kafka心得记录
Posted @富士山下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka心得记录相关的知识,希望对你有一定的参考价值。
1.为何引入kafka?
削峰填谷,主要还是为了应对上游瞬时大流量的冲击,避免出现流量毛刺现象,保护下游应用和数据库不被大流量打垮。
2.kafka备份机制,主从机制,Leader-Follower:
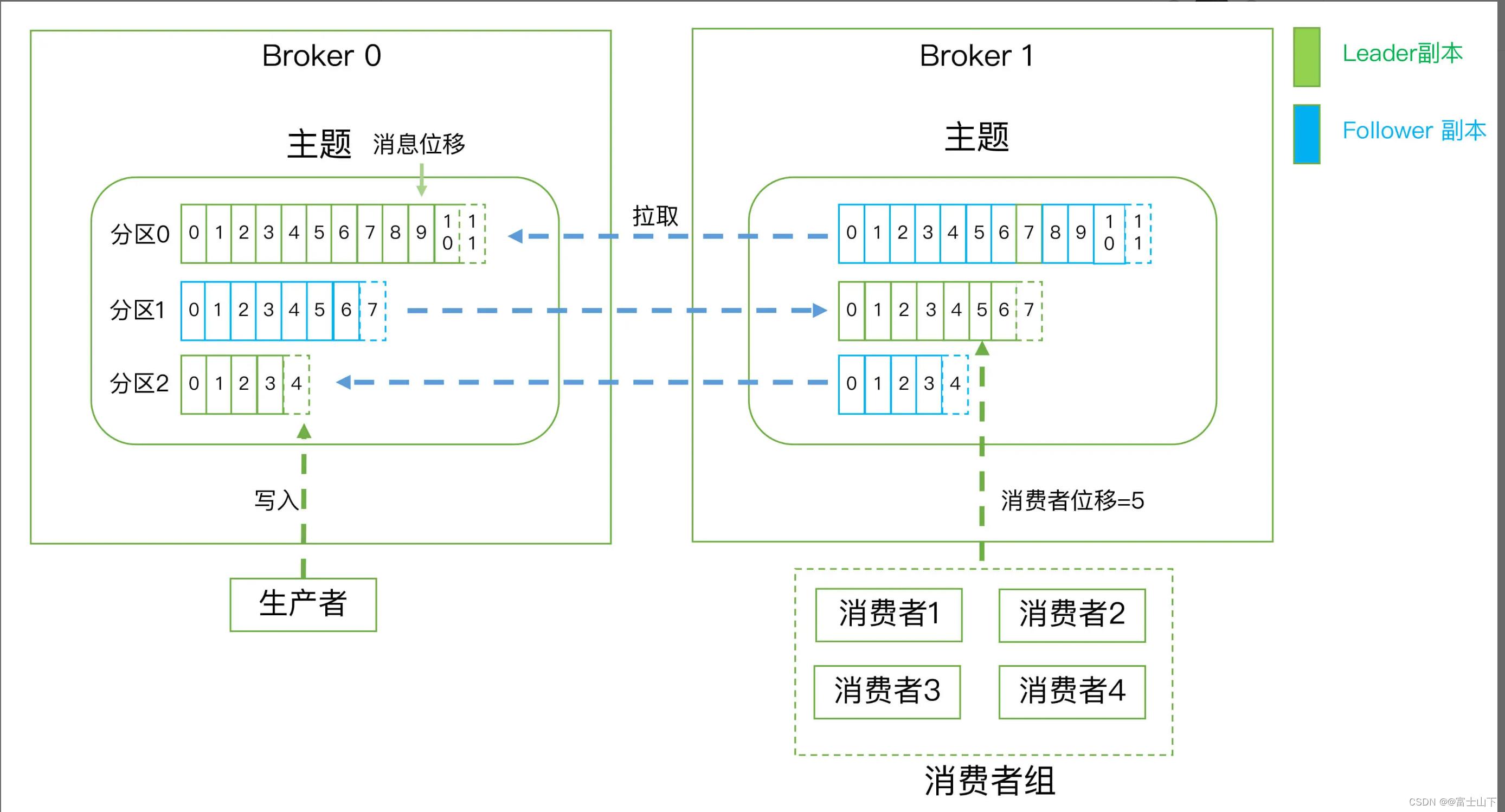
Kafka 定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica)。前者对外提供服务,这里的对外指的是与客户端程序进行交互;而后者只是被动地追随领导者副本而已,不能与外界进行交互。副本的工作机制也很简单:生产者总是向领导者副本写消息;而消费者总是从领导者副本读消息。至于追随者副本,它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步
3.kafka伸缩性问题:
虽然有了副本机制可以保证数据的持久化或消息不丢失,但没有解决伸缩性的问题。倘若领导者副本积累了太多的数据以至于单台 Broker 机器都无法容纳了,此时应该怎么办呢?把数据分割成多份保存在不同的 Broker 上,kafka就是这么做的,这种机制就是所谓的分区(Partitioning)。Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中。实际上,副本是在分区这个层级定义的。每个分区下可以配置若干个副本,其中只能有 1 个领导者副本和 N-1 个追随者副本。生产者向分区写入消息,每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征。
4.Kafka 的三层消息架构
第一层是主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。
第二层是分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
第三层是消息层,分区中包含若干条消息,每条消息的位移从 0 开始,依次递增。
最后,客户端程序只能与分区的领导者副本进行交互。
5.Kafka Broker 是如何持久化数据的
总的来说,Kafka 使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序 I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段。不过如果你不停地向一个日志写入消息,最终也会耗尽所有的磁盘空间,因此 Kafka 必然要定期地删除消息以回收磁盘。怎么删除呢?简单来说就是通过日志段(Log Segment)机制。在 Kafka 底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka 在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
6.kafka概念图
7.重复消费:
所谓的重复消费是指,C1消费了一部分数据,还没来得及提交这部分数据的位移就挂了。C2承接过来之后会重新消费这部分数据。
8.为什么 Kafka 不像 MySQL 那样允许追随者副本对外提供读服务?
因为mysql一般部署在不同的机器上一台机器读写会遇到瓶颈,Kafka中的领导者副本一般均匀分布在不同的broker中,已经起到了负载的作用。即:同一个topic的已经通过分区的形式负载到不同的broker上了,读写的时候针对的领导者副本,但是量相比mysql一个还实例少太多,个人觉得没有必要在提供度读服务了。
9.分区机制
分区的作用就是提供负载均衡的能力,或者说对数据进行分区的主要原因,就是为了实现系统的高伸缩性(Scalability)。不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的。
轮询策略,轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一。
随机策略,先计算出该主题总的分区数,然后随机地返回一个小于它的正整数。
按消息键保序策略,Kafka 允许为每条消息定义消息键,简称为 Key,一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略。
10.kafka压缩和解压缩
默认Producer 端压缩、Broker 端保持、Consumer 端解压缩。
除了在 Consumer 端解压缩,Broker 端也有可能进行解压缩,一种是Broker 端指定了和 Producer 端不同的压缩算法,另外一种是Broker 端发生了消息格式转换。
启用压缩的一个条件就是 Producer 程序运行机器上的 CPU 资源要很充足。如果 Producer 运行机器本身 CPU 已经消耗殆尽了,那么启用消息压缩无疑是雪上加霜,只会适得其反。
11.Kafka 消息交付可靠性保障以及精确处理一次语义的实现。
最多一次(at most once):消息可能会丢失,但绝不会被重复发送。
至少一次(at least once):消息不会丢失,但有可能被重复发送。
精确一次(exactly once):消息不会丢失,也不会被重复发送。
Kafka消息交付可靠性保障以及精确处理一次语义通过两种机制来实现的:冥等性(Idempotence)和事务(Transaction)。
冥等性
(1)什么是幂等性(Idempotence)
A:“幂等”:原是数学概念,指某些操作或函数能够被执行多次,但每次得到的结果都不变。
B:计算机领域的含义:
a,在命令式编程语言(如C)中,若一个子程序是幂等的,那它必然不能修改系统状态。无论这个子程序运行多少次,与该子程序的关联的那部分系统保持不变。
b,在函数式编程语言(比如Scala或Haskell)中,很多纯函数(pure function)天然就是幂等的,他们不执行任何的side effect。
C:冥等性的优点:最大的优势是可以安全地重试任何冥等性操作,因为他们不会破坏系统状态
(2)冥等性Producer
A:开启:设置props.put(“enable.idempotence”,true)或props.put(ProducerConfig.ENABLE_IDEMPOTENC_CONFIG,true)。
B:特征:开启后,Kafka自动做消息的重复去重。
C:实现思路:用空间换取时间,Broker端多保存一些字段,当Producer发送了具有相同字段值的消息后,Broker就可以知道这些消息重复,就将这些消息丢弃。
D:作用范围:
(1)只能保证单分区上幂等性,无法实现多个分区的幂等性。
(2)只能实现单会话上的冥等性,当Producer重启后,这种幂等性保证就失效了。
事务
(1)事务概念:
A:事务提供的安全性保障是经典的ACID。原子性(Atomicity),一致性(Consistency),隔离性(Isolation),持久性(Durability)。
B:kafka的事务机制可以保证多条消息原子性地写入到目标分区,同时也能保证Consumer只能看到事务成功提交的消息。
(2)事务型Producer:
A:开启:
【1】设置enable.idempotence = true。
【2】设置Producer端参数transactional.id。最好为其设置一个有意义的名字。
【3】调整Producer代码,显示调用事务API。
【4】设置Consumer端参数 isolation.level 值:
read_uncommitted(默认值,能够读到kafka写入的任何消息)
read_committed(Consumer只会读取事务型Producer成功事务写入的消息。)
B:特征:
【1】能够保证将消息原子性地写入到多个分区中。一批消息要么全部成功,要么全部失败。
【2】不惧进程重启,Producer重启回来后,kafka依然能保证发送的消息的精确一次处理。
关键事项:
1,幂等性无法实现多个分区以及多会话上的消息无重复,但事务(transaction)或依赖事务型Produce可以做到。
2,开启事务对性能影响很大,在使用时要充分考虑
12.消费组
Consumer Group :Kafka提供的可扩展且具有容错性的消息者机制。
1,重要特征:
A:组内可以有多个消费者实例(Consumer Instance)。
B:消费者组的唯一标识被称为Group ID,组内的消费者共享这个公共的ID。
C:消费者组订阅主题,主题的每个分区只能被组内的一个消费者消费
D:消费者组机制,同时实现了消息队列模型和发布/订阅模型。
2,重要问题:
A:消费组中的实例与分区的关系:
消费者组中的实例个数,最好与订阅主题的分区数相同,否则多出的实例只会被闲置。一个分区只能被一个消费者实例订阅。
B:消费者组的位移管理方式:
(1)对于Consumer Group而言,位移是一组KV对,Key是分区,V对应Consumer消费该分区的最新位移。
(2)Kafka的老版本消费者组的位移保存在Zookeeper中,好处是Kafka减少了Kafka Broker端状态保存开销。但ZK是一个分布式的协调框架,不适合进行频繁的写更新,这种大吞吐量的写操作极大的拖慢了Zookeeper集群的性能。
(3)Kafka的新版本采用了将位移保存在Kafka内部主题的方法。
C:消费者组的重平衡:
(1)重平衡:本质上是一种协议,规定了消费者组下的每个消费者如何达成一致,来分配订阅topic下的每个分区。
(2)触发条件:
a,组成员数发生变更
b,订阅主题数发生变更
c,定阅主题分区数发生变更
(3)影响:
Rebalance 的设计是要求所有consumer实例共同参与,全部重新分配所有用分区。并且Rebalance的过程比较缓慢,这个过程消息消费会中止。
以上是关于kafka心得记录的主要内容,如果未能解决你的问题,请参考以下文章