2020江苏卷高考作文 | 什么是推荐系统
Posted 每天学python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2020江苏卷高考作文 | 什么是推荐系统相关的知识,希望对你有一定的参考价值。
回复【资料】可获取python入门电子书
根据以下材料,选取角度,自拟题目,写一篇不少于800字的文章;除诗歌外,文体自选。
同声相应,同气相求。人们总是关注自己喜爱的人和事,久而久之,就会被同类信息所环绕、所塑造。智能互联网时代,这种环绕更加紧密,这种塑造更加可感。
你未来的样子,也许就开始于当下一次从心所欲的浏览,一串惺惺相惜的点赞,一回情不自禁的分享,一场突如其来的感动。
这说的不就是推荐系统吗!!
我们在互联网中的每一个操作,都会影响到未来给我们推送的信息。
第一次了解推荐系统的时候,我刚刚转战网易云音乐听歌。
那时候除了网易的歌比较多,还有一个原因就是我特别喜欢它的私人FM(类似随便听听和猜你喜欢)。
作为一个懒癌晚期选手,我很多时候懒得自己找歌单,就打开私人FM。神奇的是,里面放的几乎都是我喜欢的歌。
后来和朋友讨论这件事,才知道网易当时的推荐算法做的特别好。
其实现在推荐算法无时无刻不在我们的生活中出现着,扮演着重要的角色。
如果你刷知乎,当你刷完了
年入百万是种怎样的体验?
之后,它还会给你推送诸如
年收入100万在中国属于什么水平?
年入千万是什么体验?
只不过知乎的算法现在有些过分,刷过一道问题之后会出现满屏的类似问题。这也让很多人诟病不已。
如果你用今日头条,用抖音,用微博,也会发现类似的情况。
当你刷完一个视频或一条推送,它会猜测你喜欢类似的内容,并不断给你推荐类似的内容。
有时候不得不感叹,虽然大家用的都是一个互联网,但人与人之间的隔阂并没有减小,反而在逐渐增大。
互联网是个大圈子,但其实人人都沉浸在各自的小圈子里面,只能看到自己喜欢的东西而不自知。
上面已经写了快800字了你敢信!高考作文都快写完了还没开始写正题!
之前我去某大厂广告组实习的时候,就被问到了关于推荐系统的问题。如,如何快速从上千个广告中筛选出用户可能会喜欢的广告。
我们的目标是学习!
所以,今天想和大家聊聊,什么是推荐系统。

什么是推荐系统(recommender system)
根据维基百科的定义:
推荐系统是一种信息过滤系统,用于预测用户对物品的“评分”或“偏好”。
推荐系统近年来非常流行,应用于各行各业。推荐的对象包括:电影、音乐、新闻、书籍、学术论文、搜索查询、分众分类、以及其他产品。
根据推荐算法的不同,我们会把推荐系统分为以下几类:
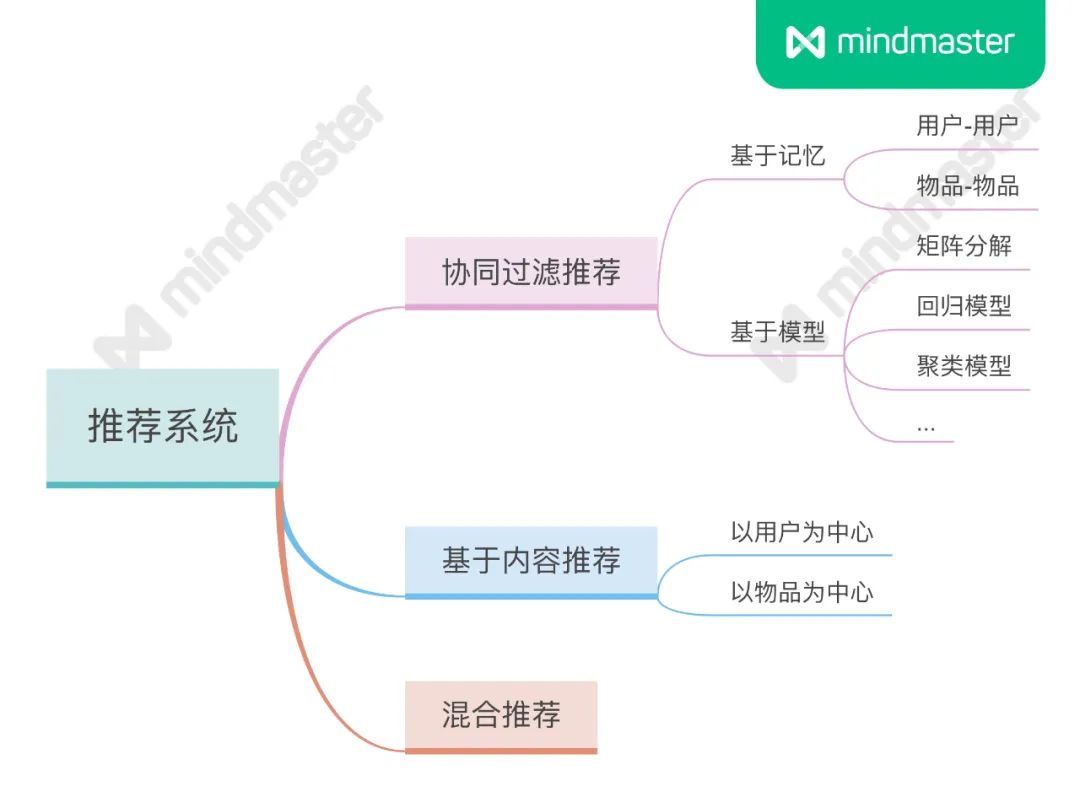
(有没有好用的免费思维导图推荐啊,带着水印实在太丑了)
简单来说,可以分为协同过滤推荐、基于内容推荐、以及混合推荐(即协同过滤与基于内容相结合的算法)。
下面来简单介绍下每种推荐算法。

协同过滤推荐(Collaborative filtering methods)
协同过滤推荐只根据过去用户对物品的评价而不考虑用户或物品本身的性质,来判断未来某些用户对某些物品的评价高低。
举个栗子,如果用户1喜欢物品ABC,用户2喜欢物品AC,用户3讨厌物品AC,那么我们判断用户1和用户2有相似的喜好,从而会推荐物品B给用户2。
注意到,这里我们不考虑用户们年龄,性别,工作,城市等等,只考虑他们过去对物品的喜好程度。
同样的,我们也不会关注ABC三个产品究竟是生活用品,食物,家具或其他,只考虑它们究竟被哪些用户所喜欢。
因此,在协同过滤算法中,我们只需要存储一个非常大的评分矩阵。
假如我们有 m 个用户,n 个物品,那么我们只需利用一个 mxn 的矩阵存储每个用户对每个物品的评分即可。下面的表格存储了三个用户和两个物品的评分信息。
物品A |
物品B |
|
用户1 |
5 |
1 |
用户2 |
- |
3 |
用户3 |
2 |
- |
当然,这个矩阵中会有很多的空白项,因为一个用户不可能尝试过所有的物品,一个物品也不可能被所有用户购买/打分。
推荐算法的目的就是将这些空白格填满。
协同过滤推荐又可以分为两类:基于记忆推荐和基于模型推荐。
1.1
基于记忆推荐(Memory-based collaborative approaches)
基于记忆推荐利用相似用户或者相似物品的数据对用户进行推荐。
假如现在我们想对某个用户A推荐一些产品。
利用相似用户推荐(即用户-用户推荐):
-
根据历史数据寻找和用户A行为/喜好最相似的 k 个用户 -
给用户A推荐他还没有买过的,但是最相似的 k 个用户的买过且评价较高的物品
利用相似物品推荐(即物品-物品推荐):
-
根据用户A的历史数据寻找和他喜欢的某个物品最相似的 k 个物品 -
给用户A推荐这 k 个物品中他还没有买过的物品
在基于模型推荐中,我们假设用户们和物品们都可以用某些“特征”来描述,虽然我们并不知道这些特征具体是什么。
以矩阵分解算法为例。
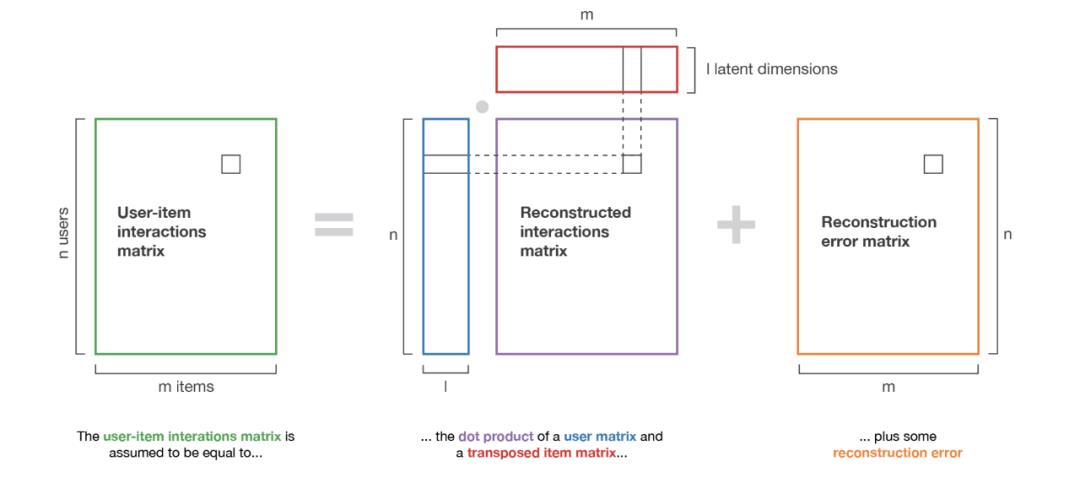
我们可以将历史数据矩阵(user-item interactions matrix)拆分成两个矩阵的乘积+一些误差项。
拆分得到的两个小矩阵便是根据特征描述的用户和物品。
获取了两个小矩阵之后,我们可以通过简单的矩阵相乘来预测用户对于某个物品的评价。
这里就不详细描述如何获取两个小矩阵了。如果你学过线性代数,可以去搜索一下。
1.3
协同过滤算法的优劣势
协同过滤算法有两大优势。
首先,它不需要知道任何用户或者物品的信息就可以进行推荐。诚然,用户信息有助于我们对用户进行分类。但是在现实中,用户信息其实很难获取。
相信大家在用各种app的时候,都会或多或少收到一些问卷调查。比如问你的年龄和性别。
但这些问卷往往会影响用户体验,收集到的信息也不足以帮助算法进行推荐。
其次,随着历史数据越来越多,算法的预测会越来越准确。对于淘宝这样量级的平台,历史数据非常多,已经足够进行不错的推荐了。
当然,根据算法描述,它的劣势也非常明显。
对于一个新产品或一个新用户,矩阵中并没有它对应的历史数据。
因此,只能先随机对它进行一些推荐。等到收集了足够多的历史数据,才能进行较好的推荐。这也叫做“cold start problem”。

基于内容推荐(Content-based methods)
与协同过滤推荐不同,基于内容推荐会利用用户和物品的性质/特征来描述他们。
对用户而言,性别、年龄、城市、甚至手机操作系统都可以用作用户特征。
例如,一个30岁,用安卓手机,月入6000的北漂男性用户可以被描述成:
['male',30,'Beijing','android',6000]对于物品而言更加简单,如产品的种类价格,音乐风格,电影导演等等。
基于内容推荐可以分为两大类:以用户为中心和以物品为中心。
2.1
以用户为中心(user-centred)
以用户为中心时,我们用一系列特征来描述物品。在模型中,每一个物品可以用一个向量来描述。
根据历史数据,我们可以进行回归(regression)或者分类(classification)来训练模型,从而预测对于一个新的用向量描述好的物品,这个用户会给它什么样的评分(或者喜欢它的概率有多大)。
2.2
以物品为中心(item-centred)
同样的,以物品为中心时,我们用一系列特征来描述用户。
这时候,模型需要问的问题改成了,对于某个物品,用户们会不会喜欢它(或者会给它什么样的评分)。

推荐系统的评价标准
有了预测模型,怎么来评判模型的好坏呢?
对于评分制的情形,如电影评分,均方根误差(Root-Mean-Square Error)是较为传统的评价标准,即推荐系统预测的评分和用户最终给的评分差距有多大。
对于0/1类型的情形,如用户买/不买某个产品,预测准确率和召回率更为常用。
其中:
准确率 = 推荐的物品最后用户究竟买了多少
召回率 = 用户买的产品中有多少是被推荐的
对于很多公司,用户评分或者购买行为数据量太小,并不足以对模型进行评价。
因此,这些公司会去劳动力更为廉价的地方雇一些人打分,来提供训练模型的原始数据。
Reference(我就随便一写,你就随便一看,不要在意格式好吗)
[1] https://zh.wikipedia.org/wiki/%E6%8E%A8%E8%96%A6%E7%B3%BB%E7%B5%B1
[2] https://towardsdatascience.com/introduction-to-recommender-systems-6c66cf15ada
封面图源网络,侵删
以上是关于2020江苏卷高考作文 | 什么是推荐系统的主要内容,如果未能解决你的问题,请参考以下文章