一文看懂大数据量表如何优化
Posted H_Jason_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文看懂大数据量表如何优化相关的知识,希望对你有一定的参考价值。
1、造数准备
1、线程池造数
数据库脚本:
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`username` varchar(100) DEFAULT NULL COMMENT '姓名',
`sex` varchar(2) DEFAULT NULL COMMENT '性别',
`age` int(3) DEFAULT NULL COMMENT '年龄',
`phone` varchar(12) DEFAULT NULL COMMENT '手机号',
`address` varchar(100) DEFAULT NULL COMMENT '家庭住址',
`deptid` int(11) DEFAULT NULL COMMENT '归属部门ID',
`udesc` varchar(255) DEFAULT NULL COMMENT '个人描述',
`createtime` datetime DEFAULT NULL COMMENT '创建时间',
`school` varchar(255) DEFAULT NULL COMMENT '毕业院校',
`major` varchar(255) DEFAULT NULL COMMENT '专业名称',
`nationality` varchar(255) DEFAULT NULL COMMENT '国籍',
`nation` varchar(255) DEFAULT NULL COMMENT '民族',
`idcard` varchar(255) DEFAULT NULL COMMENT '身份证号码',
`qq` varchar(255) DEFAULT NULL COMMENT 'QQ号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户信息表';
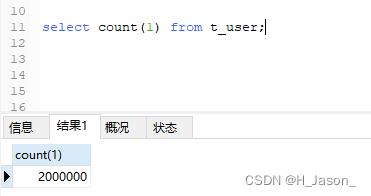
课件中有造数的代码,是通过线程池的方式往数据库添加200万数据,执行完毕后,数据库就有数据了:
2、函数造数
首先新建下面函数:
CREATE FUNCTION `insert_user`(`num` int) RETURNS int(11)
BEGIN
DECLARE i int DEFAULT 0;
WHILE i<num DO
if i % 2 = 0 then
INSERT into t_user (username, sex, age, phone, address, deptid, udesc, createtime, school, major, nationality, nation, idcard, qq)
VALUES (concat('张三', i, '号'), '男', FLOOR(RAND()*100), CONCAT('18',FLOOR(rand()*(999999999-100000000)+100000000)), '湖北省武汉市江汉路191号', 25, '我是一个好人', NOW(), '武汉大学', '计算机应用技术', '中国', '汉族', '429004155130213602', '1134135987');
ELSE
INSERT into t_user (username, sex, age, phone, address, deptid, udesc, createtime, school, major, nationality, nation, idcard, qq)
VALUES (concat('李四', i, '号'), '女', FLOOR(RAND()*100), CONCAT('18',FLOOR(rand()*(999999999-100000000)+100000000)), '湖北省武汉市江汉路192号', 26, '我是一个老好人', NOW(), '北京大学', '计算机网络技术', '中国', '回族', '429004155130213603', '1134135988');
end if;
set i = i+1;
END WHILE;
RETURN i;
END
然后运行函数,入参给200万,执行结果:
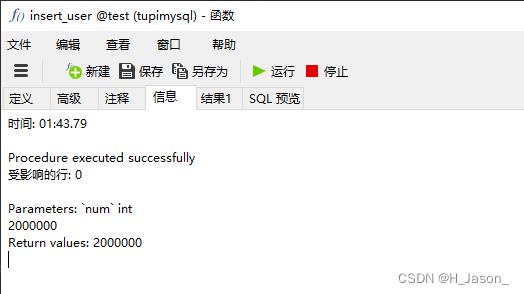
速度还行,100秒左右
2、SQL测试
1、示例SQL
好,现在数据库表已经有200万数据了,我们执行下面SQL试试,从第一条数据开始,偏移50条数据:
select * from t_user where sex = '男' limit 0, 50;
查询结果:

耗时0.035秒,速度还是可以的
2、问题出现
好,那么我们现在模拟查找很多页之后的数据,120W 条后,偏移50条数据,下面SQL执行一下:
select * from t_user where sex = '男' limit 900000, 50;
查询结果:
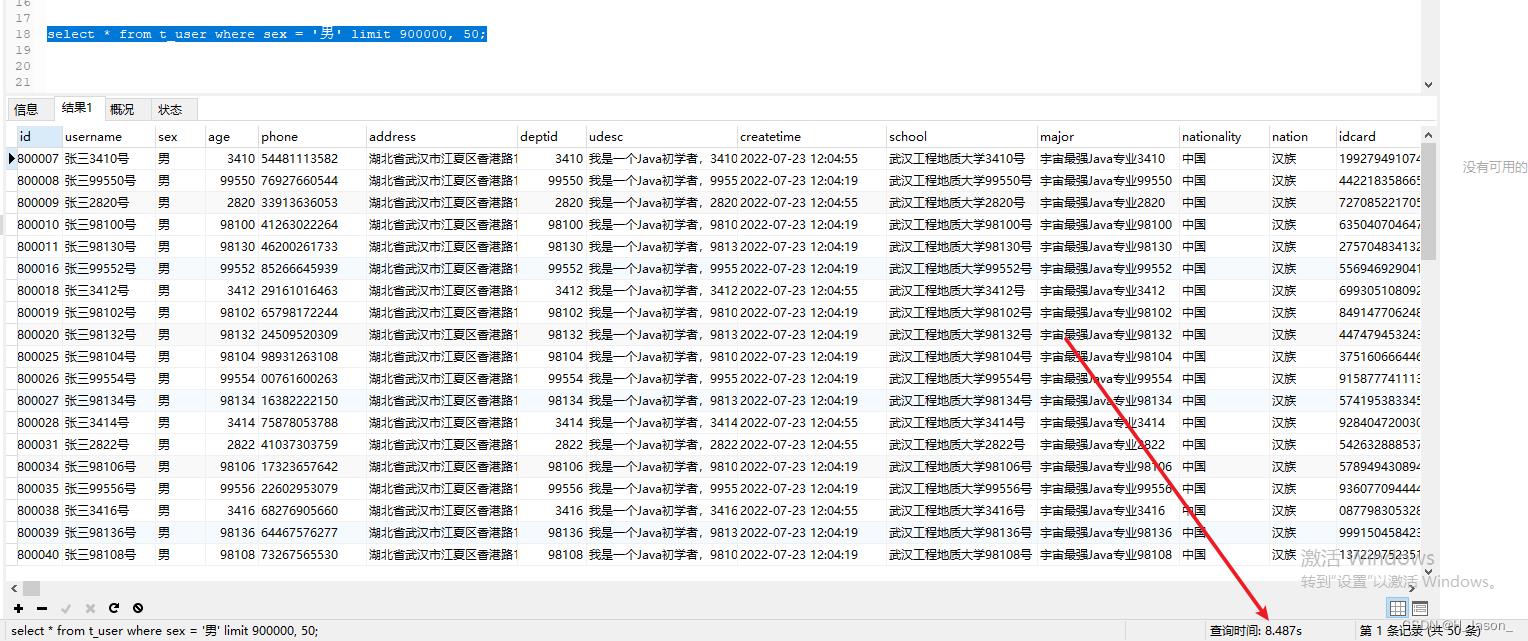
此次查询确耗时8.487秒,这已经很慢了,这是为什么呢?
3、原因分析
此时为了分析出原因,我们可以先查看一下解释执行计划,在SQL前面加上【explain】关键字即可,如下:
explain select * from t_user where sex = '男' limit 900000, 50;
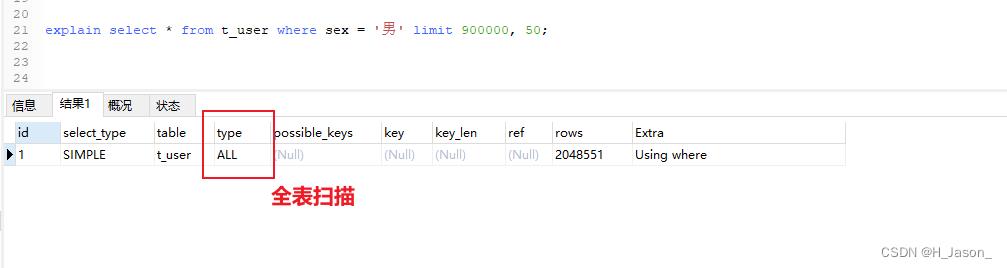
从执行结果可以看出,我们执行到SQL查询,走的是全表扫描,那肯定很慢了
怎么解决呢?
4、加索引还是有问题
第一时间肯定是加索引,让它走索引,查询速度才会提高,好,那我们就给sex字段加上索引:

注意:一般索引是在建表时就加好了的,我们现在加索引会很慢,因为库里面已经有200万数据了
好,现在我们再执行同样的SQL,看时间怎么样:
select * from t_user where sex = '男' limit 900000, 50;
执行结果:
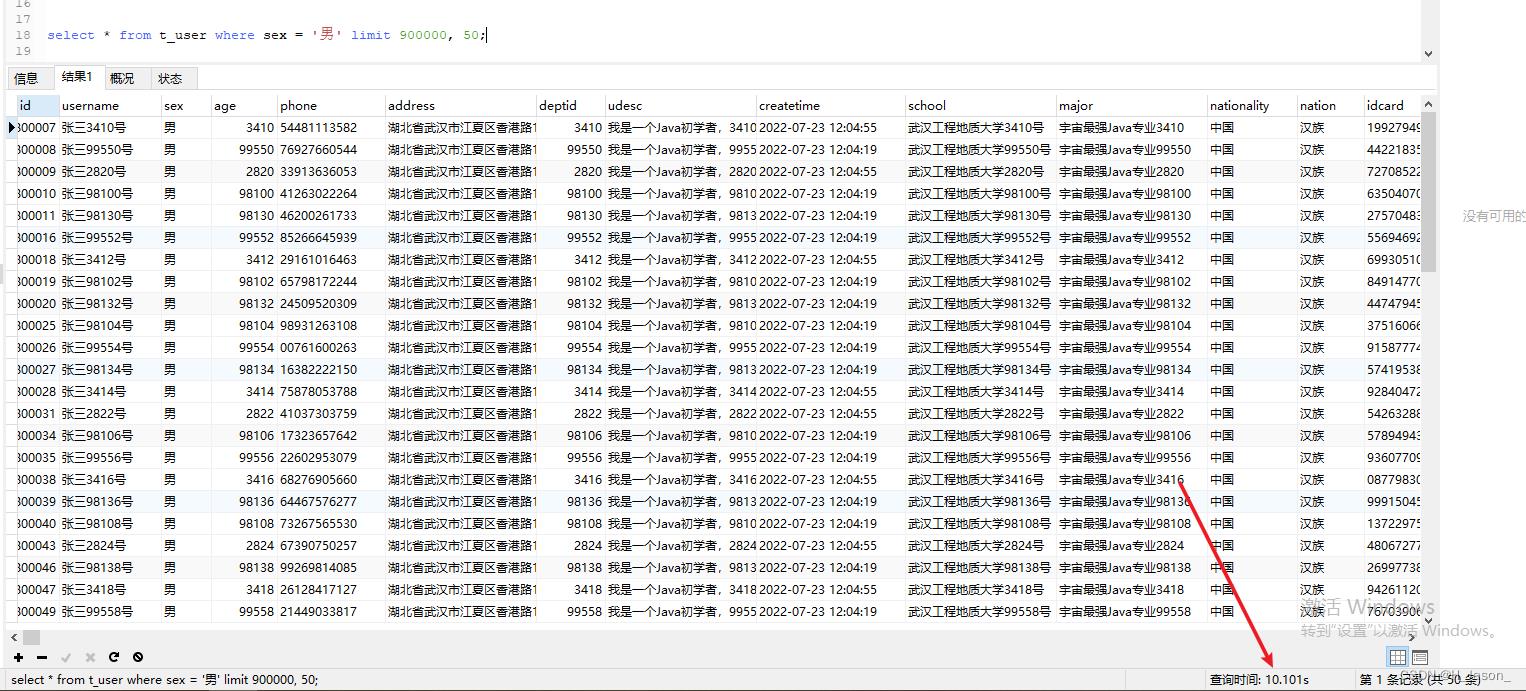
看结果就蒙圈了,居然建完索引后,查询时间反而增加了,这又是为什么呢?不是说索引可以提升查询效率吗?
我们先来看一下执行计划:
explain select * from t_user where sex = '男' limit 900000, 50;

5、原因分析
从上面执行计划可以看出,虽然已经命中了索引【idx_user_sex】,但还是比较慢,为什么呢?
原因如下:
-
idx_user_sex属于非聚簇索引(非聚集索引),而我们查询的语句是select *,包含了其他字段,通过非聚簇索引idx_user_sex查出来的数据列,只有sex和id、那么我们为了得到其他字段,就需要再根据id去查询其他字段值,这也就是回表操作
-
limit查询数据的规则,我们必须先弄清楚
比如说:limit m, n,流程是这样的:先确定SQL符合条件的数据,然后根据 m + n,计算出总共需要扫描拿到的数据总量是多少,再去从头开始遍历到m的数据行,开始丢到返回集,丢多少条呢? 丢n条
那么按照limit这样的规则,我们看下limit 0,50:
计算 0+ 50 =50 , 拿出符合条件的50条 , 从头开始匹对第一个数 0,OK,从0开始就可以把数据丢到返回集。
丢多少? 第二个数是 50,所以会一条条丢,丢50条 ,最后返回数据
再看下limit 900000,50:
90万+50=900050
意味着为了拿50条数据,需要扫描出 900050 条数据,然后迅速检索第一个数是90万,开始丢掉前面90万条没有意义的数据,然后确定第二个数是50,开始整50条数据丢到返回集里面,最后返回数据
我们发现,前90万查询时没有意义的
6、继续优化
先针对回表做优化,如果我们能拿到我们知道返回数据的 id 集,作为条件,这样通过命中非聚簇索引sex的时候,直接就能拿到id,这样通过id拿数据列,这样就方便了。
将上面SQL改造一下,如下:
select t1.* from (select id from t_user where sex = '男' limit 900000, 50) t2, t_user t1 where t2.id = t1.id
直接结果:
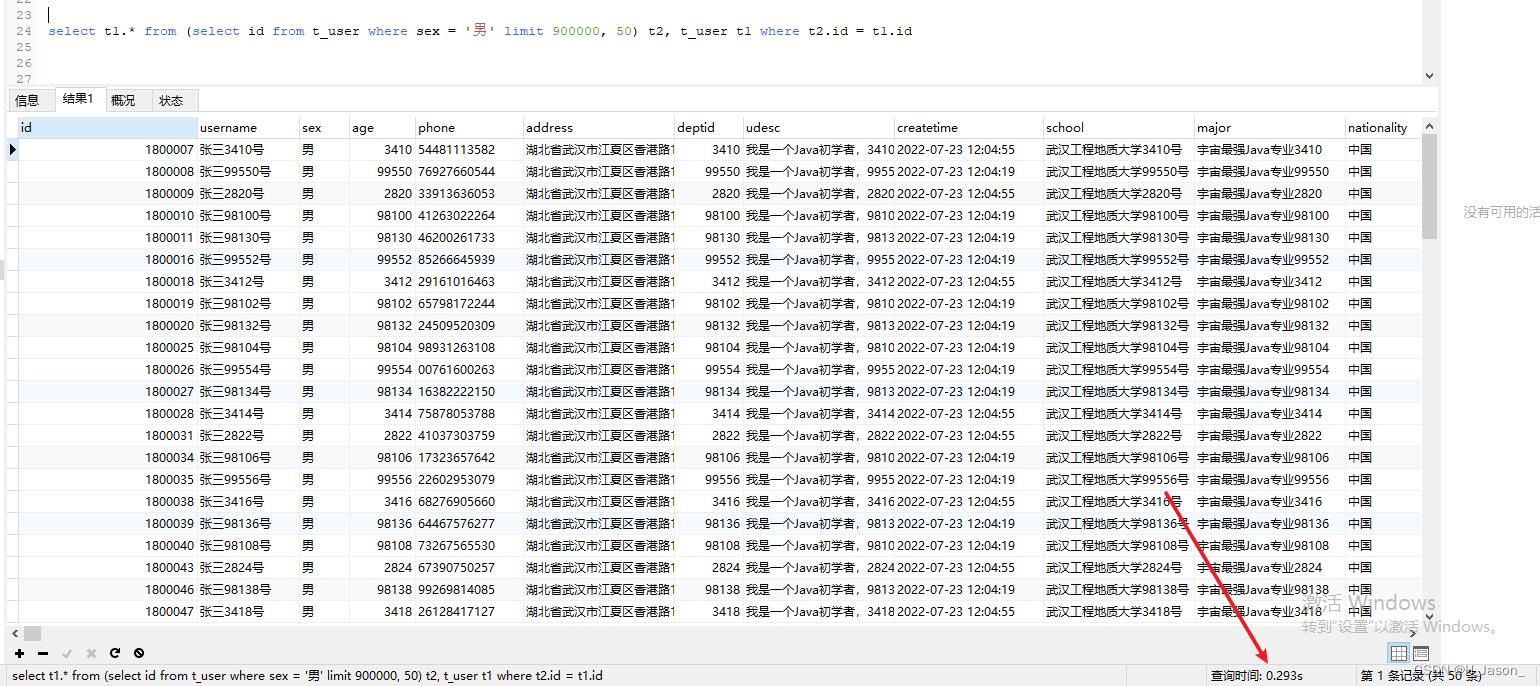
居然查出同样的数据,只需要0.293秒,查询速度确实提高了很多倍
我们再看看执行计划:
EXPLAIN select t1.* from (select id from t_user where sex = '男' limit 900000, 50) t2, t_user t1 where t2.id = t1.id
结果:
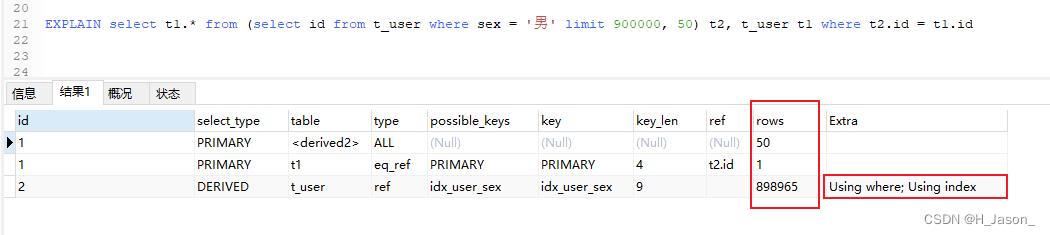
此时Extra指标中,既出现了【Using where】也出现了【Using index】,两者都出现表示:使用了覆盖索引,索引被用来执行索引键值的查找,效率不错
虽然rows值较大,但是使用了覆盖索引,所以查询效率极高
有些人喜欢用下面的写法:
select t.* from t_user t where t.id in(
select id from (select id from t_user where sex = '男' limit 900000, 50) u
)
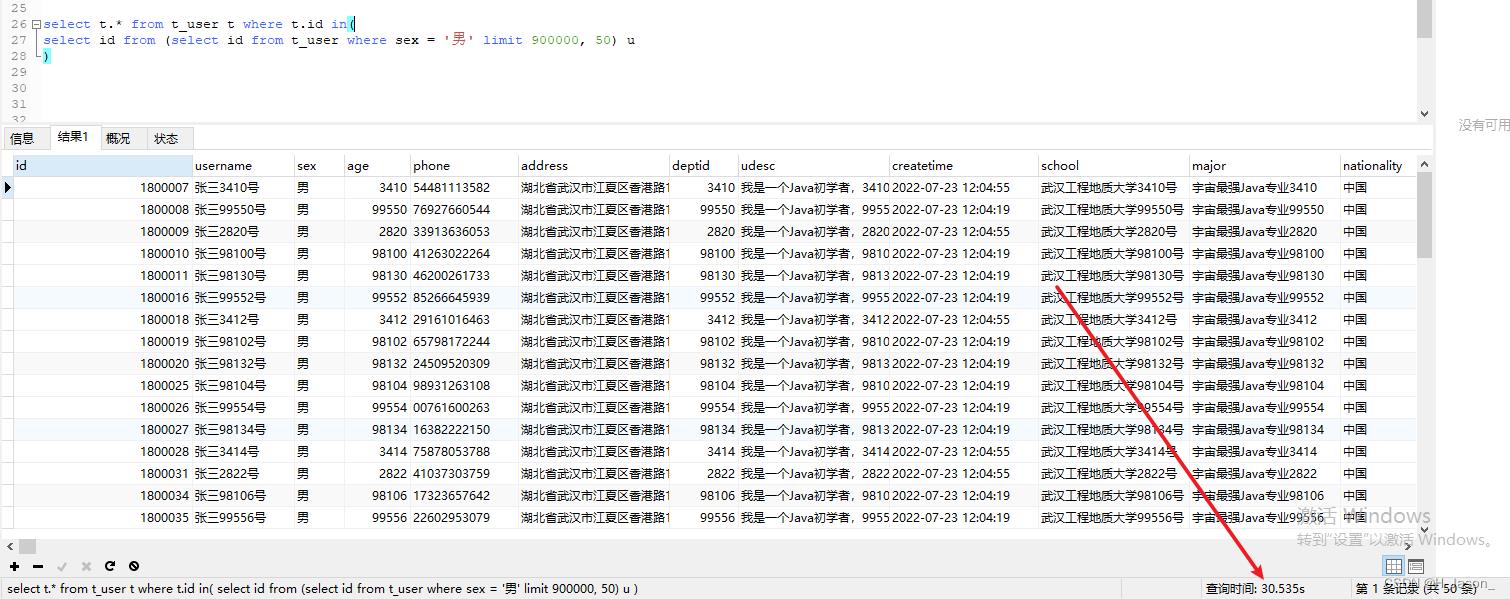
时间居然花的更久了,执行计划看下就明白了:

清楚的可以看到1797931行数据时需要全表扫的,那肯定慢了啊
7、深入优化
如果ID是连续的话,那我们就可以根据ID先过滤一次了,这个ID值的话,由前端每次翻页时传给后台即可
比如上一页最后一条记录到ID值为1800006,那么翻页时就可以执行下面SQL:
select * from t_user where id >= (select id from t_user where sex = '男' limit 900000, 1) limit 50;
执行结果:
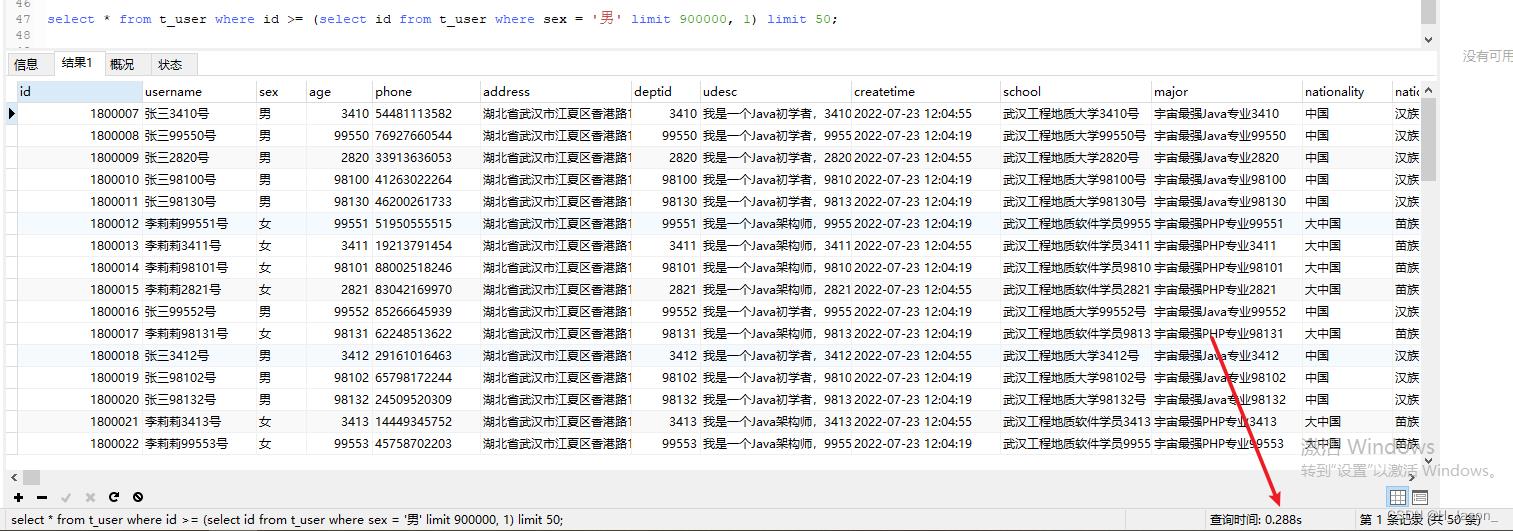
我们会发现,执行耗时确实更短了,随着数据量的增多,耗时差别会更加明显,再看下执行计划:

主键索引也命中了,所以效率更高了
总结
经过这次大数据量的分页查询,我们知道了在真实开发中,如何有效的利用索引帮助我们提高查询效率
1、延迟关联
先通过where条件提取出主键,在将该表与原数据表关联,通过主键id提取数据行,而不是通过原来的二级索引提取数据行,例如:
select t1.* from (select id from t_user where sex = '男' limit 900000, 50) t2, t_user t1 where t2.id = t1.id
2、书签方式
书签方式说白了就是找到limit第一个参数对应的主键值,再根据这个主键值再去过滤并limit,例如:
select * from t_user where id >= (select id from t_user where sex = '男' limit 900000, 1) limit 50;
0, 50) t2, t_user t1 where t2.id = t1.id
2、书签方式
书签方式说白了就是找到limit第一个参数对应的主键值,再根据这个主键值再去过滤并limit,例如:
```sql
select * from t_user where id >= (select id from t_user where sex = '男' limit 900000, 1) limit 50;
以上是关于一文看懂大数据量表如何优化的主要内容,如果未能解决你的问题,请参考以下文章