推荐系统产品和算法概述丨产品杂谈系列
Posted 木子的杂谈馆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统产品和算法概述丨产品杂谈系列相关的知识,希望对你有一定的参考价值。
本文主要是对最近所学的推荐系统的总结,将会简单概述非个性化范式、群组个性化范式、完全个性化范式、标的物关联标的物范式、笛卡尔积范式等5种常用的推荐范式设计思路。
推荐算法常见设计维度
许多产品的推荐算法都依赖于三类数据:标的物相关的描述信息(如推荐鞋子,则包括鞋子的版型、适用对象、材质等信息、用户画像数据(指的是用户相关数据,如性别、年龄、收入等)、用户行为数据(例如用户在淘宝上的浏览、收藏、购买等)。这三类数据是推荐模型的主要组成部分,除此之外一些人工标注的数据(例如为商品人工打上标签)、第三方数据也能够用于补充上述的三类数据。
服务端在有以上数据的基础上,就可以从三个维度进行推荐:
标的物维度:用户在访问标的物详情页或者退出标的物详情页时,可以根据标的物的描述信息为用户提供一组具有关联性的标的物作为推荐,例如为浏览嘉士伯啤酒的用户推荐喜力啤酒,为购买羽毛球拍的用户推荐羽毛球;
用户维度:为用户推荐可能感兴趣的标的物,例如为一位24岁的女子推荐口红;
用户与标的物的笛卡尔积维度:将用户维度和标的物维度结合起来,不同用户访问同一标的物的详情页时看到的推荐内容也不一样。举个粗暴的例子,A用户常在淘宝上购买华为手机,而B用户常购品牌是iPhone,则当A、B两个用户都在浏览华为的一款手机时,为A用户推荐其他款式的华为手机,而为B用户推荐的则是新款iPhone手机。
基于用户维度的推荐
根据个性化推荐的颗粒度,我们可以将基于用户维度的推荐分为非个性化推荐、群组个性化推荐及完全个性化推荐三种类型。
非个性化推荐指的是每个用户看到的推荐内容都是一样的在互联网产品中,我们最常见的非个性化推荐的例子是各种排行榜,如下图是酷狗音乐的排行榜推荐,通过各个维度计算各类榜单,不管是谁看到这个榜单,上面的排序和内容都是一致的。
群组个性化推荐指的是将具有相同特征的用户聚合成一组,同一组用户在某些方面具备相似性,系统将为这一组用户推荐一样的内容。这种推荐方式是很多产品进行用户精细化运营时会采用的方式,通过用户画像系统圈定一批批用户,并对这批用户做统一的运营。例如音乐软件的推荐播放,若以摇滚乐为基准将一批用户聚合成组,则为这些用户提供的每日推荐歌单是相同的内容和顺序,但与另一组爱听民谣的用户相比,两组用户看到的每日推荐内容将是不同的。
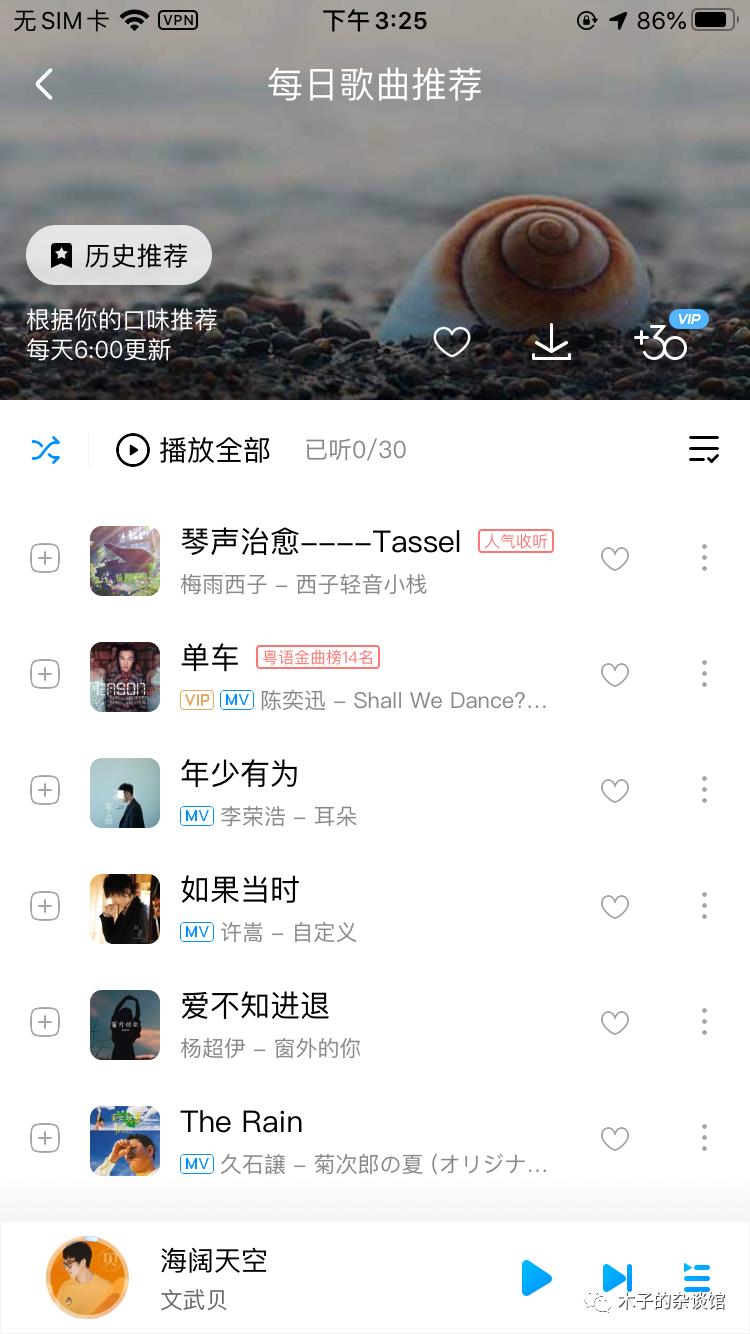
完全个性化指的是为每个用户推荐的内容都不一样,是根据每一位用户的行为及兴趣来为用户做推荐,是当今互联网产品中最常用的一种推荐方式。大多数情况下我们所说的推荐就是指这种形式的推荐,例如淘宝首页的“猜你喜欢”就是一个完全个性化的推荐,千人千面,每个人看到的推荐商品都不一样。
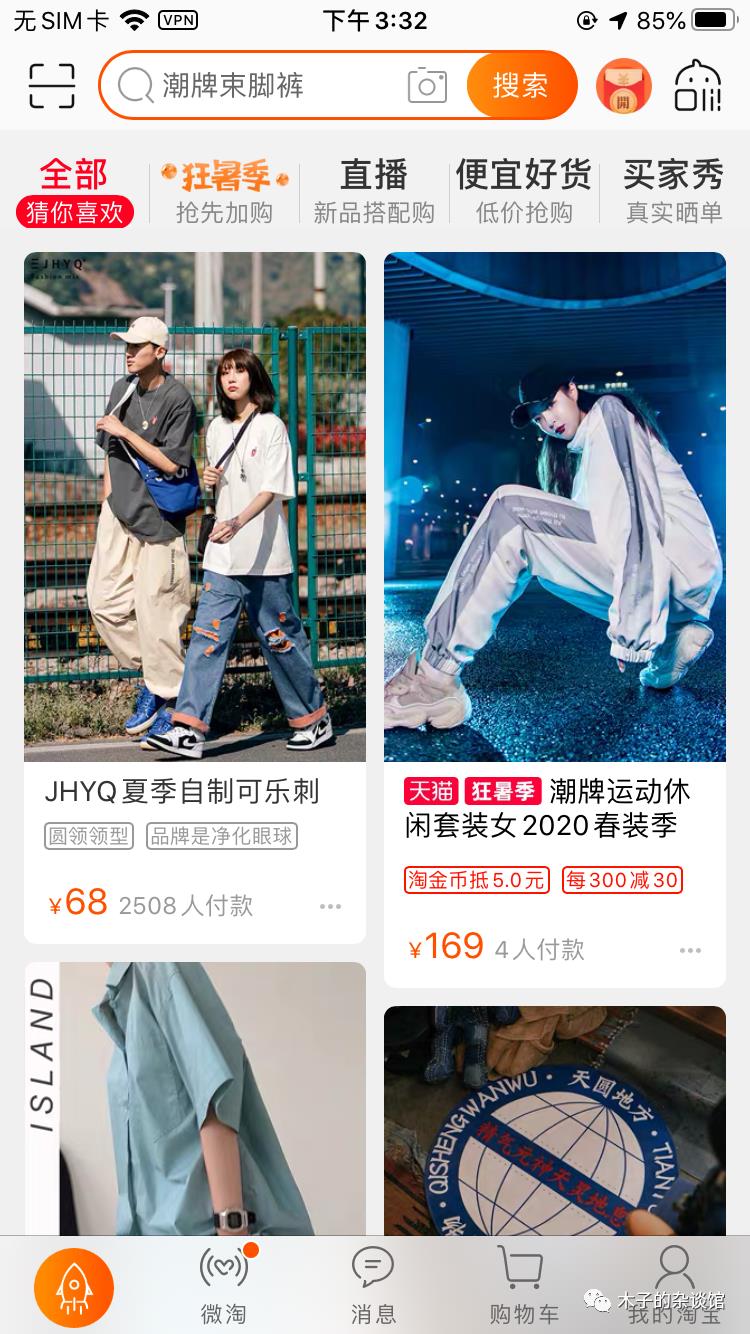
完全个性化可以只基于用户行为进行推荐,在构建推荐算法时只考虑到用户个人的特征和行为,不需要考虑其他用户,这也是最常见的内容推荐方式。除此之外,还可以基于群组行为进行完全个性化推荐,除了利用用户自身的行为外,还依赖于其他用户的行为构建推荐算法模型。例如,用户属性和行为相似的一群用户,其中90%的用户买了A商品后也买了B商品,则当剩下的10%用户单独购买B商品时,我们可以为该用户推荐商品A。
基于群组行为进行的完全个性化推荐可以认为是全体用户的协同进化,常见的协同过滤、基于模型的推荐等都属于这类推荐形式。
基于标的物维度的推荐
基于标的物的推荐指的是用户在访问标的物详情页或者退出标的物详情页时,可以根据标的物的描述信息为用户推荐一批相似的或者相关的标的物,对应的是最开始提到的“标的物关联标的物范式”。如下图酷狗的相似歌曲推荐:
除了音乐产品外,视频网站、电商、短视频等APP都大量使用基于标的物维度的推荐。如下图便是YouTube基于标的物关联标的物的推荐。在YouTube上我观看一个周杰伦的音乐视频时,YouTube在该页面下方为我推荐更多与周杰伦有关的视频。
基于用户和标的物交叉维度的推荐
基于用户和标的物交叉维度的推荐指的是将用户维度和标的物维度结合起来,不同用户访问同一标的物的详情页时看到的推荐内容也不一样,对应的是开头提到的笛卡尔积推荐范式。
拿酷狗音乐对相似歌曲的推荐来举例,如果该推荐采用的是用户和标的物交叉维度的推荐的话,不同用户看到的“没有理想的人不伤心”这首歌曲,下面的相似歌曲是不一样的。拿淘宝举例的话,一样是搜索“裤子”这一关键词,不同的人搜索得到的搜索结果和排序是不同的,可能用户A搜索出来优先展示的是牛仔裤,而用户B优先展示的是休闲裤,淘宝将结合搜索关键词与用户个人的历史行为特征展示对应的搜索结果和排序。
对于基于笛卡尔积推荐范式设计的推荐系统来说,由于每个用户在每个标的物上的推荐列表都不一样,我们是没办法是先将所有组合计算出来并储存(组合过多,数量是非常巨大的),因此对于系统来说,能否在用户请求的过程中快速地为用户计算个性化推荐的标的物列表将会是一个比较大的挑战,对于整个推荐系统的架构也有更高的要求,因此在实际应用中,该种推荐方式用的比较少。
各种推荐范式中常用的算法策略
非个性化范式
非个性化范式指的是为所有用户推荐一样的标的物列表,常见的各种榜单就是基于此类推荐规则,如电商APP中的新品榜、畅销榜等。排行榜就是基于某个规则来对标的物进行排序,将排序后的部分标的物推荐给用户。例如新品榜是按照商品上架的时间顺序来倒序排列,并将排序在前列的产品推荐给用户。而畅销榜则是按照商品销量顺序降序排列,为用户推荐销量靠前的商品。
根据具体的产品和业务场景,即使同样是非个性化范式推荐,在具体实施时也可能会比较复杂。例如在电商APP中畅销榜的推荐可能还会将地域、时间、价格等多个维度纳入考虑范围内,基于每个维度及其权重进行最终的排序推荐。
大部分情况下,非个性化范式推荐可以基于简单的计数统计来生成推荐,不会用到比较复杂的机器学习算法,是一种实施门槛较低的推荐方式。基于此,非个性化范式推荐算法可以作为产品冷启动或者默认的推荐算法。
完全个性化范式
完全个性化范式是目前的互联网产品中最常用的推荐模式,可用的推荐方法非常多。下面对常用的算法进行简单梳理。
1. 基于内容的个性化推荐算法。
该推荐算法只需要考虑到用户自己的历史行为而不需要考虑其他用户的行为,其核心思想是:标的物是有描述属性的,用户对标的物的操作行为为用户打上了相关属性的烙印,这些属性就是用户的兴趣标签,那么我们就可以基于用户的兴趣来为用户生成推荐列表。还是拿音乐推荐来举例子,如果用户过去听了摇滚和民谣两种类型的音乐,那么摇滚和民谣就是这个用户听歌时的偏好标签,此时我们就可以为该用户推荐更多的摇滚类、民谣类歌曲。
基于内容的个性化推荐在实操中有以下两类方式。
第一种是基于用户特征标识的推荐。
标的物是有很多文本特征的,例如标签、描述信息等,我们可以将这些文本信息基于某种算法转化为特征向量。有了标的物的特征向量后,我们可以将用户所有操作过的标的物的特征向量基于时间加权平均作为用户的特征向量,并根据用户特征向量与标的物特征向量的乘积来计算用户与标的物的相似度,从而计算出该用户的标的物推荐列表。
第二种是基于倒排索引查询的推荐。
如果我们基于标的物的文本特征(如标签)来表示标的物属性,那么基于用户对该标的物的历史行为,我们可以构建用户画像,该画像即是用户对于各个标签的偏好,并且对各个标签都有相应的偏好权重。
在构建完用户画像后,我们可以基于标签与标的物的倒排索引查询表,以标签为关键词,为用户进行个性化推荐。
举个粗暴的例子,有歌曲A、B、C分别对应摇滚、民谣、古风三个音乐标签,我听了歌曲A、B,则在我身上打了摇滚和民谣的标签,又基于我听这两个歌曲的频率,计算了我对“摇滚”和“民谣”的偏好权重。
在倒排索引查询表中,摇滚和民谣又会分别对应一部分歌曲,所以,可以根据我对摇滚和民谣的偏好权重从查询表中筛选一部分歌曲并推荐给我。
基于倒排索引查询的推荐方式是非常自然直观的,只要用户有一次行为,我们就可以据此为用户进行推荐。但反过来,基于用户兴趣给用户推荐内容,容易局限推荐范围,难以为用户推荐新颖的内容。
2. 基于协同过滤的推荐算法
基于协同过滤的推荐算法,核心思想是很朴素的”物以类聚、人以群分“的思想。所谓物以类聚,就是计算出每个标的物最相似的标的物列表,我们就可以为用户推荐用户喜欢的标的物相似的标的物,这就是基于物品的协同过滤。所谓人以群分,就是我们可以将与该用户相似的用户喜欢过的标的物(而该用户未曾操作过)的标的物推荐给该用户,这就是基于用户的协同过滤。
常见的互联网产品中,很多会采用基于标的物的协同过滤,因为相比之下用户的变动概率更大,增长速度可能较快,这种情况下,基于标的物的协同过滤算法将会更加的稳定。
协同过滤算法思路非常简单直观,也易于实现,在当今的互联网产品中应用广泛。但协同过滤算法也有一些难以避免的问题,例如产品的冷启动阶段,在没有用户数据的情况下,没办法很好的利用协同过滤为用户推荐内容。例如新商品上架时也会遇到类似的问题,没有收集到任何一个用户对其的浏览、点击或者购买行为,也就无从基于人以群分的概念进行商品推荐。
3. 基于模型的推荐算法
基于模型的推荐算法种类非常多,我了解到的比较常见的有迁移学习算法、强化学习算法、矩阵分解算法等,且随着近几年深度学习在图像识别、语音识别等领域的进展,很多研究者和实践者也将其融入到推荐模型的设计当中,取得了非常好的效果。例如阿里、京东等电商平台,都是其中的佼佼者。
由于该算法涉及到比较多的技术知识,在下也处于初步学习阶段,就不班门弄斧做过多介绍了,有兴趣的朋友可以自行进行学习。
群体个性化范式
群组个性化推荐的第一步是将用户分组,因此,采用什么样的分组原则就显得尤为重要。常见的分组方式有两种。
1. 基于用户画像分组的推荐
先基于用户的人口统计学数据(如年龄、性别等)或者用户行为数据(例如对各种不同类型音乐的播放频率)构建用户画像。用户画像一般用于做精准的运营,通过显示特征将一批人圈起来形成同一组,对这批人做针对性的运营。因为前头已经提到此算法,这里不再重复介绍。
2. 采用聚类算法的推荐
聚类是非常直观的一种分组思路,将行为偏好相似的用户聚在一起成为一个组,他们有相似的兴趣。常用的聚类策略有如下两类。
标的物关联标的物范式
标的物关联标的物就是为每个标的物推荐一组标的物。该推荐算法的核心是怎么从一个标的物关联到其他的标的物。这种关联关系可以是相似的(例如嘉士伯啤酒和喜力啤酒),也可以是基于其他维度的关联(例如互补品,羽毛球拍和羽毛球)。常用的推荐策略是相似推荐。下面给出3种常用的生成关联推荐的策略。
1. 基于内容的推荐
这类推荐方式一般是利用已知的数据和标的物信息来描述一个标的物,通过算法的方式将其向量化,从而根据不同标的物向量之间的相似度来计算标的物之间的相似度,从而实现相识标的物的推荐。
2. 基于用户行为的推荐
在一个成熟的产品中,我们可以采集到的非常多的用户行为,例如在电商平台中,我们可以手机用户搜索、浏览、收藏、点赞等行为,这些行为就代表了用户对某个标的物的某种偏好,因此,我们可以根据用户的这些行为来进行关联推荐。
例如,可以将用户的行为矩阵分解为用户特征矩阵和物品特征矩阵,物品特征矩阵可以看成是衡量物品的一个向量,利用该向量我们就可以计算两个标的物之间的相似度了,从而为该用户推荐相似度高的其他产品。
再例如,采用购物篮的思路做推荐,这种思路非常适合图书、电商等的推荐。以电商为例,我们可以把用户经常一起浏览(或者购买)的商品形成一个列表,将过去一段时间所有的列表收集起来。对于任何一个商品,我们都可以找到与它一起被浏览或者购买的其他商品及其次数,并根据次数来判断其关联性,从而进行关联推荐。
3. 基于标的物聚类的推荐
我们可以对用户进行分组,同样,我们也能够对标的物进行聚类分组。通过某位参考维度,我们将一些列具有相似性的标的物分成一组,当我们为用户进行推荐的时候,便可以将同一组内的其他标的物作为推荐对象,推荐给用户。
笛卡尔积范式
笛卡尔积范式的推荐算法一般是先采用标的物关联标的物范式计算出待推荐的标的物列表。再根据用户的兴趣来对该推荐列表做调整(例如根据不同兴趣的权重重新调整推荐列表的排序)、增加(例如基于个性化增加推荐对象)、删除(例如过滤掉已经看过的),由于其复杂程度较高在实际业务场景中应用较少,这边不再详细介绍。
好了,本次的介绍就到此为止了。本次主要是做了一个非常简单的推荐算法概述,在实际的业务场景中,还经常需要与产品形态或者更多的维度(如时间、地点等)相结合,这是一个很有意思的领域,有兴趣的朋友可以进一步了解。
以上是关于推荐系统产品和算法概述丨产品杂谈系列的主要内容,如果未能解决你的问题,请参考以下文章