行业动态——时间序列数据库在风电数据存储领域的应用
Posted 深能南京能源控股有限公司
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了行业动态——时间序列数据库在风电数据存储领域的应用相关的知识,希望对你有一定的参考价值。
风电行业作为新能源的代表,有海量的风电设备数据可以被采集使用。大数据技术的发展和成熟,已不局限于集控这样的数据应用场景。除了集控,风机的设备数据,以及SCADA系统产生的数据可以有更多直接产生价值的场景:
1.发电量统计、能效分析等BI场景
2.设备健康状况监控和监测
3.故障关联分析
4.设备故障预测
5.业务管理优化
为了支撑这些数据驱动的应用场景,需要整合多维度的生产经营数据以及更细粒度的秒级、甚至毫米级数据。在风电这种典型的工业大数据场景,数据平台架构可以基于数据特征进行优化,更加友好的支持实时、并发读写,以及横向扩展。
对于风机数据的存储,数据主要来源于SCADA系统和从传感器得到的数据是连续的、带有时间戳的变量。在算法分析领域,这类数据作为时间序列数据来处理,在数据库领域,时间序列数据有在监控领域广泛使用。时间序列数据库的应用场景可以从监控领域实践到到工业领域。基于时间序列数据库,设计实时收集、存储、分析的服务架构。本文主要介绍风电SCADA数据的实时采集和存储。
01
时间序列数据和SCADA数据
我们一般把符合下述特征的数据归纳为时间序列数据:
1.随时间连续度量,每个时间点都有值
2.度量值等时间隔变化(如秒,毫秒等)
3.有明确意义的度量变量(如温度,风速等)
在金融股票、IoT设备、车辆驾驶、医疗诊断等场景,遍布时间序列数据的场景。风电的SCADA系统收集的数据,就是符合时间序列数据定义的数据,而且数据特征更具体:
a. 低频的秒级数据和高频的毫秒级数据都具备
b. 设备数据、环境数据、发电量数据等都有真实意义和利用价值
c. 以数值型为主,并且在一定范围内波动变化
d. 数据每时每刻产生,但是系统采集会时有时无
e. 数据质量时好时坏
基于这样的特征,我们定义为时间序列数据模型来处理,选型合适的数据库组件,达到更高效的数据写入、压缩存储,和弹性的数据标识、管理。
02
时间序列数据库和OpenTSDB
时间序列数据库是基于时间戳作为索引优化存储的数据集合。相比于传统的关系型数据库,时间序列数据库的处理场景主要体现在以下几个方面:
1.相比于读,写是系统的主要任务
2.append方式处理数据
3.单点的读写少,往往是一段时间范围的批量写和读
4.更新和删除场景少
传统的做法是关系型数据库通过调优,优化时间序列数据的存储管理。关系型数据库如Oracle、mysql、PostgreSQL是处理通用场景而设计的,开销比较重。我们知道NoSQL类的数据库往往是专门来处理具体场景的轻量数据库,时序数据库的产生是为了重新设计数据库适应上面的技术需求,以NoSQL形态为主。
时间序列数据库是比较年轻的数据库,设计实现上更加新颖,如列式存储、REST API接口、异步通信、分布式存储等都有广泛使用。
数据模型上,时序数据的字段往往如下定义:
metric:具体的变量名。每个metric代表一类度量值,如偏航功率、环境温度、机舱温度等;
timestamp:时间戳,标识时间维度,可能是秒,也可能是毫秒,作为KV数据对中的key;
Value:变量值。跟时间戳一起组成KV数据对,Value标识具体时间点的变量值;
TagKey/TagValue:TagKey和TagValue组成一对描述数据的标签,比如数据是属于哪个风机的,是哪个系统采集的等,通过tag补充标注。一个KV数据对,可以有无数个TagKey/TagValue描述,根据需要扩展完整的数据画像。
具体到每个时序数据库产品,设计理念不完全相同。当前流行的时序数据库有InfluxDB、OpenTSDB、Prometheus、Druid等,有些数据库如Kdb+、RRDTool虽然在db-engines中排名靠前,但是当前流行的技术方案中提及的较少。
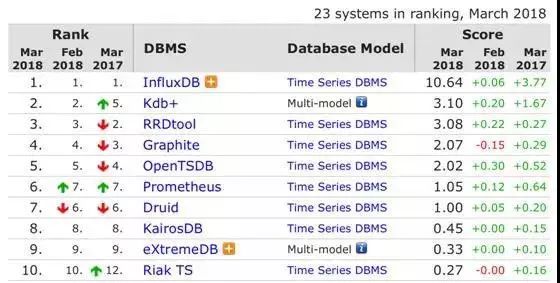
图1:db-engines.com网站时序数据库的排名
在我们的平台产品中,使用的是时间序列数据库OpenTSDB。OpenTSDB是时序数据库领域中比较早发布并且有广泛生产环境实践的产品。当前最新的稳定版本是2.3,通过OpenTSDB的官网http://opentsdb.net/可以了解具体的特性和实现。

图2:OpenTSDB的官网首页
OpenTSDB以KV数据库HBase作为存储后端,可满足存储的横向扩展。对元数据的管理和数据存储上有存储优化的设计,是HBase的一大优势。
1. 通过为每个metric、tag key和tag value设计一个固定3byte的UID缩短Rowkey的长度;
2. 支持一个时间段内的数据进行整合后存储,如将一小时3600个数据点合并成一个点,来节省Rowkey的数量。
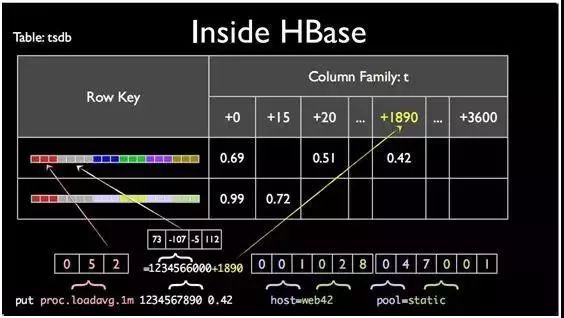
图3:OpenTSDB内部的存储机制
我们选择OpenTSDB,除了上述自身的特性外,还考虑以下几点:
1) 支持横向扩展,当前流行的时序数据库中,大都没有支持或者没有开源分布式组件;
2) OpenTSDB的后端存储使用的是HBase和HDFS,并且注册到Zookeeper进行管理,所以跟Hadoop生态圈融合的比较好,可以复用大数据平台组件,和其他大数据平台耦合;
3) 开源的时序库,根据行业需求进行定制化开发。比如,我们根据风电数据存存在连续重复的可能,加入新的存储优化设计。
OpenTSDB提供了REST API和CLI工具来提供数据读写的接口,后台跟HBase的通信通过优化的AsynHbase库来完成,比HBase原生的接口性能提升2被以上。以OpenTSDB作为存储引擎,加上数据采集模块和流处理模块就可以实现数据的实时收集存储。
03
实时数据计算存储平台
工业大数据的数据服务场景,主要体现在实时性、安全性和稳定性上。
实时性:使用Streaming技术对数据实时计算、转换和写入落盘
安全性:兼容各种网络安全设备的数据传输
稳定性:充分考虑数据质量和设备状况、政策对数据采集流程的干扰
针对SCADA的数据收集,风场的数据通过日志文件穿越电网传回数据中心,在数据中心建设大数据平台,对日志文件进行监控收集和解析存储。平台中主要的组件有:
Flume:从风场传来的日志文件的监控和收集
Kafka:风机日志文件的缓存和中间结果的保存
SparkStreaming:风机日志文件的实时获取和预处理
OpenTSDB+HBase+HDFS:数据的存储和扩展
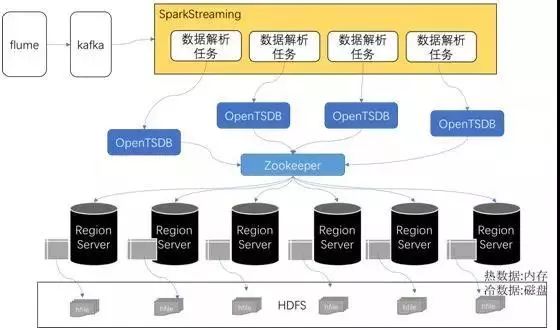
图4:基于SparkStreaming和OpenTSDB的IoT实时数据平台
SparkStreaming的任务受OpenTSDB+HBase存储层的响应情况影响。为提升整个架构的容错和稳定,我们开发了一个组件来优化OpenTSDB的访问服务。在OpenTSDB节点负载过重或出现故障时,及时将计算节点连接到另一个健康的OpenTSDB节点,并且对这样的故障增加报警与错误记录,以通知到运维人员并为错误分析、调优提供原始记录。
04
风电企业数据治理:异构数据平台建设
SCADA经由时序数据库存储后,可为集控系统、BI以及AI模型开发提供高效的数据平台服务。单一的设备数据源有时不能满足复杂业务模型的开发,除了SCADA,企业往往还有更多的业务系统和数据源可以集成共享,如MES、ERP等。罗马不是一天建成的,通过数据治理理念,逐渐完善数据平台的服务种类,篇幅有限本文不做过多说明。
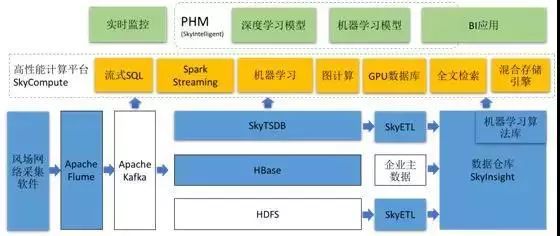
图6:天数润科风电数据平台
风电行业在过去10年得到了巨大的发展,运营中的设备数巨大,同时也迎来运维为主的新产业周期。在政策和市场的驱动下,行业内的技术交流和合作的促进下,精益管理的需求势必推动整个行业数字化转型。作为IT人,我们希望能通过深耕风电行业,提供成熟先进的数字化服务,为清洁能源的普及增长和碧水蓝天的美好生态贡献自己一份力量,实现共赢。
(来源:每日风电)
以上是关于行业动态——时间序列数据库在风电数据存储领域的应用的主要内容,如果未能解决你的问题,请参考以下文章