时间序列预测多元线性回归模型
Posted 哈希大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了时间序列预测多元线性回归模型相关的知识,希望对你有一定的参考价值。
多元线性回归,“多元”是指有多个自变量。多元回归的基本模型:
对于简单线性模型的误差项的基本假设:
(1) 误差均值为0;
(2) 误差之间不相关;
(3) 误差与自变量不相关;
(4) 误差服从正态分布
本文将基于两个例子讲解多元线性回归:
Example1: 澳大利亚银行信用评分
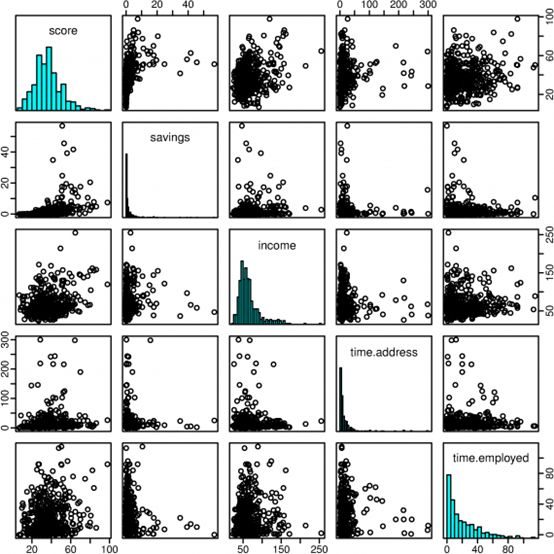

上图是有四个自变量的信用评分的散点矩阵(Scatterplot matrix)。数据来源:澳大利亚银行500个用户的信用评分数据。
从上图中,我们很难看到自变量和因变量的关系,现在我们使用log(x + 1)变换: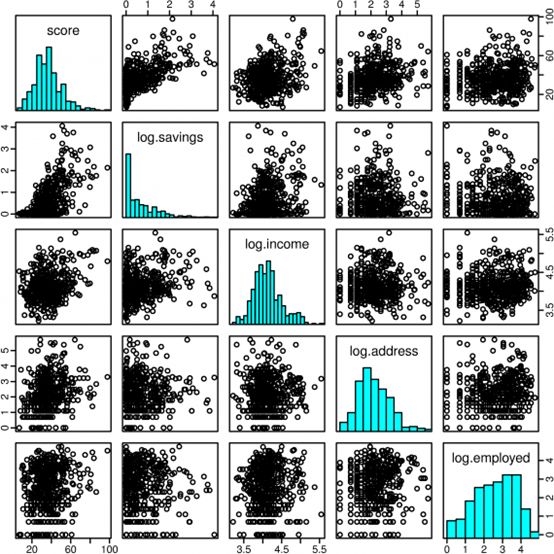
经过变换,变量之间的关系变得比较清晰,使用多元线性模型:
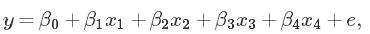
模型参数估计:
通过计算误差平方和的最小值来估计模型系数:β0,…,βk,计算方法如下:
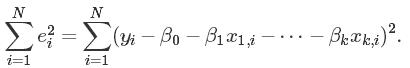
R语言有线性回归模型的package,可以直接使用:
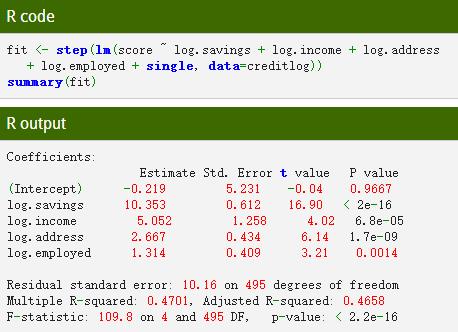
计算R2,度量预测值和真实值的关系:
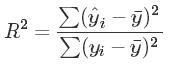
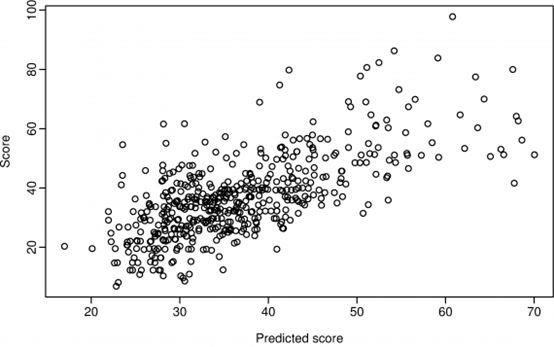
R2=0.47,即可以使用这个模型预测信用评分大约一半的变化。因此这个模型只能用于筛选出信用评分很低的一部分用户。由上图可以看出,预测值低于35的人数少于60人,因此银行可以使用这个模型作为初步筛选,预测精度高的模型需要收集客户更多的资料。
在例1中,我们假设自变量都是数值变量(numerical),但实际预测中会常常遇到二元变量(是,否),例如在例1中我们加入“顾客是否被雇佣”,因此我们需要引入哑元变量(dummy variable)。
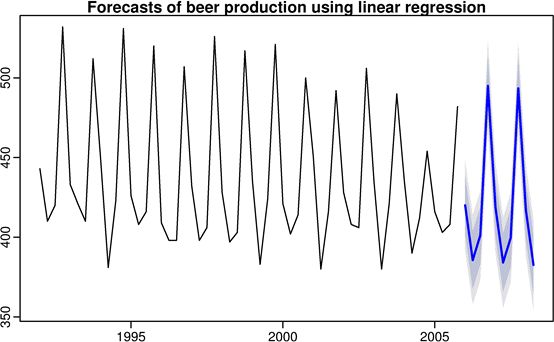
Example2: 澳大利亚啤酒产量预测
根据澳大利亚啤酒产量数据,引入季节性哑元变量建立线性模型:
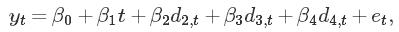
计算结果显示:每季度的啤酒产量具有显著的下降趋势(0.382兆加仑)。第二季度产量比第一季度减少34.0兆加仑,第三季度产量比第一季度减少18.1兆加仑,第四季度产量比第一季度增加76.1兆加仑。 R2=0.921,该模型解释了啤酒产量数据变化的92.1%。
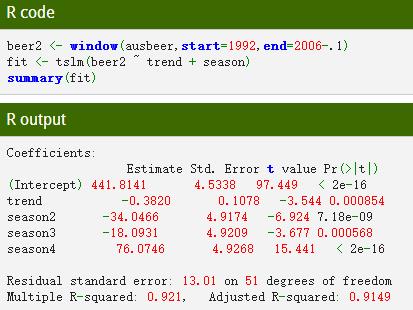
实际产量数据与预测数据对比:
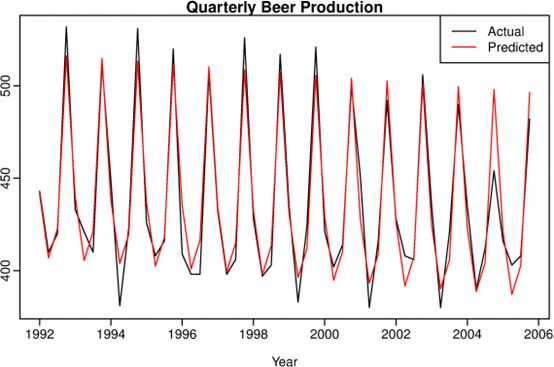
 预测回归模型
预测回归模型
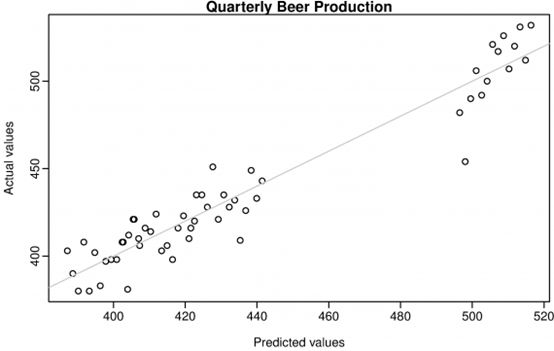

根据模型,带入参数预测啤酒产量(灰色区域显示80%预测区间,淡蓝色区域显示95%预测区间):

选择自变量
选择自变量的方法有很多,最常用的散点矩阵图很难判断变量之间的关系,另外一个常用的方法是根据变量的P-value,P大于0.05代表统计性显著(可以选择该变量),当两个或更多变量之间有相关关系,P值就很难作为判断依据。
因此,我们需要使用新的方法,例如:Adjusted R2,交叉验证(Cross-validation),AIC(Akaike's Information Criterion),Corrected Akaike's Information Criterion,BIC(Schwarz Bayesian Information Criterion)等方法。
残差分析(Residual diagnostics)
在选择回归变量并拟合回归模型之后,需要绘制残差图以检查模型的假设是否已经满足。 为了检查拟合模型和模型基本假设,应该制作一系列图表。
自变量残差散点图
对模型中的每个预测变量绘制残差散点图。如果这些散点图显示变量关系是非线性的,那么需要对模型做一定的修改。 除此之外,也要绘制除不包含在模型中的其它变量的残差图,如果结果显示变量具有相关关系,那么需要将预测变量添加到模型中(可以是非线性形式)。
上图显示了信用评分模型自变量的残差,储蓄预测变量的大值的残差往往是负的。 这表明对于有大量储蓄的人来说,信用评分往往被高估。为了纠正这种偏差,我们需要使用非线性模型。
其他残差诊断,例如因变量残差散点图,残差自相关,残差直方图等,由于篇幅所限,不再详细介绍。
不要错过
以上是关于时间序列预测多元线性回归模型的主要内容,如果未能解决你的问题,请参考以下文章