时间序列数据库(HiTSDB)压缩算法的FPGA加速
Posted 云技术与人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了时间序列数据库(HiTSDB)压缩算法的FPGA加速相关的知识,希望对你有一定的参考价值。
Gorillas是facebook开源的一款时间序列数据库,用于存储其内部数据中心监控指标,其格式为一个kev-value 对,key表示时间,value表示监控的值;这种数据库在集团内部也有着广泛的使用,尤其是在IoT场景下,数以千万的IoT设备工作的一些指标需要采集并存储。阿里云使用FPGA进行加速时间序列数据库HiTSDB.
高性能时间序列数据库 (High-Performance Time Series Database , 简称 HiTSDB) 是一种高性能,低成本,稳定可靠的在线时序数据库服务;提供高效读写,高压缩比存储、时序数据插值及聚合计算,广泛应用于物联网(IoT)设备监控系统 ,企业能源管理系统(EMS),生产安全监控系统,电力检测系统等行业场景。 HiTSDB 提供百万级时序数据秒级写入,高压缩比低成本存储、预降精度、插值、多维聚合计算,查询结果可视化功能;解决由于设备采集点数量巨大,数据采集频率高,造成的存储成本高,写入和查询分析效率低的问题。
Gorillas是一种内存数据库,新增加的数据会保存在内存中,然后每间隔一段时间,对这些数据进行压缩并写入磁盘,我们第一步所做的就是将这里的压缩功能在fpga上实现;先上个图,看一下阶段性效果:
1. 理论性能和实测性能对比
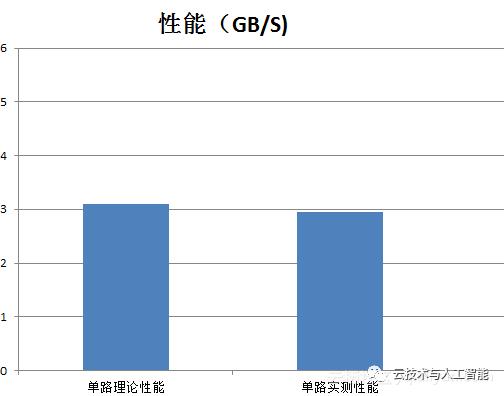
单路FPGA实现理论性能3.2GB/s,实测峰值性能2.97GB/s,达到峰值性能的约 94%
1. 单路FPGA实现和单线程CPU实现性能对比
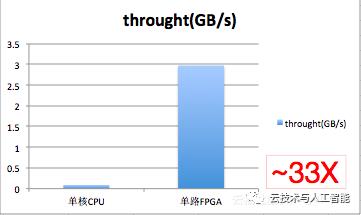
单核CPU压缩的实测性能大概为90M/s;目前FPGA单路实测峰值性能约3GB/s,性能提升约 33倍;
1. 单路FPGA实现占用资源情况

这里可以看到整个设计只用了7%的逻辑资源,包括DMA引擎和实现压缩功能的APP模块;另外我们的设计可以快速扩展到多路情况,目前最多支持4路并行,鉴于单路情况已经可以很好的处理目前业务需求,这里暂时没有扩展到多路。
1. 简单成本估算
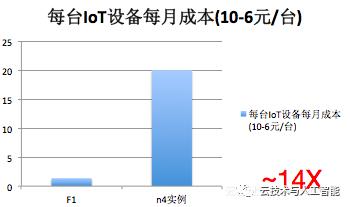
做个简单估算;单线程ECS性能为90M/s,使用共享计算型n4实例,1核2G,包月价格为116元;如果选择4核或者更多核时平均每个核价格会更便宜,单显然使用多核时性能也不会完全线性增加;FPGA使用阿里云官网F1实例,官网价格还没有给出来,但是我们内部有一个大致定价,另外其实我们只使用了F1的7%逻辑资源,也就是说这个FPGA实例还可以和其他应用共享一块FPGA。这这种保守估计下,使用FPGA实现成本仅为ECS成本的1/14。如果使用多路同时压缩,这个比例可以做到1/30。
——算法解释——
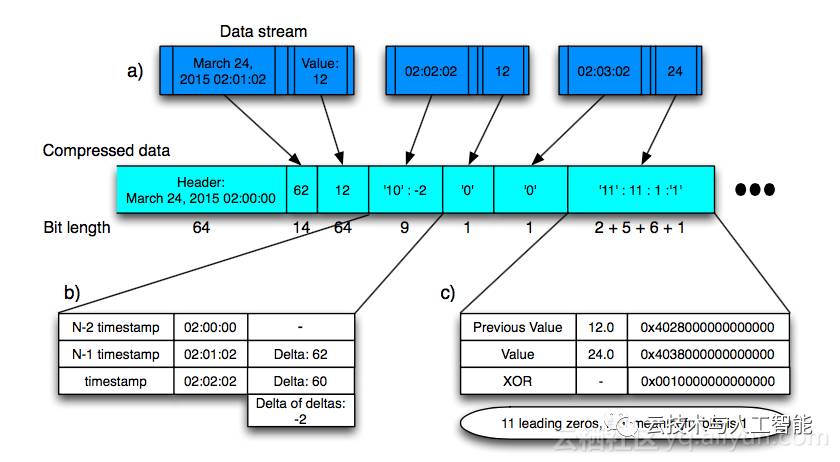
Gorillas算法主要包括两个部分,一是时间压缩,另一个是值的压缩,总体压缩过程如下:
——时间压缩——
时间用一个64 bit long long类型表示,压缩采用delta-of-delta算法,主要过程如下:

——值压缩——
值采用一个64bit的double类型表示,压缩采用xor编码形式

——FPGA实现方案——
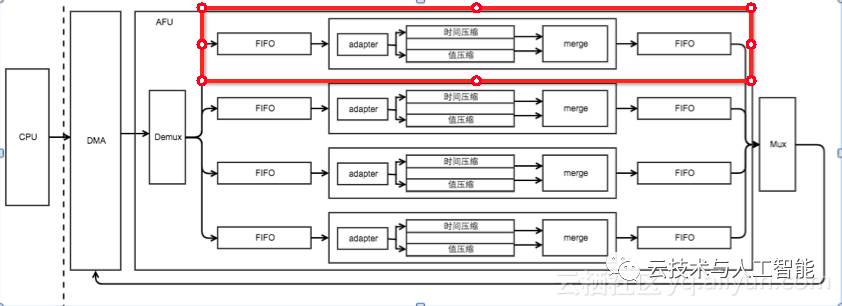
上图是阿里云异构计算设计的四路同时压缩的方案,但是考虑到业务需求,目前实际上只用了一路的压缩单元,剩下的逻辑可以给其他应用使用。当前设计的结构如下:
主要包括从host 内存读写数据的DMA引擎和完成压缩的AFU两部分。
——DMA引擎——
DMA引擎主要是从host内存读写数据,这部分后续会专门绍。
——AFU部分——
NO.1 FIFO
在整个设计中有两个时钟域,分别是DMA引擎使用的400M 时钟和AFU使用的200M 时钟,学过硬件设计的应该都知道对于这种跨时钟域问题最常见的问题就是异步FIFO了,因此本设计中有两个FIFO,分别是从DMA中读取数据和往FIFO中写入数据,这里的FIFO使用altera dcfifo IP。
NO.2 adapter
考虑到DMA数据位宽为512时性能最佳,因此本设计中DMA读写数据位宽为512,同时两个异步FIFO宽度也为512 。但是我们压缩数据时候是一个time和一个value同时压缩,只有128bit,因此在数据进入压缩单元前有一个512转128的adapter;另外time和value压缩后长度是未知的,这里通过另外一个adapter将压缩后的结果拼接成512bit后再写到FIFO中;
NO.3 核心压缩单元
核心压缩单元包括时间压缩(采用delta-of-delta)和值压缩(xored encoded),时间压缩部分使用openCL完成,本设计中只有这一单元采用了openCL,其他单元均采用verilog实现。硬件实现完全兼容软件,因此硬件压缩后的数据使用软件也可以解压!
FPGA在一些特定的场景下还是有比较大的优势的,在本项目中,使用FPGA实现轻松的可以提升30多倍性能。另外现在各家的HLS支持越来越好,通过C/C++,软件开发人员也可以快速的来开发FPGA应用了,本项目中时间压缩模块就是采用openCL实现。
期待和你摩擦出火花
阿里云飞天八部异构计算组致力于在阿里云上提供完善的FPGA开发环境和IP生态,欢迎有FPGA开发经验的小伙伴加入;同时也欢迎有性能加速需求的效果小伙伴勾搭,阿里云小伙伴期待和大家一起研究这个应用是否适合在FPGA上实现,如果适合,阿里云小伙伴会帮忙把应用移植到FPGA上来实现!
以上是关于时间序列数据库(HiTSDB)压缩算法的FPGA加速的主要内容,如果未能解决你的问题,请参考以下文章