Storm编程之wordcount(kafka--》Jstorm--》redis)
Posted zfszhangyuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Storm编程之wordcount(kafka--》Jstorm--》redis)相关的知识,希望对你有一定的参考价值。
本文是笔者这周做的一个小小的尝试。
设计的软件比较多,大家可以一一在本机安装一下,我的电脑是mac pro,基本安装起来和Linux基本一致,比较简单
基本都是下载 解压包 拷贝到安装目录重命名 然后启动服务
需要安装的基本有 JDK1.7,IDEA,kafka,Jstorm,redis都是单机
下面直接给出项目的pom.xml配置信息:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>KafkaStormTest</groupId>
<artifactId>zfs_try</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.2-incubating</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>0.9.2-incubating</version>
<scope>compile</scope>
</dependency>
<!--<dependency>-->
<!--<groupId>org.apache.kafka</groupId>-->
<!--<artifactId>kafka_2.9.2</artifactId>-->
<!--<version>0.8.1.1</version>-->
<!--<exclusions>-->
<!--<exclusion>-->
<!--<groupId>org.apache.zookeeper</groupId>-->
<!--<artifactId>zookeeper</artifactId>-->
<!--</exclusion>-->
<!--<exclusion>-->
<!--<groupId>log4j</groupId>-->
<!--<artifactId>log4j</artifactId>-->
<!--</exclusion>-->
<!--</exclusions>-->
<!--</dependency>-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.15</version>
</dependency>
<!--<dependency>-->
<!--<groupId>org.apache.storm</groupId>-->
<!--<artifactId>storm-core</artifactId>-->
<!--<version>1.0.2</version>-->
<!--<exclusions>-->
<!--<exclusion>-->
<!--<groupId>org.apache.logging.log4j</groupId>-->
<!--<artifactId>log4j-slf4j-impl</artifactId>-->
<!--</exclusion>-->
<!--<exclusion>-->
<!--<groupId>org.slf4j</groupId>-->
<!--<artifactId>log4j-over-slf4j</artifactId>-->
<!--</exclusion>-->
<!--</exclusions>-->
<!--</dependency>-->
<!--<dependency>-->
<!--<groupId>org.apache.storm</groupId>-->
<!--<artifactId>storm-kafka</artifactId>-->
<!--<version>1.0.2</version>-->
<!--</dependency>-->
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.10.1.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
</project>不是storm,如果你用storm的话请用0.9.*版本的,最新的版本我测试过貌似cluster这个类初始化有问题
LocalCluster cluster = new LocalCluster();我们先来看看main函数类的代码:其中主要配置spoutconf和初始化kafkaspout,如果看不懂可以直接看看官网的资料
https://github.com/apache/storm/blob/1.0.x-branch/external/storm-kafka/README.md
然后我为这个topology定义了两个bolt分别用于split word和wordcount 在wordcount中实现了数据load into redis
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.tuple.Fields;
import kafka.common.AuthorizationException;
import storm.kafka.*;
import storm.kafka.bolt.KafkaBolt;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
/**
* Created by mac on 2016/12/5.
*/
public class KafkaReader
public static void main(String[] args)
if (args.length != 2)
System.err.println("Usage: inputPaht timeOffset");
System.err.println("such as : java -jar WordCount.jar D://input/ 2");
System.exit(2);
String zks = "127.0.0.1:2181";//,h2:2181,h3:2181
String topic = "TEST-TOPIC";
String zkRoot = "/storm"; // default zookeeper root configuration for storm
String id = "word";
BrokerHosts brokerHosts = new ZkHosts(zks);
SpoutConfig spoutConf = new SpoutConfig(brokerHosts, topic, zkRoot, id);
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
spoutConf.useStartOffsetTimeIfOffsetOutOfRange=true;
spoutConf.forceFromStart= false;//.forceFromStart
spoutConf.zkServers = Arrays.asList(new String[] "127.0.0.1");//"h1", "h2", "h3"
spoutConf.zkPort = 2181;
KafkaSpout kafkaSpout=new KafkaSpout(spoutConf);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-reader", kafkaSpout,1); // Kafka我们创建了一个5分区的Topic,这里并行度设置为5
//builder.setSpout("word-reader", new WordReader());
// builder.setBolt("word-spilter", new WordSpliter()).shuffleGrouping("word-reader");
builder.setBolt("word-spilter", new WordSpliter()).shuffleGrouping("kafka-reader");
builder.setBolt("word-counter", new WordCounter2()).shuffleGrouping("word-spilter");
String inputPath = args[0];
String timeOffset = args[1];
Config conf = new Config();
conf.put("INPUT_PATH", inputPath);
conf.put("TIME_OFFSET", timeOffset);
conf.setDebug(false);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCount", conf, builder.createTopology());
/**
* Created by mac on 2016/12/5.
*/
import org.apache.commons.lang.StringUtils;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class WordSpliter extends BaseBasicBolt
private static final long serialVersionUID = -5653803832498574866L;
public void execute(Tuple input, BasicOutputCollector collector)
String line = input.getString(0);
String[] words = line.split(" ");
for (String word : words)
word = word.trim();
if (StringUtils.isNotBlank(word))
word = word.toLowerCase();
collector.emit(new Values(word));
public void declareOutputFields(OutputFieldsDeclarer declarer)
declarer.declare(new Fields("word"));
/**
* Created by mac on 2016/12/5.
*/
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
public class WordCounter2 extends BaseBasicBolt
private static final long serialVersionUID = 5683648523524179434L;
private HashMap<String, Integer> counters = new HashMap<String, Integer>();
private volatile boolean edit = false;
@SuppressWarnings("rawtypes")
public void prepare(Map stormConf, TopologyContext context)
final long timeOffset = Long.parseLong(stormConf.get("TIME_OFFSET").toString());
new Thread(new Runnable()
public void run()
while (true)
if (edit)
for (Entry<String, Integer> entry : counters.entrySet())
System.out.println(entry.getKey() + " : " + entry.getValue());
System.out.println("WordCounter---------------------------------------");
edit = false;
try
Thread.sleep(timeOffset * 1000);
catch (InterruptedException e)
e.printStackTrace();
).start();
//load into redis
public void execute(Tuple input, BasicOutputCollector collector)
String str = input.getString(0);
RedisMethod jedistest = new RedisMethod();
jedistest.setup();
System.out.println("Connection to server sucessfully");
if (!counters.containsKey(str))
counters.put(str, 1);
else
Integer c = counters.get(str) + 1;
counters.put(str, c);
jedistest.jedis.zincrby("storm2redis",1,str);
edit = true;
System.out.println("WordCounter+++++++++++++++++++++++++++++++++++++++++++");
public void declareOutputFields(OutputFieldsDeclarer declarer)
// declarer.declare(new Fields("key"));
// declarer.declare(new Fields("value"));
import redis.clients.jedis.Jedis;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
/**
* Created by mac on 2016/12/6.
*/
public class RedisMethod
public static void main(String[] args)
RedisMethod jedistest = new RedisMethod();
jedistest.setup();
System.out.println("Connection to server sucessfully");
//查看服务是否运行
jedistest.testzadd();
// Map<double, String> map = new HashMap<double, String>();
//
// map.put(12, "hadoop");
// map.put(11, "hbase");
// map.put(13, "storm");
// jedis.zadd("user",map);
public Jedis jedis;
public void setup()
//连接redis服务器,127.0.0.1:6379
jedis = new Jedis("127.0.0.1", 6379);
//权限认证
jedis.auth("123456");
System.out.println("Server is running: "+jedis.ping());
/**
* redis存储字符串
*/
public void testzadd()
jedis.zadd("zfs1",2,"hadoop");
jedis.zadd("zfs1",1,"storm");
jedis.zadd("zfs1",3,"hive");
Map<String,Double> map = new HashMap<String,Double>();
map.put("hadoop",12.0);
map.put("hbase",11.0);
map.put("storm",13.0);
map.put("hadoop1",12.0);
map.put("hbase1",11.0);
map.put("storm1",13.0);
jedis.zadd("mapdf",map);
public void testString()
//-----添加数据----------
jedis.set("name","xinxin");//向key-->name中放入了value-->xinxin
System.out.println(jedis.get("name"));//执行结果:xinxin
jedis.append("name", " is my lover"); //拼接
System.out.println(jedis.get("name"));
jedis.del("name"); //删除某个键
System.out.println(jedis.get("name"));
//设置多个键值对
jedis.mset("name","liuling","age","23","qq","476777XXX");
jedis.incr("age"); //进行加1操作
System.out.println(jedis.get("name") + "-" + jedis.get("age") + "-" + jedis.get("qq"));
/**
* redis操作Map
*/
public void testMap()
//-----添加数据----------
Map<String, String> map = new HashMap<String, String>();
map.put("name", "xinxin");
map.put("age", "22");
map.put("qq", "123456");
jedis.hmset("user",map);
//取出user中的name,执行结果:[minxr]-->注意结果是一个泛型的List
//第一个参数是存入redis中map对象的key,后面跟的是放入map中的对象的key,后面的key可以跟多个,是可变参数
List<String> rsmap = jedis.hmget("user", "name", "age", "qq");
System.out.println(rsmap);
//删除map中的某个键值
jedis.hdel("user","age");
System.out.println(jedis.hmget("user", "age")); //因为删除了,所以返回的是null
System.out.println(jedis.hlen("user")); //返回key为user的键中存放的值的个数2
System.out.println(jedis.exists("user"));//是否存在key为user的记录 返回true
System.out.println(jedis.hkeys("user"));//返回map对象中的所有key
System.out.println(jedis.hvals("user"));//返回map对象中的所有value
Iterator<String> iter=jedis.hkeys("user").iterator();
while (iter.hasNext())
String key = iter.next();
System.out.println(key+":"+jedis.hmget("user",key));
jedis.hdel("user");
/**
* jedis操作List
*/
public void testList()
//开始前,先移除所有的内容
jedis.del("java framework");
System.out.println(jedis.lrange("java framework",0,-1));
//先向key java framework中存放三条数据
jedis.lpush("java framework","spring");
jedis.lpush("java framework","struts");
jedis.lpush("java framework","hibernate");
//再取出所有数据jedis.lrange是按范围取出,
// 第一个是key,第二个是起始位置,第三个是结束位置,jedis.llen获取长度 -1表示取得所有
System.out.println(jedis.lrange("java framework",0,-1));
jedis.del("java framework");
jedis.rpush("java framework","spring");
jedis.rpush("java framework","struts");
jedis.rpush("java framework","hibernate");
System.out.println(jedis.lrange("java framework",0,-1));
/**
* jedis操作Set
*/
public void testSet()
//添加
jedis.del("user");
jedis.sadd("user","liuling");
jedis.sadd("user","xinxin");
jedis.sadd("user","ling");
jedis.sadd("user","zhangxinxin");
jedis.sadd("user","who");
//移除noname
jedis.srem("user","who");
System.out.println(jedis.smembers("user"));//获取所有加入的value
System.out.println(jedis.sismember("user", "who"));//判断 who 是否是user集合的元素
System.out.println(jedis.srandmember("user"));
System.out.println(jedis.scard("user"));//返回集合的元素个数
public void test() throws InterruptedException
//jedis 排序
//注意,此处的rpush和lpush是List的操作。是一个双向链表(但从表现来看的)
jedis.del("a");//先清除数据,再加入数据进行测试
jedis.rpush("a", "1");
jedis.lpush("a","6");
jedis.lpush("a","3");
jedis.lpush("a","9");
System.out.println(jedis.lrange("a",0,-1));// [9, 3, 6, 1]
System.out.println(jedis.sort("a")); //[1, 3, 6, 9] //输入排序后结果
System.out.println(jedis.lrange("a",0,-1));
好,到这里已经已经贴了全部代码了。
先来看看结果
首先进入到kafka的客户端生产数据:
程序终端显示如下:
下面我们看看redis里面数值:
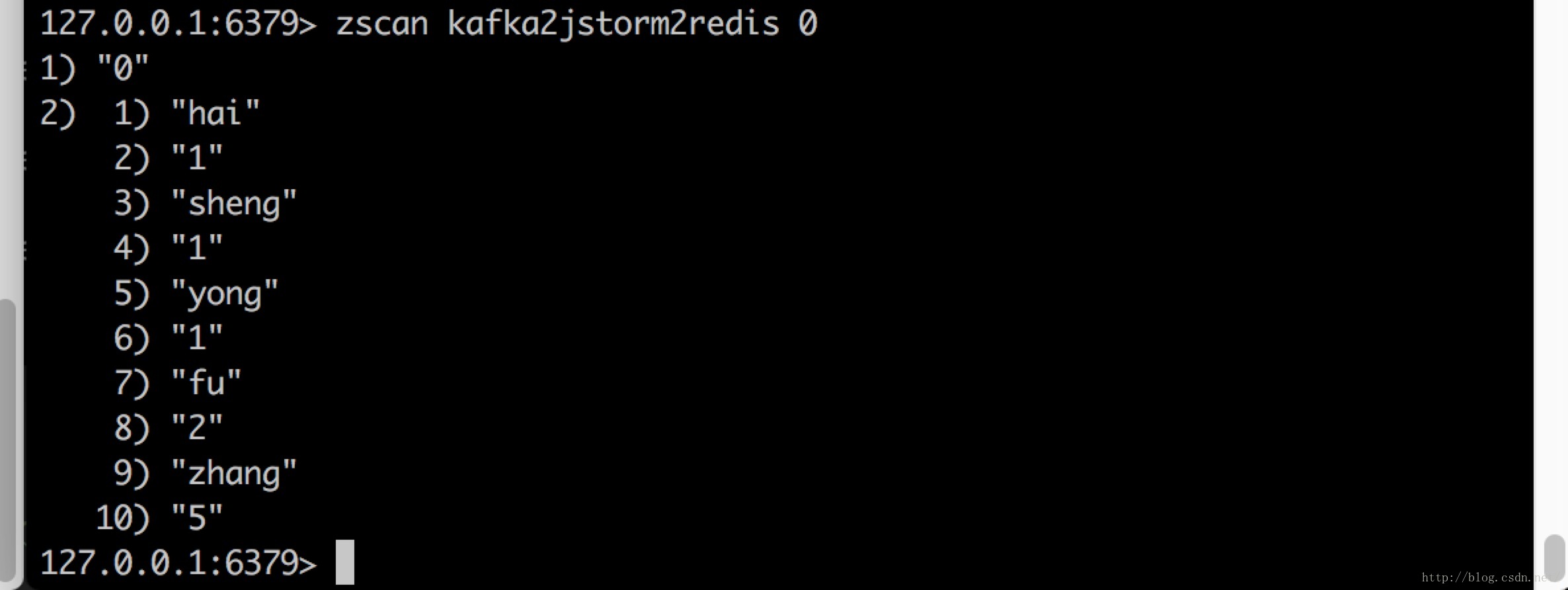
验证成功,下面来把代码打成jar包,因为这里我们用到了jedis的jar包,我们可以将这个jar先copy到Jstorm Lib目录下,或者直接打包时打到包内,将我们打的jar传到Jstorm Lib目录下,运行
bin/jstorm jar /Users/mac/jstorm-2.1.1/lib/KafkaStormTest.jar KafkaReader Users/mac/input 2 即可,后面的两位是参数,是我测试本地文件夹为spout的时用的,你可以改下代码不用可以去掉。以上是关于Storm编程之wordcount(kafka--》Jstorm--》redis)的主要内容,如果未能解决你的问题,请参考以下文章