会话推荐系统新进展:基于互信息最大化的多知识图谱语义融合 | KDD 2020
Posted AI科技评论
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了会话推荐系统新进展:基于互信息最大化的多知识图谱语义融合 | KDD 2020相关的知识,希望对你有一定的参考价值。
作者 | RUC AI Box

论文链接: https://arxiv.org/abs/2007.04032
会话推荐系统(conversation recommender system, CRS)旨在通过交互式的会话给用户推荐高质量的商品。通常CRS由寻求商品的user和推荐商品的system组成,通过交互式的会话,user实时表达自己的偏好,system理解user的意图并推荐商品。目前会话推荐系统有两个问题需要解决。首先,对话数据本身缺少足够的上下文信息,无法准确地理解用户的偏好(传统的推荐任务会有历史交互序列或者用户属性,但是该场景下只有对话的记录)。其次,自然语言的表示和商品级的用户偏好之间存在语义鸿沟(在user的话语“Can you recommend me a scary movie like Jaws”中,用户偏好反映在单词”scary“和电影实体”Jaws“上,但这两类信息天然存在语义的差异)。
为了解决上述问题,本文提出了模型KG-based Semantic Fusion approach(KGSF),通过互信息最大化的多知识图谱语义融合技术,不仅打通了对话中不同类型信息的语义鸿沟,同时针对性地设计了下游的模型,以充分发挥两个知识图谱的作用,在会话推荐系统的两个任务上均取得了state-of-the-art的效果。
引言
会话推荐系统是近年来寻求通过与用户的对话提供高质量推荐的新兴研究课题。就方法而言,CRS需要在推荐模块和对话模块之间无缝集成。一方面,对话模块要理解用户的意图,并生成合适的回复。另一方面,推荐模块学习用户偏好,并基于上下文推荐高质量的商品。为了开发有效的CRS,学界已经提出了数种集成这两个模块的解决方案,包括基于半结构化用户查询的信念跟踪器[1]和用于模块选择的开关解码器[2]。

虽然这些研究在一定程度上提高了CRS的性能,但仍有两个主要问题有待解决。首先,会话主要由几句话组成,缺乏足够的上下文信息,无法准确理解用户的偏好。如上表所示,一个用户正在寻找类似于“Paranormal Activity(2007)”的恐怖电影,其中用两个短句子描述了他/她的偏好。为了获取用户的内部信息,我们需要充分利用上下文信息并对其建模(e.g. 理解单词“scary”和电影“Paranormal Activity(2007)”背后的语义)。显然,单凭对话文本很难获得这样的事实信息。第二,对话内容用自然语言表示,而实际用户偏好则反映在商品或实体上(例如,演员和电影类型)。这两种数据信号之间存在天然的语义差异。我们需要一种有效的语义融合方法来理解或生成对话内容。如上表所示,如果不能拟合语义上的鸿沟,就无法生成解释推荐的文本(e.g. “thriller movie with good plot”)。
为了丰富对话上下文信息,我们使用知识图谱提供外部知识。由于上下文信息包含自然语言词汇和商品两类数据,所以使用面向单词(word)的知识图谱(KG)和面向商品(item)的知识图谱,分别强化词汇的知识和商品的知识。ConceptNet[3]作为面向word的KG,提供了word间的关系,诸如每个单词的同义词,反义词和共现单词。DBpedia[4]作为面向item的KG,提供了item之间的关系,描述有关item属性的结构化事实。但是两个KG之间仍然存在着语义鸿沟,对KG数据的利用可能会受到限制。
我们首先运用图神经网络分别学习两个知识图谱的节点表示,然后使用MIM弥合两个知识图谱的语义鸿沟。我们核心的想法是让共现在一个会话中的word和item的表示更相似,使用这种策略可以对齐两个语义空间下的数据表示。在语义对齐的基础上,本文进一步利用了知识图谱强化后的的推荐模块来提供精准的推荐,并利用知识图谱强化后的对话组件来帮助在会话文本中生成信息量丰富的关键字或实体。
据我们所知,这是第一次使用KG增强的语义融合来解决对话系统和推荐系统的集成。我们的模型利用两个不同的KG分别增强单词和商品的语义,并统一它们的表示空间。在一个公共CRS数据集[2]上的大量实验证明了我们的方法在推荐和会话任务上的有效性。
方法
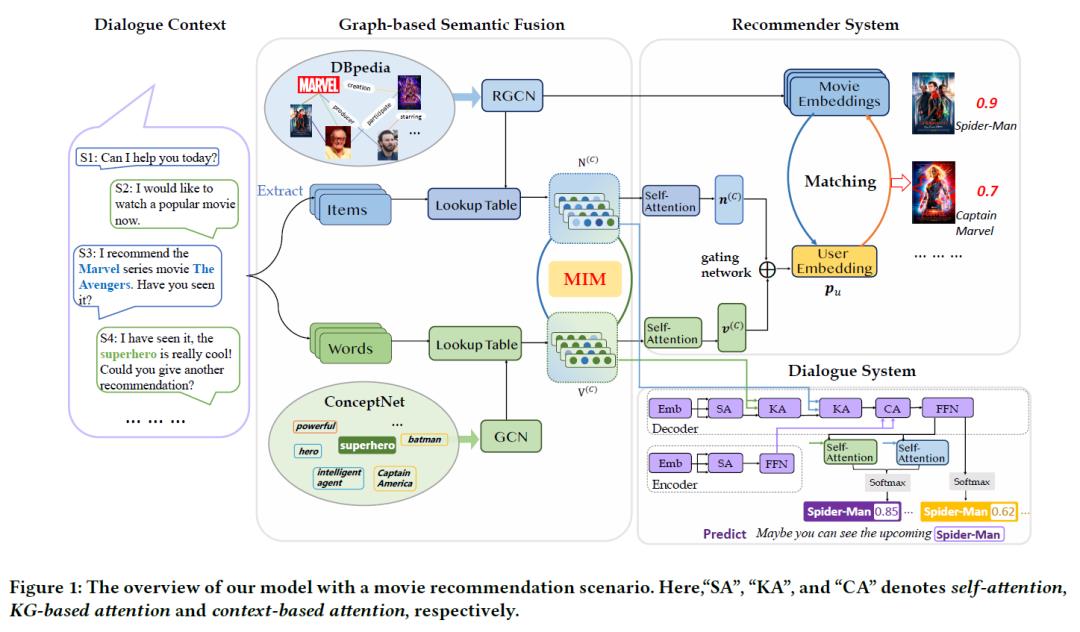
如图展示了电影推荐场景的模型总览。“SA”,“ KA”和“ CA”分别表示自注意力,基于KG的注意力和基于上下文的注意力。
1、编码外部知识图谱
本文将对话系统和推荐系统中基本语义单元分别定义为word和item,使用两个独立的知识图谱来增强两种语义单元的表达。
1)编码面向word的知识图谱
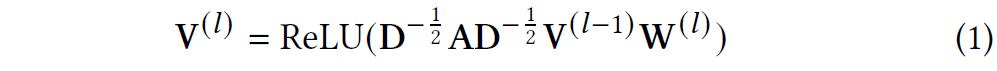
2)编码面向item的知识图谱
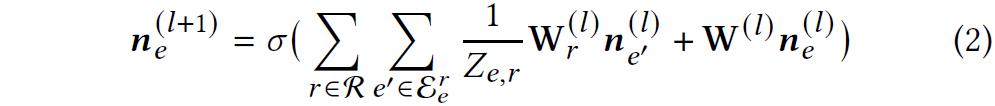
2、使用互信息最大化策略的知识图谱融合
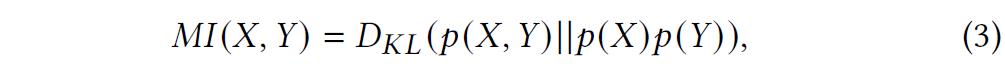
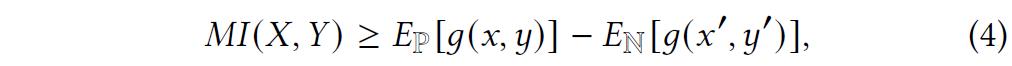
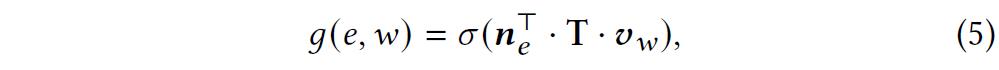
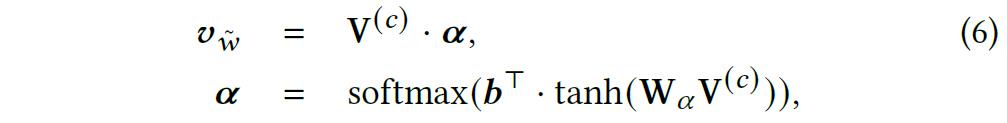
3、知识图谱增强的推荐模块
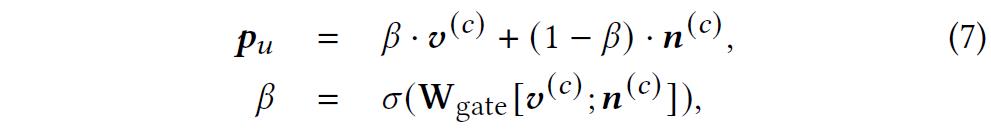
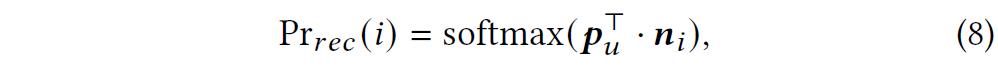
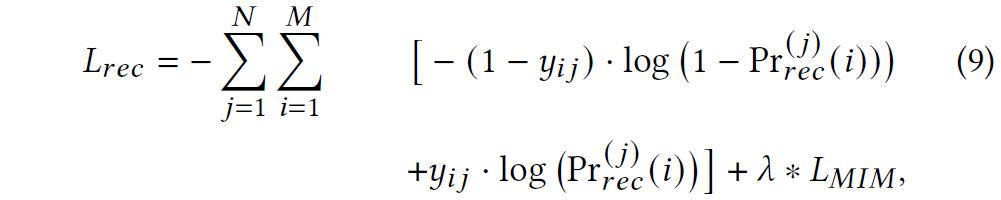
4、知识图谱增强的回复生成模块
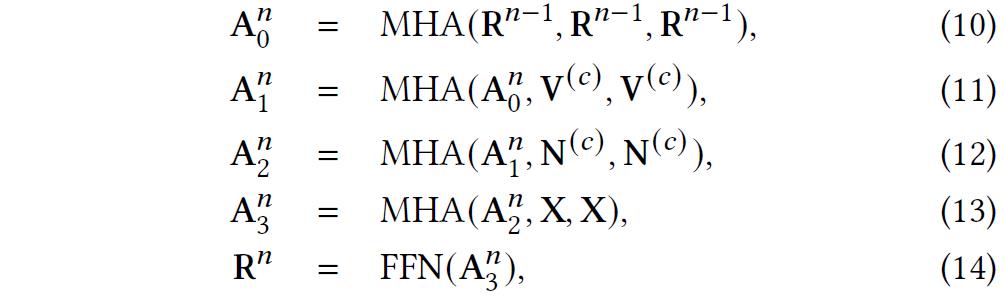
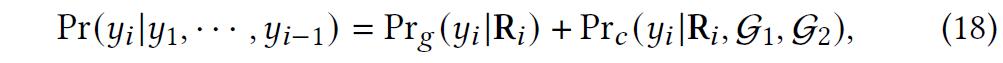
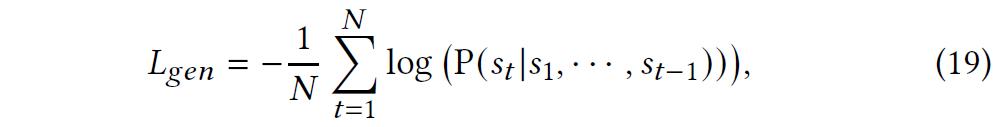
实验与分析
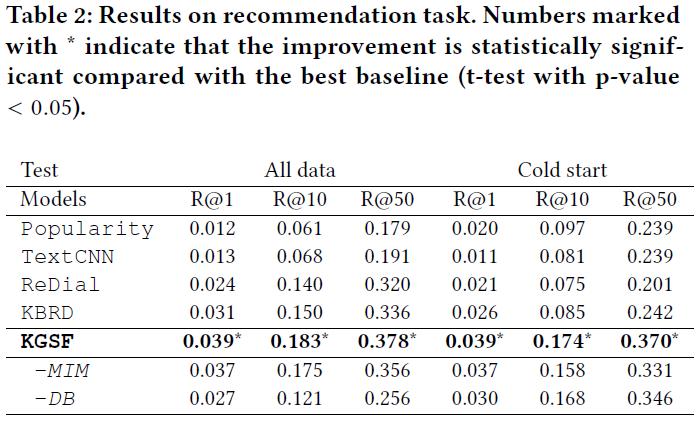
1、推荐任务
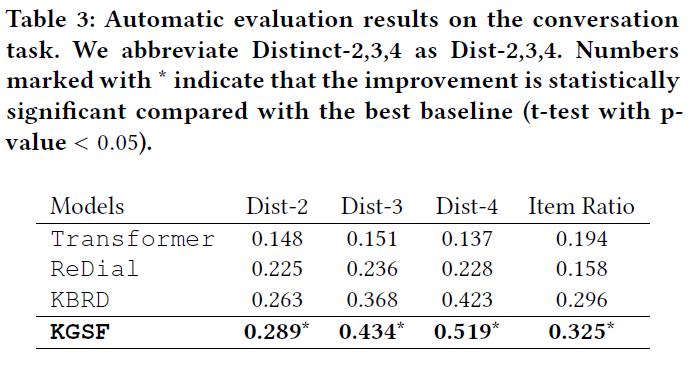
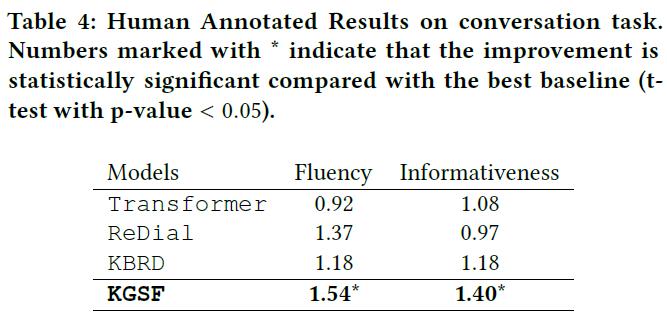
2、生成任务
3、定性分析
小结
参考文献
[1] Yueming Sun and Yi Zhang. 2018. Conversational Recommender System. In SIGIR 2018. 235–244.
[2] Raymond Li, Samira Ebrahimi Kahou, Hannes Schulz, Vincent Michalski, Laurent Charlin, and Chris Pal. 2018. Towards Deep Conversational Recommendations.(2018), 9748–9758.
[3] Robyn Speer, Joshua Chin, and Catherine Havasi. 2017. ConceptNet 5.5: An Open Multilingual Graph of General Knowledge. In AAAI 2017. 4444–4451.
[4] Christian Bizer, Jens Lehmann, Georgi Kobilarov, Sören Auer, Christian Becker, Richard Cyganiak, and Sebastian Hellmann. 2009. DBpedia - A crystallization point for the Web of Data. J. Web Semant. 7 (2009), 154–165.
[5] Graph Convolutional Neural Network. In BMVC 2016
[6] Michael Schlichtkrull, Thomas N. Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. 2018. Modeling Relational Data with Graph Convolutional Networks. Lecture Notes in Computer Science (2018), 593–607.
[7] Fan-Yun Sun, Jordan Hoffmann, Vikas Verma, and Jian Tang. 2020. InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization. (2020).
[8] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. , 5998–6008 pages.
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
以上是关于会话推荐系统新进展:基于互信息最大化的多知识图谱语义融合 | KDD 2020的主要内容,如果未能解决你的问题,请参考以下文章