心得浅谈Kafka
Posted 老张的技术博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了心得浅谈Kafka相关的知识,希望对你有一定的参考价值。
今天下午参加了腾讯云+社区组织的kafka公开课,收获良多。正巧在工作中也遇到过kafka的问题,今天听完之后产生了非常多的感想。无奈篇幅有限,本人又文笔愚钝,所以今天的分享主要提及对我感触最深的内容。分享的顺序还是按照老形式来进行吧(提出疑问——解决疑问)
【提出疑问】
1、为什么要设计kafka?
2、开源的kafka架构是怎么样的?
3、腾讯云的ckafka架构是怎样的?
4、腾讯云的ckafka架构解决了什么样的问题?
5、我对开源kafka的设想?
一、为什么要设计kafka?
扩容性
过去生产消费模型采用的消息队列一般为RabbitMQ、ZeroMQ(最快)等。这些消息队列对于数据的处理量存在一个上限,也就是说随着信息化的数据爆炸式增长会出现一个吞吐量的瓶颈。下图是我在网上找的图,表示的是以往消息队列的形式。过去MQ的瓶颈存在的原因在于这个队列不能很好的支持扩容。举个通俗点的例子来说过去的MQ是一条乡间小路,路的大小是事先设计好的。而kafka则是一条高速公路,且这条高速公路可以根据业务的需求进行扩展(流量大时采用5车道,闲时采用2车道)。因此这同时也是一种非常节约资源的解决方案。
统一处理
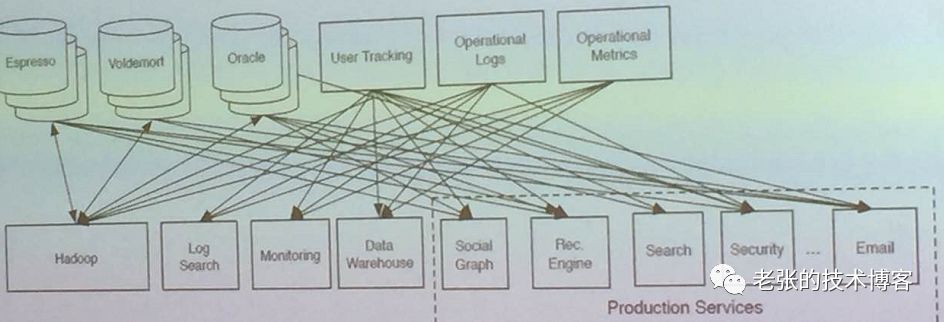
上图表示的是以前的处理方式。举个案例来说,现在公司里有两个数据源(oracle和mysql),我需要给每个业务都定义一个使用数据库的接口。然而随着公司业务的不断扩展,数据源的种类越来越多,添加了诸如redis等,同时业务的变更也扩展地非常快。这时如果对每个业务都编写一个接口就会显得非常麻烦。kafka则可以很好的应对上述场景,这也是基于避免重复造轮子的思想。
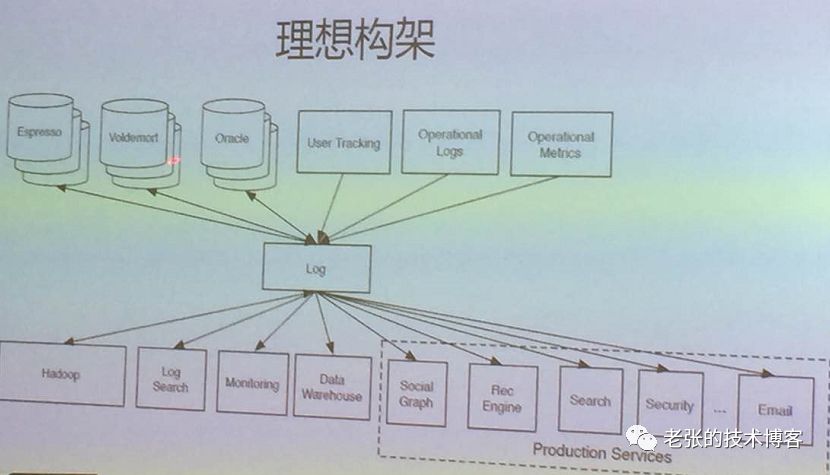
上图是简单的kafka架构。kafka的开源版本里提供了很多数据源的接口,业务只需要对kafka集群进行连接就可以实现对数据的抓取。与此同时,kafka集群还可以进行对数据的筛选。也就是后面会提到的日志存储。
二、开源的kafka架构是怎么样的?
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition.
Producer
负责发布消息到Kafka broker
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
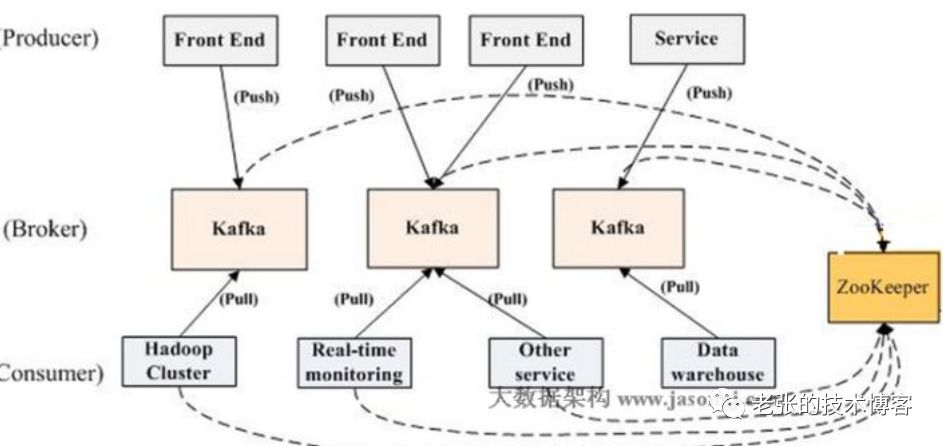
topic&partition理解
每个topic都可以看成是一个队列,消费必须指定它的topic。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
日志存储
开源kafka的日志存储可以实现数据解耦、多消费者读取等功能。如下图所示
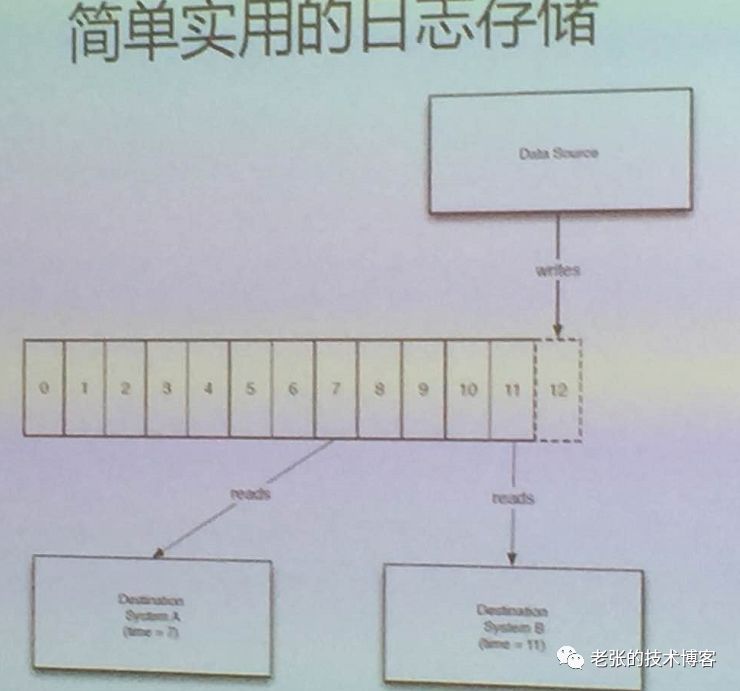
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略删除旧数据。一是基于时间,二是基于Partition文件大小。
HA
为了提高Kafka的容错能力,需要将同一个Partition的Replica尽量分散到不同的机器。如果某个Broker宕机了,需要保证它上面的负载可以被均匀的分配到其它幸存的所有Broker上。此外,还涉及了投票选举机制。也就是说当一个leader挂了之后会投票选出一个新leader。(具体机制改天再整理出个详细的文档)。
开源的kafka架构是将各个topic冗余备份分步到各个broker上,当一个broker挂了之后能够很快的根据备份信息恢复。

数据筛选
开源kafka支持sql、java、python等语言的过滤程序。下图是基于sql改良的ksql

三、腾讯云的ckafka架构是怎样的?
腾讯云ckafka项目在开源kafka项目的基础上做了很多的改进,下图是ckafka的特点

ckafka的现状
1、日消息超万亿条、总流量数十PB级,单集群每分钟达十亿
2、broker数量上千,集群有上百个
3、服务付费实例超千个,topic也过千
总的来说就是日消息量、日吞吐量、集群分钟吞吐量都非常庞大
broker的选择
新建实例时,如何选择broker才能保证资源的充分利用?针对这一问题,腾讯云是基于带宽和磁盘容量来判断的。会根据broker中存储的topic类别,来存放最类似的topic到这个集群。
实例的升配
在升配方面,首先会预估节点变更的可能性和资源的利用率,其次会计算迁移的代价。也就是当容量不够的时候存在两种情况:1、分区节点有冗余,这种情况会直接升级2、broker资源不足,这时就要进行迁移重新划分资源。当新节点加入后还需要进行机器的负载均衡、节点资源的碎片整理。
实例的迁移
据我的感受而言,腾讯云在迁移方面做的是最好的。大概存在三种情况会需要迁移:服务异常、实例扩缩容、负载均衡。
迁移又涉及到三种情况:
1、leader迁移:数据迁移代价较小,可能会造成cpu负载及网卡出流量
2、replica迁移:代价比较大,会消耗非常多的机器资源
3、迁移对象和目的地的考量:数据大小、生产/消费速率、资源利用率
四、腾讯云的ckafka架构解决了什么样的问题?
我印象最深的主要有3点改良:
1、在高负载情况下的调优
2、增强了容错机制
3、增强了故障处理机制
五、我对开源kafka的设想?
就我愚见,目前kafka在故障应对机制方面还不是很强。现在只能做到事故发生后再处理。如果能够事先收集各种故障的信息,进行数据分析,使其能够在故障前自动的处理就能够将故障扼杀在摇篮中。
由此略微展开联想,可以设计一种信息收集组件并提供自定义行为接口,用户能够自行通过接口设计故障前的行为。这也是我对未来运维的展望——工程师能够专注于处理隐患机器,故障判断交予机器。
以上是关于心得浅谈Kafka的主要内容,如果未能解决你的问题,请参考以下文章
知了堂学习心得浅谈c3p0连接池和dbutils工具类的使用