一文看懂Pinterest如何构建时间序列数据库系统Goku
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文看懂Pinterest如何构建时间序列数据库系统Goku相关的知识,希望对你有一定的参考价值。
虽然 OpenTSDB 在功能上运行良好,但其性能随着 Pinterest 的增长而降低,导致运营开销(例如严重的 GC 问题和 HBase 经常崩溃)。为了解决这个问题,Pinterest 开发了自己的内部时间序列数据库——Goku,其中包含用 C ++ 编写的 OpenTSDB 兼容 API,以支持高效的数据提取和成本昂贵的时间序列查询。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
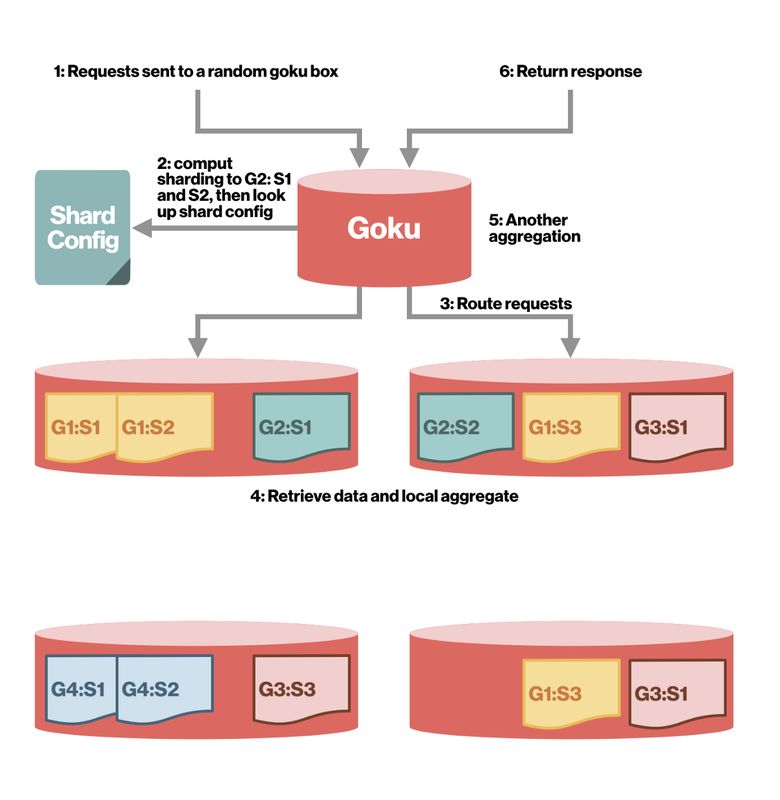
(使用 Goku 进行两级分片)
Goku 遵循 OpenTSDB 的时间序列数据模型。时间序列由一个键和一系列时间数字数据点组成。key = metric name + 一组标记键值对。例如,“tc.proc.stat.cpu.total.infra-goku-a-prod {host = infra-goku-a-prod-001,cell_id = aws-us-east-1}”。数据点 = 键 + 值。值是时间戳和值对。例如,(1525724520,174706.61),(1525724580,173456.08)。
除了开始时间和结束时间之外,每个查询都由以下部分或全部组成:度量标准名称、过滤器、聚合器、降采样器、速率选项。
1)度量名称示例:“tc.proc.stat.cpu.total.infra-goku-a-prod”。
2)对标记值应用过滤器,以减少在查询或组中拾取系列的次数,并在各种标记上聚合。Goku 支持的过滤器示例包括:完全匹配、通配符、Or、Not 或 Regex。
3)聚合器规定将多个时间序列合并为单个时间序列的数学方法。Goku 支持的聚合器示例包括:Sum、Max / Min、Avg、Zimsum、Count、Dev。
4)降采样器需要一个时间间隔和一个聚合器。聚合器用于计算指定时间间隔内所有数据点的新数据点。
5)速率选项可选择计算变化率。有关详细信息,请参阅 OpenTSDB 数据模型(http://opentsdb.net/docs/build/html/user_guide/query/index.html)。
Goku 解决了 OpenTSDB 中的许多限制,包括:
1)不必要的扫描:Goku 用倒排索引引擎取代了 OpenTSDB 的低效扫描。
2)数据大小:OpenTSDB 中的数据点是 20 字节。Pinterest 采用 Gorilla 压缩来实现 12 倍压缩。
3)单机聚合:OpenTSDB 将数据读取到一个服务器上并进行聚合,而 Goku 的新查询引擎是将计算迁移到更接近存储层的位置,该存储层在叶节点上进行并行处理,然后在根节点上聚合部分结果。
4)序列化:OpenTSDB 使用 JSON,当有太多数据点要返回时,JSON 会很慢;Goku 使用 thrift 二进制代替。
Goku 在内存存储引擎中使用了 Facebook Gorilla 来存储过去 24 小时内的最新数据。
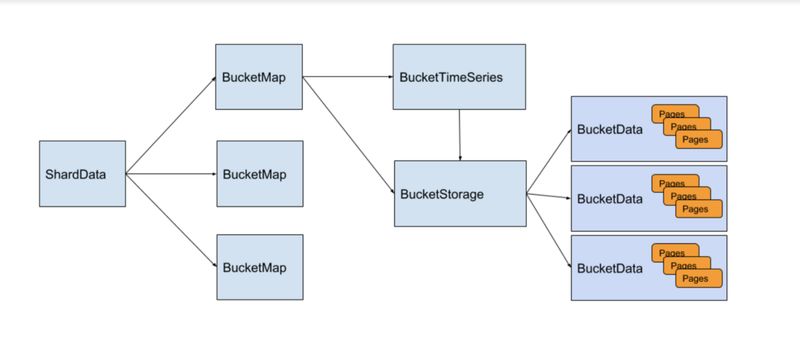
(存储引擎简介。请查看 Gorilla 论文(http://www.vldb.org/pvldb/vol8/p1816-teller.pdf) 及其 GitHub 存储库(https://github.com/facebookarchive/beringei) 来了解详细信息)
如上所述,在存储引擎中,时间序列被分成称为 BucketMap 的不同分片。对于一个时间序列,也被分为可以调整时长的 bucket(Pinterest 内部以每 2 小时为一个 bucket)。在每个 BucketMap 中,每个时间序列都被分配一个唯一的 ID 并链接到一个 BucketTimeSeries 对象。BucketTimeSeries 将最新的可修改缓冲区存储区和存储 ID 保存到 BucketStorage 中的不可变数据存储区。在配置存储 bucket 时间之后,BucketTimeSeries 中的数据将被写入 BucketStorage,变为不可变数据。
为了实现持久性,BucketData 也会写入磁盘。当 Goku 重新启动时,它会将数据从磁盘读入内存。Pinterest 使用 NFS 来存储数据,从而实现简单的分片迁移。
我们使用两层分片策略。首先,我们对度量名称进行散列,以确定某一时间序列属于哪个分片组。我们在度量名称 + 标记键值集上进行散列,以确定时间序列在所在组中的哪个分片。此策略可确保数据在分片之间保持平衡。同时,由于每个查询仅进入一个组,因此扇出保持较低水平,以减少网络开销和尾部延迟。另外,我们可以独立地扩展每个分片组。
倒排索引
Goku 通过指定标记键和标记值来支持查询。例如,如果我们想知道一个主机 host1 的 CPU 使用率,我们可以进行查询 cpu.usage {host = host1}。为了支持这种查询,Pinterest 实现了倒排索引。(在 Pinterest 内部,它是从搜索项到位集的散列映射。)搜索项可以是像 cpu.usage 这样的度量名称,也可以是像 host = host1 这样的标记键值对。使用这个倒排索引引擎,我们可以快速执行 AND、OR、NOT、WILDCARD 和 REGEX 操作,与原始的基于 OpenTSDB 扫描的查询相比,这也减少了许多不必要的查找。
聚合
从存储引擎检索数据后,开始进行聚合和构建最终结果的步骤。
Pinterest 最初尝试了 OpenTSDB 的内置查询引擎。结果发现,由于所有原始数据都需要在网络上运行,性能会严重下降,而且这些短期对象也会导致很多 GC。
因此,Pinterest 在 Goku 中复制了 OpenTSDB 的聚合层,并尽可能地早地进行计算,以尽量减少线上的数据。
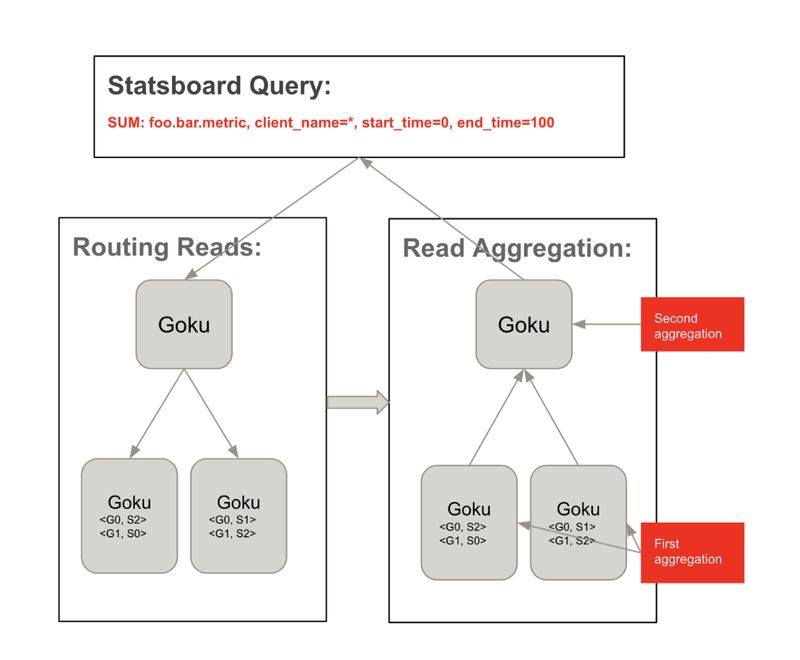
典型的查询流程如下:
用 Statsboard 客户端查询(Pinterest 的内部度量监控 UI)任何代理 goku 实例
代理 goku 基于分片配置将查询扇出到同一组内的相关 goku 实例
每个 goku 读取倒排索引以获取相关的时间序列 ID 并获取其数据
每个 goku 基于查询聚合数据,如聚合器、降采样器等
代理 goku 在收集每个 goku 的结果并返回客户端后进行第二轮聚合
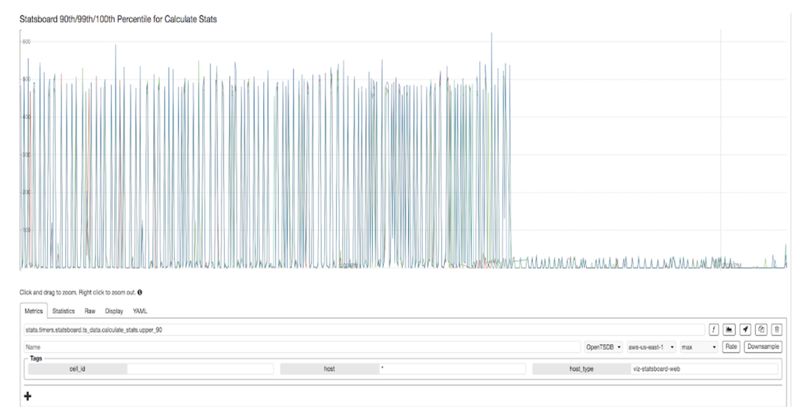
与之前使用的 OpenTSDB / HBase 解决方案相比,Goku 在几乎所有方面都表现更好。

另一个在使用 Goku 前后高基数查询延迟对比图,如下图所示:
Goku 最终将支持超过一天时间数据的查询。对于像一年这样的时长查询,Pinterest 将不会过分强调一秒钟内发生的事情,而是关注整体趋势。因此,Pinterest 将进行降采样和压缩,把以小时计的 bucket 合并为更长期的时长,从而减小数据量并提高查询性能。
(Goku 阶段#2——基于磁盘:数据包括索引数据和时间序列数据)
目前,Pinterest 有两个 goku 集群进行双行写入。此设置提高了可用性:当一个集群中存在问题时,可以轻松地将流量切换到另一个集群。但是,由于这两个集群是独立的,因此很难确保数据的一致性。例如,如果写入一个集群成功而另一个未成功时,则数据写入失败,数据由此变得不一致。另一个缺点是故障转移总是在集群层面发生。为此,Pinterest 正在开发基于日志的集群内复制,以支持主从分片。这将提高读取可用性,保持数据一致性,并支持分片级的故障转移。
所有行业都需要广泛的分析,Pinterest 也不例外,例如面临询问实验和广告推广效果等问题。目前,Pinterest 主要采用离线作业和 HBase 进行分析,这意味着不会有实时数据产生,并避免大量不必要的预聚合。由于时间序列数据的性质,Goku 可以很容易地适应它,不仅可以提供实时数据,还可以提供按需聚合。
Pinterest 表示将继续探索 Goku 的用例,如果你对此类项目感兴趣,请查看:https://careers.pinterest.com/careers/engineering。
原文链接:
https://medium.com/@Pinterest_Engineering/goku-building-a-scalable-and-high-performant-time-series-database-system-a8ff5758a181
如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!
以上是关于一文看懂Pinterest如何构建时间序列数据库系统Goku的主要内容,如果未能解决你的问题,请参考以下文章