JStorm kafka集成解析
Posted data之道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JStorm kafka集成解析相关的知识,希望对你有一定的参考价值。
前言
上一篇<>从架构设计、计算模型上对jstorm做了系统化表述,读后会对应用场景、功能实现上有清晰明确的认识,建议没有看过的朋友看一看。这篇文章主要聊聊集成kafka的实现细节、开发时要注意的一些坑及优化方面的一些思考
实时流式计算框架一般从消息队列实时拉取数据,而kafka是很多公司首选的分布式消息发布订阅系统,jstorm也提供了消费kafka的spout,便于构建基于kafka的实时应用程序。关于kafka的更多介绍可参见<>
0x01 partition分配
kafka的一个topic会有一到多个partition,而spout task也可能有多个,所以在创建KafkaSpout task时,就给每个task分配好了待消费的partition列表,分配算法如下:
也就是说每个task在运行期间消费的partition是固定的,这样如果topology提交后,topic又新增了分区,会导致消费不到新增的partition
0x02 业务逻辑
KafkaSpout用SimpleConsumer低级API消费Kafka,手动管理offset是低级api要做的主要任务,当然KafkaSpout也不例外,KafkaSpout也是用zookeeper持久化offset。如果每次ack时都同步offset,消息量大的情况下,和zk交互就变得异常频繁,这对zk稳定性势必造成很大压力,也会降低topology吞吐率,所以KafkaSpout用定时机制同步offset,kafka.offset.update.interval.ms设置同步间隔,默认2s。
jstorm计算框架的ack机制保证了消息可靠性(消息不丢失):ack确认消息处理完毕,spout不用重复发送该消息;fail表示下游消息处理失败,spout要再次发送该消息以保证每条消息都会被成功处理。
结合jstorm框架和KafkaConsumer,内部主要涉及到ack/fail/emit、从kafka poll消息和commit postition这几个操作,其中poll消息、emit和commit position是在KafkaSpout.nextTuple方法内顺序执行的。涉及到的主要数据结构:
LinkedList<MessageAndOffset> emittingMessages :存储consumer从topic拉取的消息
SortedSet<Long> pendingOffsets:以有序方式存放从topic拉取到的消息offset
SortedSet<Long> failedOffsets:fail事件的消息offset
long emittingOffset:当前从topic拉取的消息offset
long lastCommittedOffset:最后一次持久化存储的offset
其时序图如下:
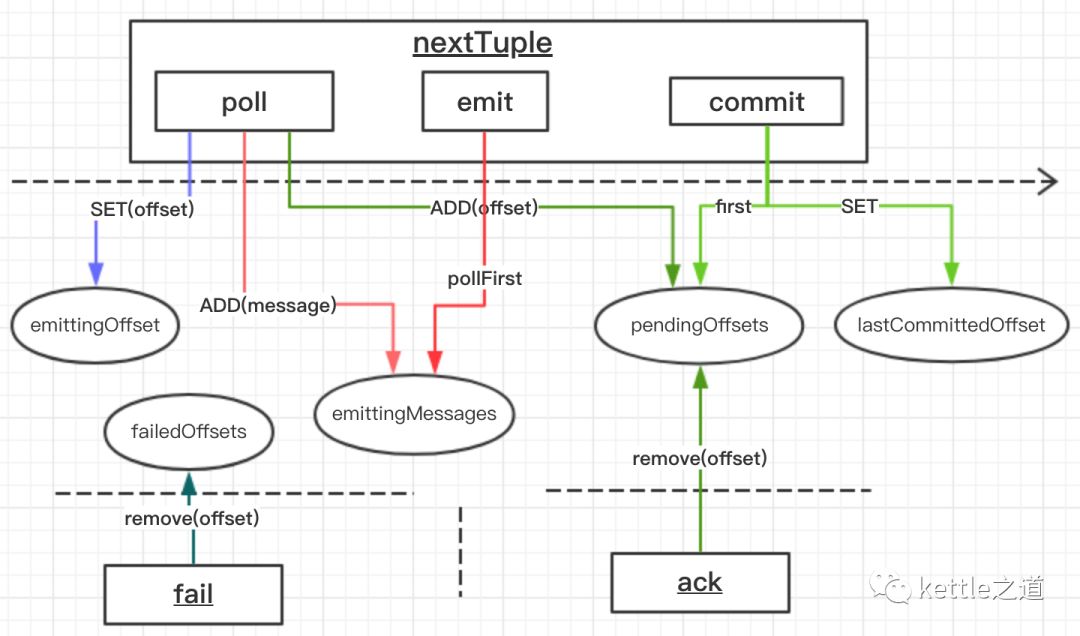
0x03 nextTuple、ack解析
如前所述,nextTuple方法会从kafka里拉取消息并把消息的offset add到pendingOffsets,而ack时从pendingOffsets里remove元素,ack和nextTuple可能并发执行,这样在并发场景下,因SortedSet是非线程安全的,就会出现异常:
解决这个bug的方案:
1、声明pendingOffsets为线程安全的SortedSet对象,比如ConcurrentSkipListSet
2、在对pendingOffsets的add、remove操作上加同步机制锁
0x04 commit offset解析
KafkaSpout是定时的(不是单独线程而是在nextTuple方法内)commit offset:从pendingOffsets有序列表里返回第一个(最小的offset)元素,然后判断和上次提交的offset(lastCommittedOffset)是否相同,如果不相同就把该offset存到ZK,否则不予处理。
如果下游处理失败,即fail而没有ack,就会产生一个问题,每次从pendingOffsets返回第一个元素时,都是这条fail消息的offset,导致offset不会commit,但实际上KafkaSpout还在继续消费kafka。而且KafkaSpout的fail函数只是把失败消息的offset从failedOffsets列表里remove掉,没有做进一步处理,这是一个隐形的bug。理论上对失败的消息是要重新发送的,才能保证最终处理结果是exactly once,如果emit失败的消息,要注意流式的顺序性。
以上是关于JStorm kafka集成解析的主要内容,如果未能解决你的问题,请参考以下文章
Storm编程之wordcount(kafka--》Jstorm--》redis)