kafka源码系列之mysql数据增量同步到kafka
Posted 浪尖聊大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka源码系列之mysql数据增量同步到kafka相关的知识,希望对你有一定的参考价值。
一,架构介绍
生产中由于历史原因web后端,mysql集群,kafka集群(或者其它消息队列)会存在一下三种结构。
1,数据先入mysql集群,再入kafka
数据入mysql集群是不可更改的,如何再高效的将数据写入kafka呢?
A),在表中存在自增ID的字段,然后根据ID,定期扫描表,然后将数据入kafka。
B),有时间字段的,可以按照时间字段定期扫描入kafka集群。
C),直接解析binlog日志,然后解析后的数据写入kafka。
2,web后端同时将数据写入kafka和mysql集群
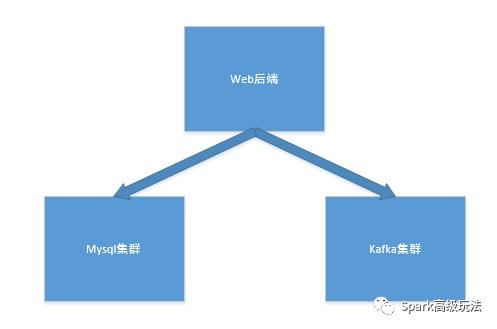
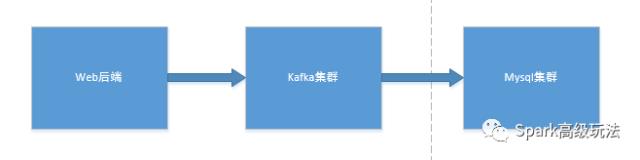
3,web后端将数据先入kafka,再入mysql集群
这个方式,有很多优点,比如可以用kafka解耦,然后将数据按照离线存储和计算,实时计算两个模块构建很好的大数据架构。抗高峰,便于扩展等等。
二,实现步骤
1,mysql安装准备
安装mysql估计看这篇文章的人都没什么问题,所以本文不具体讲解了。
A),假如你单机测试请配置好server_id
B),开启binlog,只需配置log-bin
[root@localhost ~]# cat /etc/my.cnf
[mysqld]
server_id=1
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-bin=/var/lib/mysql/mysql-binlog
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
创建测试库和表
create database school character set utf8 collate utf8_general_ci;
create table student(
name varchar(20) not null comment '姓名',
sid int(10) not null primary key comment '学员',
majora varchar(50) not null default '' comment '专业',
tel varchar(11) not null unique key comment '手机号',
birthday date not null comment '出生日期'
);
2,binlog日志解析
两种方式:
一是扫面binlog文件(有需要的话请联系浪尖)
二是通过复制同步的方式
暂实现了第二种方式,样例代码如下:
MysqlBinlogParse mysqlBinlogParse = new MysqlBinlogParse(args[0],Integer.valueOf(args[1]),args[2],args[3]){
@Override
public void processDelete(String queryType, String database, String sql) {
try {
String jsonString = SqlParse.parseDeleteSql(sql);
JSONObject jsonObject = JSONObject.fromObject(jsonString);
jsonObject.accumulate("database", database);
jsonObject.accumulate("queryType", queryType);
System.out.println(sql);
System.out.println(" ");
System.out.println(" ");
System.out.println(jsonObject.toString());
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
@Override
public void processInsert(String queryType, String database, String sql) {
try {
String jsonString = SqlParse.parseInsertSql(sql);
JSONObject jsonObject = JSONObject.fromObject(jsonString);
jsonObject.accumulate("database", database);
jsonObject.accumulate("queryType", queryType);
System.out.println(sql);
System.out.println(" ");
System.out.println(" ");
System.out.println(jsonObject.toString());
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
@Override
public void processUpdate(String queryType, String database, String sql) {
String jsonString;
try {
jsonString = SqlParse.parseUpdateSql(sql);
JSONObject jsonObject = JSONObject.fromObject(jsonString);
jsonObject.accumulate("database", database);
jsonObject.accumulate("queryType", queryType);
System.out.println(sql);
System.out.println(" ");
System.out.println(" ");
System.out.println(jsonObject.toString());
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
};
mysqlBinlogParse.setServerId(3);
mysqlBinlogParse.start();
3,sql语法解析
从原始的mysql 的binlog event中,我们能解析到的信息,主要的也就是mysql的database,query类型(INSERT,DELETE,UPDATE),具体执行的sql。我这里封装了三个重要的方法。只暴露了这三个接口,那么我们要明白的事情是,我们入kafka,然后流式处理的时候希望的到的是跟插入mysql后一样格式的数据。这个时候我们就要自己做sql的解析,将query的sql解析成字段形式的数据,供流式处理。解析的格式如下:
A),INSERT

B),DELETE

C),UPDATE
最终浪尖是将解析后的数据封装成了json,然后我们自己写kafka producer将消息发送到kafka,后端就可以处理了。
三,总结
最后,浪尖还是建议web后端数据最好先入消息队列,如kafka,然后分离线和实时将数据进行解耦分流,用于实时处理和离线处理。
消息队列的订阅者可以根据需要随时扩展,可以很好的扩展数据的使用者。
消息队列的横向扩展,增加吞吐量,做起来还是很简单的。这个用传统数据库,分库分表还是很麻烦的。
由于消息队列的存在,也可以帮助我们抗高峰,避免高峰时期后端处理压力过大导致整个业务处理宕机。
具体源码球友可以在知识星球获取。
欢迎大家进入知识星球,学习更多更深入的大数据知识,面试经验,获取更多更详细的资料。
以上是关于kafka源码系列之mysql数据增量同步到kafka的主要内容,如果未能解决你的问题,请参考以下文章
Kafka Connect JDBC Source MySQL 增量同步
Flink 实战系列Flink CDC 实时同步 Mysql 全量加增量数据到 Hudi