微软:云原生的MySQL托管服务架构及读写分离的优化
Posted IT大咖说
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微软:云原生的MySQL托管服务架构及读写分离的优化相关的知识,希望对你有一定的参考价值。

内容来源:2017 年 08 月 24 日,微软中国首席产品经理宋青见在“ODF 2017开源数据库论坛(北京)”进行《云原生的mysql托管服务架构及读写分离的优化》演讲分享。IT 大咖说(微信id:itdakashuo)作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数:4055 | 11分钟阅读
摘要
在私有数据中心运维MySQL的方式是单机运行、一主一备,甚至是多主复制的集群,为了保证高可用,成本是比较高的。而基于云计算,托管运维大量的用户MySQL实例,如何用Cloud Native的原则,通过沙箱隔离、计算和数据的完全分离,实现低成本和高扩展的高可用方案?通过开篇分享,使大家更好的理解Cloud RDS的架构精髓。进而通过基于Azure storage的针对MySQL读写分离的优化,比较深入的分享了一种可以借鉴的主从分离优化技术。
获取嘉宾演讲视频及PPT,扫一扫下方二维码即可。

云原生的托管服务架构
我们的MySQL托管运维并非直接将数据存储在本地SSD,而是所有的连接都需要经过一层代理(可以理解为无状态的外部服务器),然后由代理将用户的连接转发到某一个虚拟机中的MySQL实例上。每个虚拟机上有一个Agent用来监控运行的MySQL服务状态,如果其中某个数据库出现问题,就会在其他的虚拟机上恢复该数据库。这种情况下Proxy的好处就显现出来了,因为用户连接是在proxy上,所以当后方数据库出现问题,proxy会将连接重新定位到已恢复的数据库上。
另外我们将所有数据库的读写操作都从本地移到了网络上,真正做到了计算和存储的分离。所有MySQL的数据文件不是保存在本地硬盘,而是存储在分布式的基于网络的存储框架上,数据在网络上被保存多份,同时严格监控用户的带宽资源消耗。
从节点的管理上来看本地的数据中心如果有上千台的节点就已经算是不小的网络了,而公有云在全球有超过百万的物理节点。面对如此多的节点运维的思路和架构会完全不同,我们在网络和存储方面实际上是花费了很大的精力才做到了不同租户或用户之间的隔离。
如果是单一线程的任务,本地存储肯定是比网络要快的,因为网络有着延时,但实际上云计算可以通过高并发来回避在延迟方面的不足。
MySQL PaaS带来了更方便快速的部署,高性价比,高可用性,以及高安全性的全托管服务。缺点在于限制了用户对数据库操作的权力,因为我们是将多个用户的数据放在一起运维,所以对整个环境的安全性要求比较高。
我们当前的架构下只是将MySQL作为一个进程,更多的重点是在MySQL任务监控、快速恢复上。由于架构中有代理、计算和分离,所以可以很容易的做到单点的高可用。这种情况下我们后台用的DB Engine是MySQL社区版本,支持现有的MySQL客户端和工具。
当前架构下计算和数据分离之后,数据是被存储在Azure storage上,这时虽然单点就可以达到高可用,但是在数据文件较大的时候,由于网络原因恢复起来需要一定的时间,经过监控发现基本上在3分钟以内。如果用户对时间有要求的话,一般是建议用户再建一个读写分离的从库,主库出现问题的时候手动将从库提升为主库。不过我们提供了更方便的启用备用库功能,可以将从库自动的提升为主库,从而节省时间,此时故障恢复时间通常在分钟级别(一般在60秒内)。
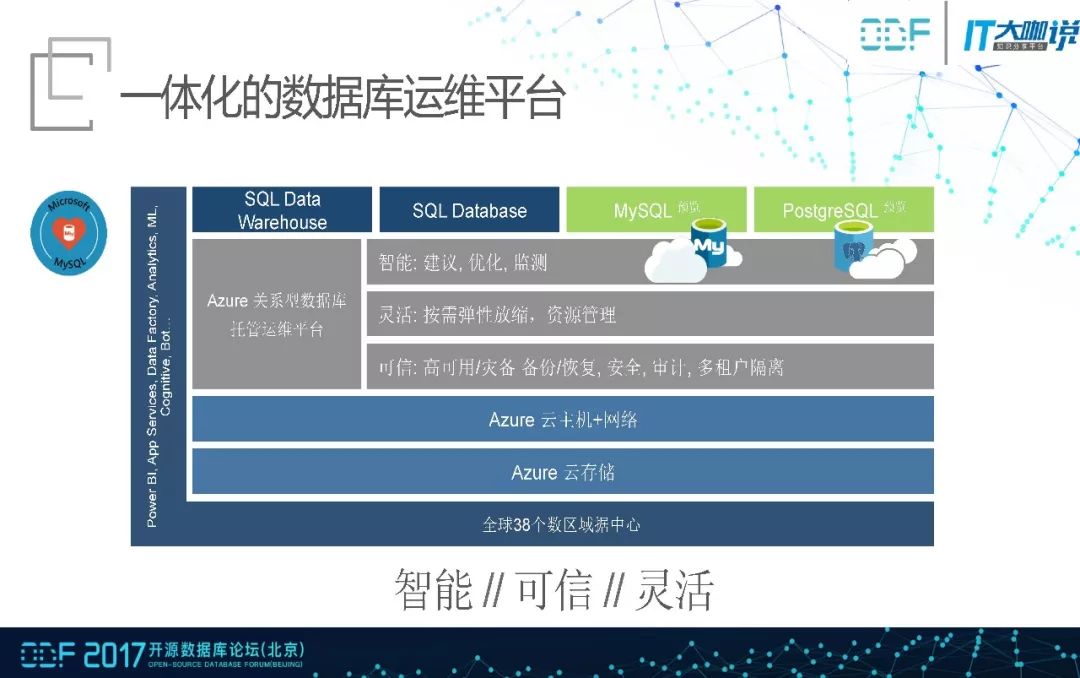
这是我们于2017年5月份在全球推出的一体化数据运维平台,MySQL、SQL Database、SQL Database warehouse 、PostgreSQL被统一的放在该平台中。它可以对运维数据进行优化监测并给出建议,能够按需弹性放缩,资源管理。
读写分离的优化
正常情况下主库和从库之间通过网络建立连接,然后将binlog从主库传输到从库,接着从库将binlog作为一个Relay插入到数据库中。如果主从库都是在MySQL PaaS上,那么MySQL实际就没有打开Replication开关,此时从库会另起一个进程,从Azure Storage上读取主库的binlog,然后解析插入到数据库中。这种架构下支持基于副本的横向扩展,适用于读取压力较大,或读远大于写的业务,从属实例不受限制,不过一般5个足够了。
由于目前混合云的应用还是比较多的,所以我们也支持混合云的数据库同步。比如从本地同步数据到Azure上以满足Azure上的应用需要,或者应用平滑迁移到Azure。可以通过管理门户配置同步和查看同步状态。
新一代的架构框架技术
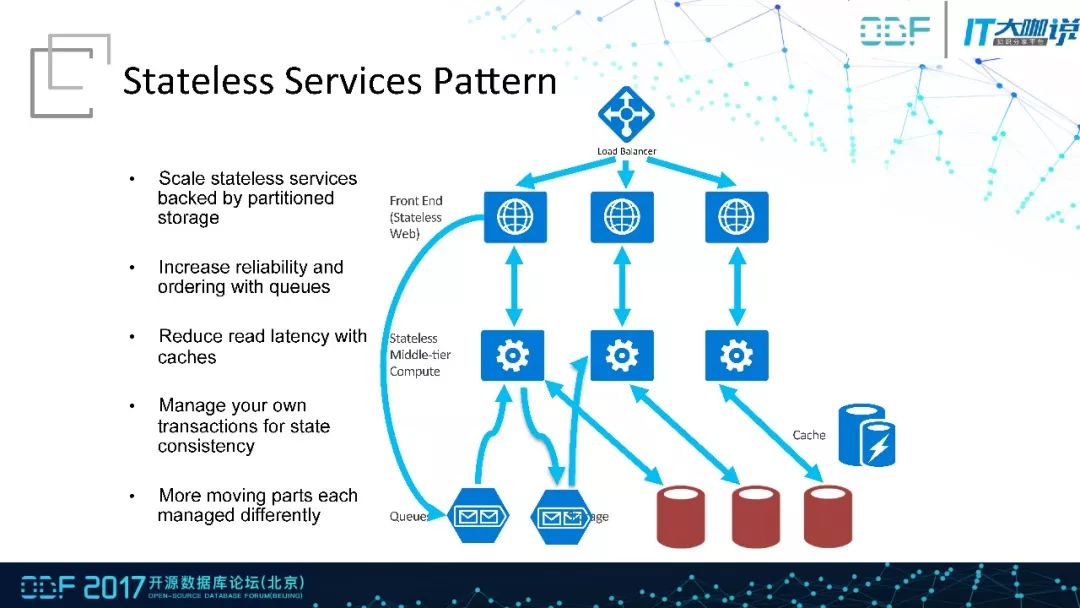
我们这里来回顾下基于云架构开发后台程序的两个Patter,首先是无状态模式。这个模式下存储和前端服务器可以很容易的弹性放缩,问题于中间的业务层,因为业务之间是相互依赖,且用户的数据代表某种状态,要访问这些状态就不可避免的引入排队机制、入锁机制等。面对这些问题常见的做法是使用蓄水池方法,将用户的请求放在queues中,降低无状态服务的复杂度同时还可以达到无线扩展队列的需求。
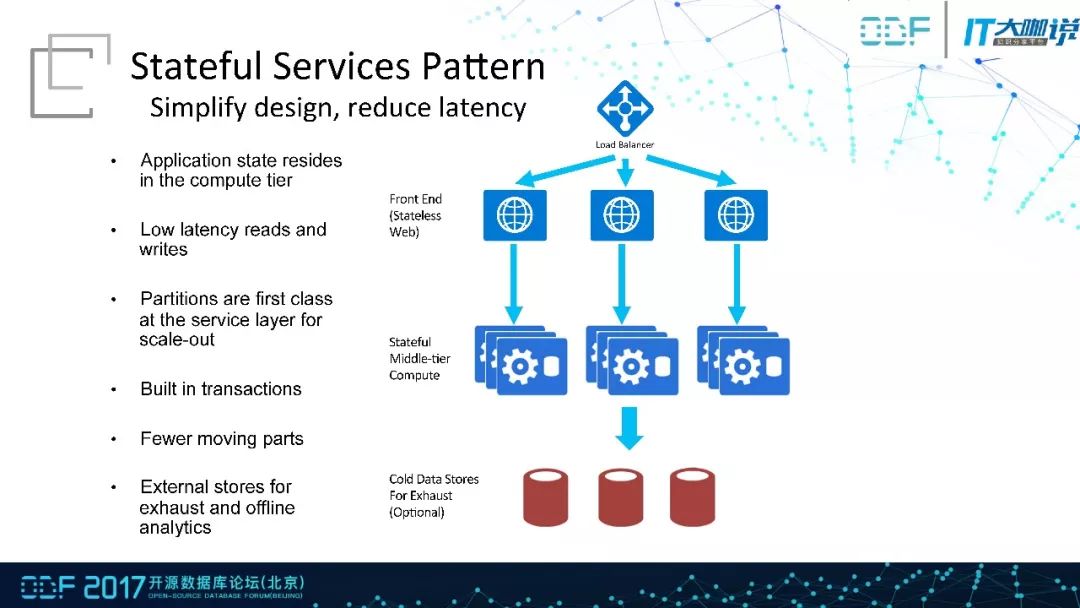
在实际的应用中其实大部分还是采用有状态模式,这种模式下依赖于有状态中间件,有状态中间件通过分区的方式解决高并发,在分区内使用传统方式保证数据一致性。这种情况下数据的传输过程相对较少,延迟得到了保障。
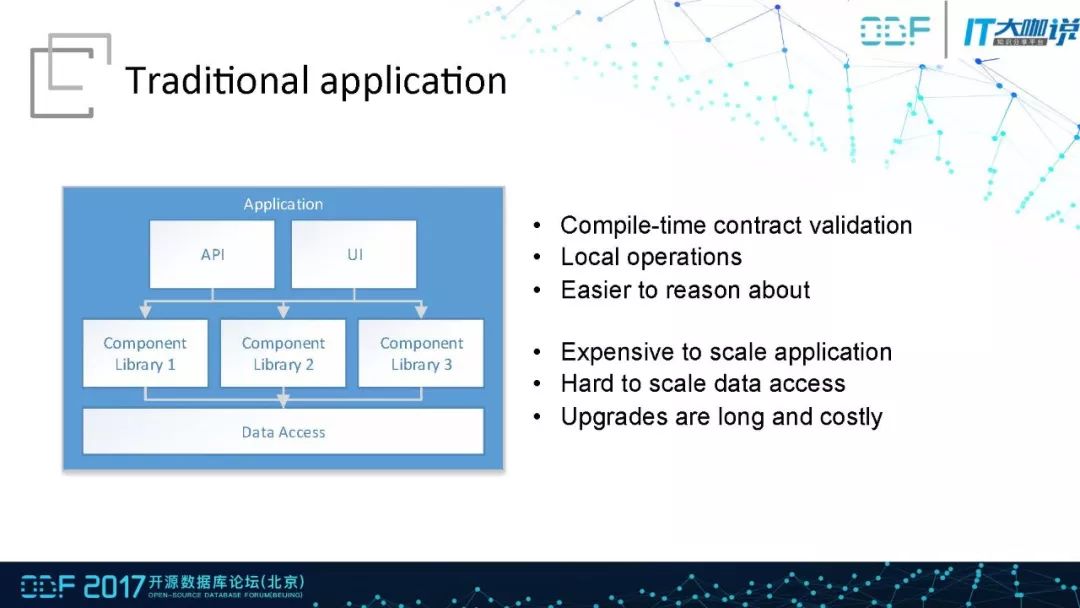
传统应用程序的API、UI、引擎等都是整合在一起,在编译的时候就能确定相互之间的依赖关系并能够方便的发现问题。不过由于所有的模块都被整合在一起,牵一发而动全身,所以在水平扩展服务能力的时候要付出相当大的代价。
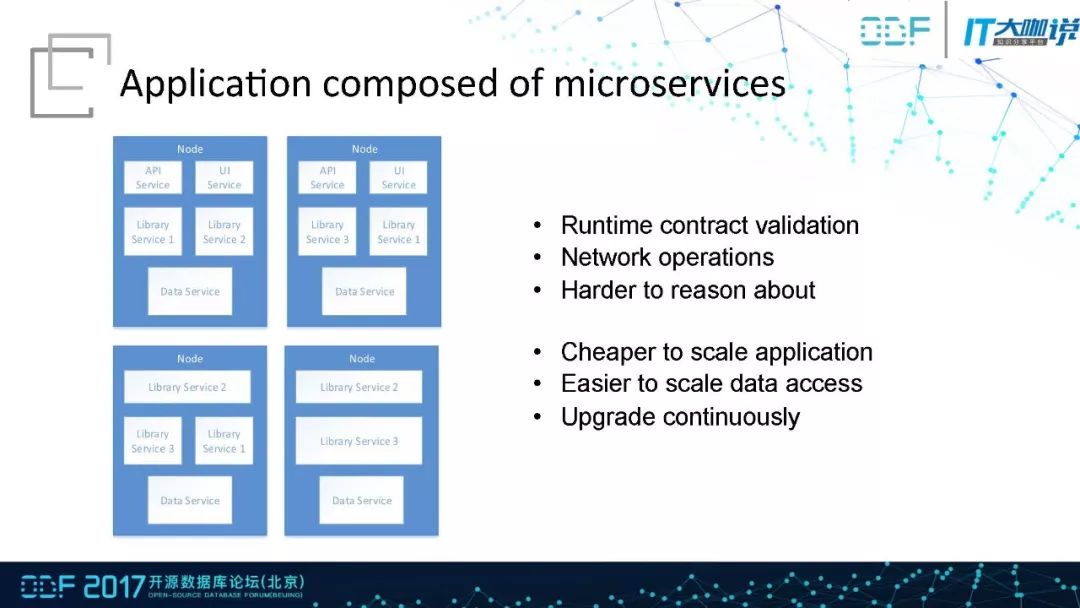
不同于传统应用,微服务框架中所有的模块都是一个独立的进程,模块之间通过HTTP或者RPC等协议进行沟通。相当于应用中包含多个服务,服务之间通过标准协议调用,不过只有在运行时才能发现错误,而非编译的时候。由于是完全基于网络的框架,所以必须要考虑到网络延迟的问题。微服务所带来的好处在于能够很方便的升级,模块数据相对来说容易监控,模块升级也已经可持续。
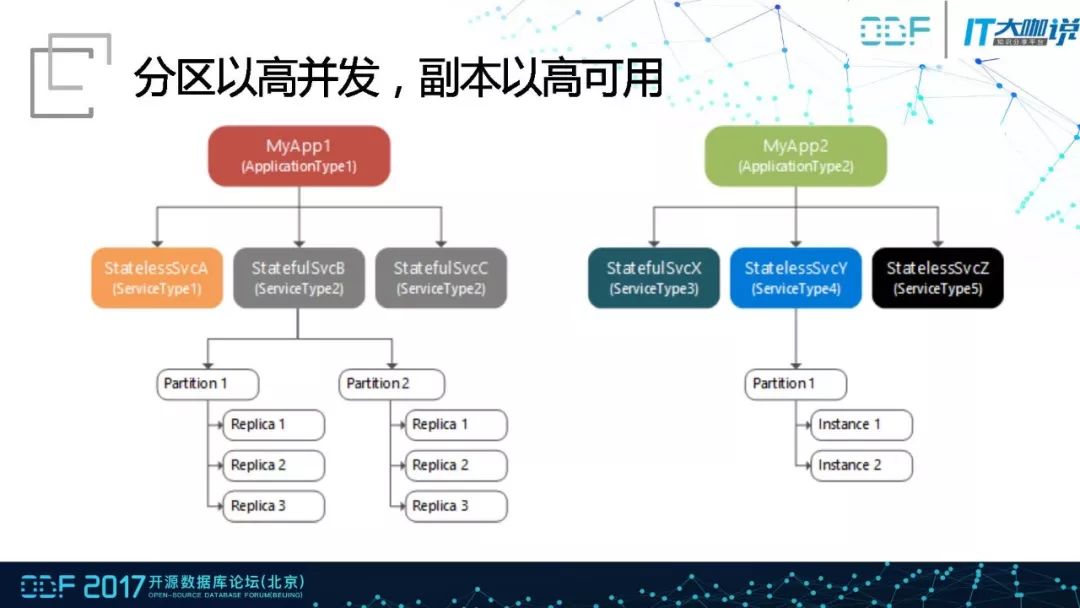
Service Fabric是微软的微服务框架。该框架中有一个ApplicationType用来定义App类型,类似于编程中的class。App创建后的实例可以有不同的名字,可以通过不同的名字来管理同一个实例。它同时支持有状态和无状态两种服务。其中有状态服务可以声明式的支持多个分区,每个分区中实例可以创建多个副本,相当于通过分区提高高并发能力,通过副本提供高可用。在多个分区的情况下,每个有状态的服务本身就可以创建一个状态机,这个状态机可以复制到其他几点的副本中。由于副本的复制可配置,所以可以让对有状态数据的访问基于本地节点,以此来降低延迟。
Service Fabric的另一个特点是对集群上运行的所有任务的自动部署,比如原来有5个节点10个分区,这不同的应用分区在这5个节点上会被自动分配,当节点扩大的时候,整个任务又会重新分配。这些部分都是自动完成,因此不用程序去显示的关注。
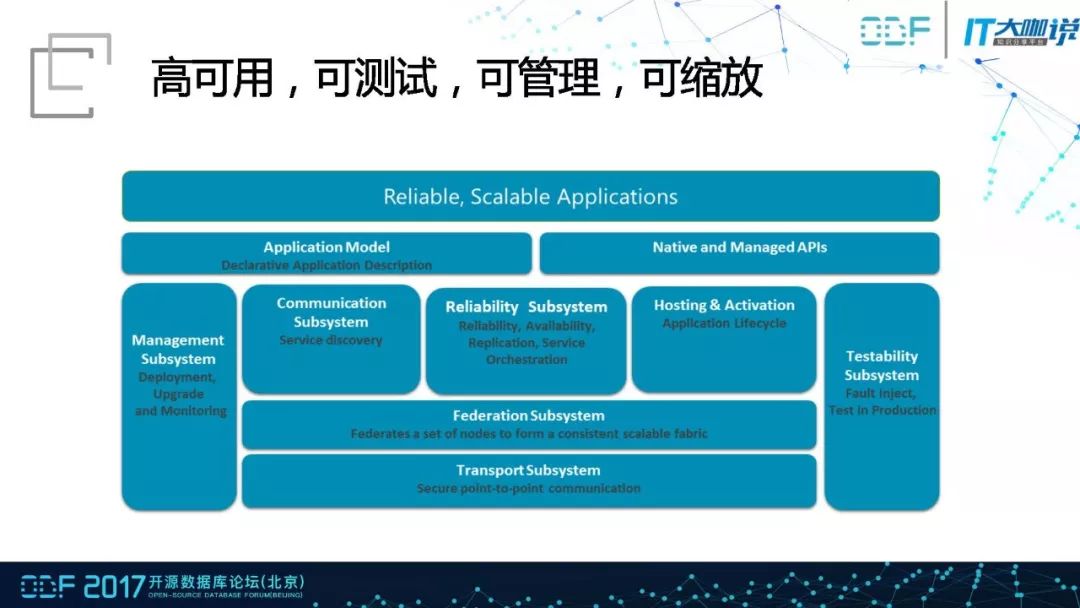
整个Service Fabric提供了一个更好的底层框架,能够实现高可用、可测试、可管理、可缩放。可测试指的是在服务升级的时候可以支持灰度发布,还可以设定某个条件判断升级版本是否有问题,一旦发现问题就会自动的回滚。可管理指的是基于内核级的检查和管理,当某个节点出现问题的时候,该节点上的运行的任务会在其他的节点上被自动的管理恢复。可缩放指的是增加节点的时候,整个任务会被重新分配。
SQL Azure架构中的SQL Server数据库被分解成很多的Service Fabric应用程序。物理集群被分成两部分,一部分作为控制管理的节点集群叫做Control Plane,它更多的做数据库的运维服务,另一部分用户的数据库任务运行在Data Plane上。他们之间有严格的安全发送机制,用来保证用户和数据库之间的运行环境。
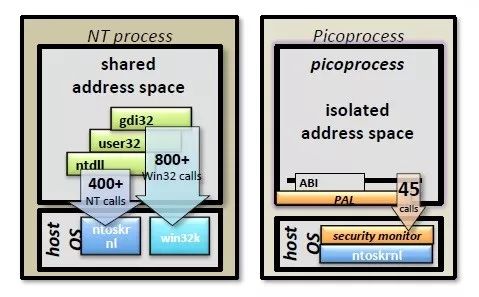
Drawbridge是微软应用的新的容器技术,它既有虚拟机技术的强隔离性,又具有容器技术的高计算密度。核心是传统的NT Process,有1200多个API,显然这么多API是很难做到严格意义上的绝对安全,因此后续进行了优化。首先是将NT kernel运行在用户态,第二是让用户态的操作系统和真正的操作系统之间只允许不超过15个系统调用。基于这两步NT上出现了一个特殊的进程Picoprocess,它从外部看就是一个空进程,唯一与它有交互的是一个很小的系统内核库。
SQL Server for Linux也应用了Drawbridge技术,这样就可以将原先windows上的SQL Server通过SQLPAL层移植到Linux上。
以上为今天的全部分享内容,谢谢大家!
IT大咖说 | 关于版权
感谢您对IT大咖说的热心支持!
相关推荐
推荐文章
近期活动
点击【阅读原文】 打开干货通道
以上是关于微软:云原生的MySQL托管服务架构及读写分离的优化的主要内容,如果未能解决你的问题,请参考以下文章