六,由于Kafka Consumer Rebalance机制,Kafka Stream可以在线动态调整并行度。
PPT 分享


















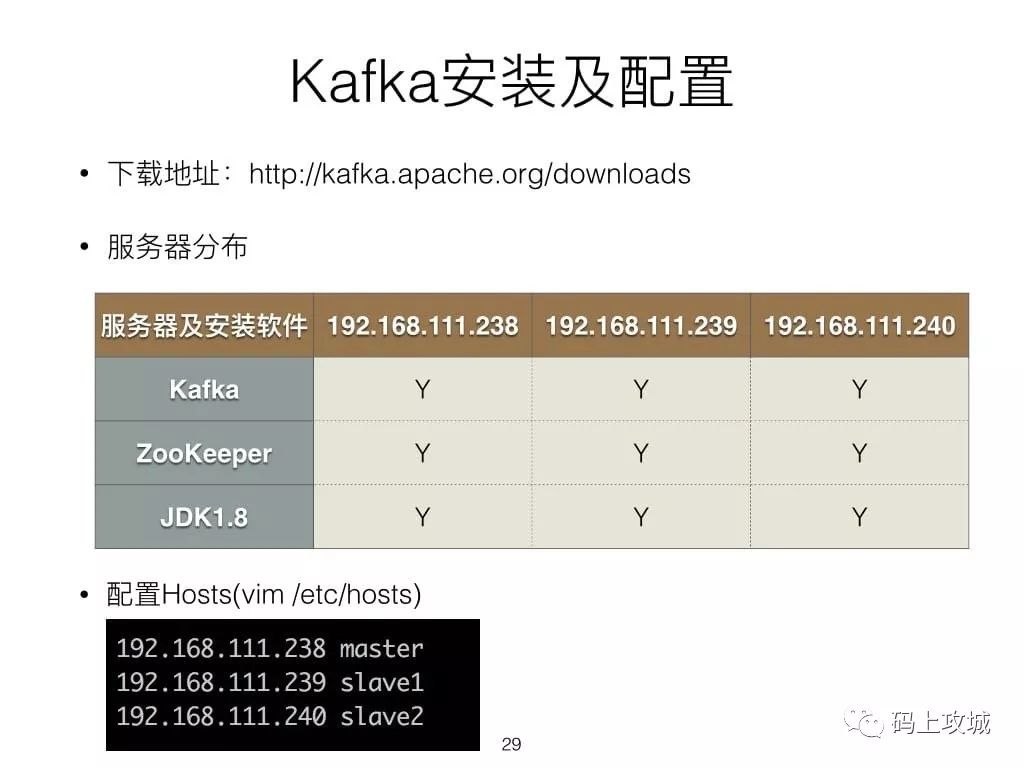





如有不当之处请指出,我后续逐步完善更正,谢谢~
以上是关于Kafka进阶的主要内容,如果未能解决你的问题,请参考以下文章