知识图谱在推荐系统的落地
Posted 情报分析师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识图谱在推荐系统的落地相关的知识,希望对你有一定的参考价值。

情报分析师
全国警务人员和情报人员都在关注
 随着互联网进入了下半场,精益化发展成为了主旋律,为了实现同样的获客成本下收益最大化,各家对推荐系统的需求日益强烈。
随着互联网进入了下半场,精益化发展成为了主旋律,为了实现同样的获客成本下收益最大化,各家对推荐系统的需求日益强烈。
一、什么是推荐系统
推荐系统,正如它的字面信息一样,就是通过推荐内容满足用户个性化的需求,解决信息过载的问题的系统。
推荐系统根据形式的差异接入了不同的场景,在大家的日常生活中就无时不刻都在享受这它的便利。
当你一大早打开淘宝,扫一眼“猜您喜欢”,发现一个自己喜欢的宝贝,直接添加进购物车;打开今日头条,看了下自己感兴趣的新闻,中间看到一个自己不了解的内容,打开百度输入后,输入框下面展示了几个相关内容……
根据推荐的形式能不能清晰地影响用户的操作可以把推荐划分为隐形推荐和显性推荐。
隐形推荐不会对用户预期的操作产生影响,如:新闻排序,搜索结果排序等在用户不知不觉中给用户展现;
显性推荐会改变用户预期的操作,如:输入联想、推荐问句等用户可以根据推荐的内容选择自己期望的内容。
另外,根据推荐的阶段不同,也可以将推荐分为相关性推荐、预测式推荐、生成式推荐。
相关性推荐根据用户当前信息,召回相似度较高的内容作为推荐的内容;
预测式推荐为根据用户历史信息,可以是用户信息、操作记录、购买记录等,预测用户可能感兴趣的内容,作为推荐的内容;
根据用户的信息推荐,不管是相关性还是预测式的都会导致推荐的内容随用户使用时长增加,变得内容单一,降低用户的新鲜感,因此还需要生成一些无关的内容作为推荐的补充,以满足用户的新鲜感,这就是生成式推荐。
二、推荐流程
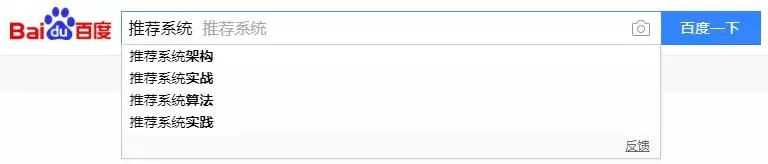
推荐的过程可以简单理解为三个步骤:召回、过滤、排序。
首先系统根据获取到的信息,召回适合推荐内容,获取的信息可以是用户的搜索记录、购买记录、评论等。
召回的内容中有的是这个用户不关注的,可能是他已经买过了的宝贝或者已经看过了的内容,这会儿就需要根据过滤的条件,将不需要的内容进行过滤。
经过过滤产生的推荐集还需要根据内容的相关度进行排序,最后系统根据相关度的排序,将内容分配到对应的模块,这样用户就能看到自己感兴趣的内容了。
有的系统也会将过滤放在第一步,先根据条件过滤一些输入信息,然后喂给推荐系统。
这样能够减少推荐系统的计算量,缩短推荐系统处理时间,提高推荐系统的即时性,但是这么做也会存在一些问题:减少输入导致类别特征的内容丢失,影响推荐系统的内容数量与质量。
三、知识图谱在推荐应用的优势
知识图谱就是实体的属性关系网,能够很好的表达实体之间的关系,这个关系可以是具有同样属性的实体,也可以是上下位的实体关系。
对于推荐系统来说,这个图谱中的实体不仅仅是推荐的内容,还包含了用户的信息,或者是标签,所以知识图谱很好的提供了一个推荐对象的关系网。
通过知识图谱,推荐系统可以很好给你推荐关联内容,例如,你购买了手机,那么它就可以给你推荐充电宝、保护套、钢化膜等,因为在它的脑子中知道这些产品是手机的附件。
也可以通过用户搜索的蓝牙耳机,给他推荐同样具有蓝牙功能的耳机。
四、图谱在推荐中的应用
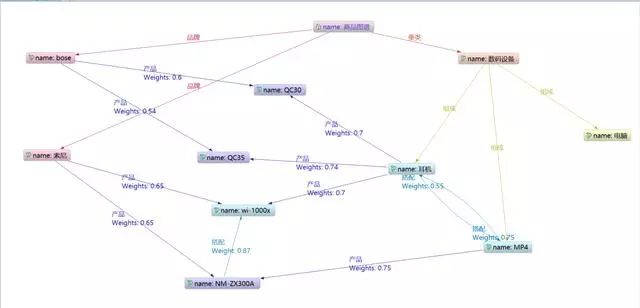
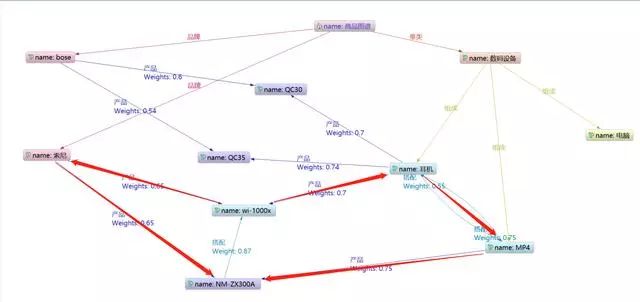
我们通过一个简单的商品图谱和大家讲解图谱推荐的遍历逻辑。这是一个数码垂类下的耳机的简化商品图谱。
1. 下位实体遍历
下位关系是相关性最强的关系,通常包含的含义是下一步操作、必要条件,例如:买了手机就会买手机壳、买了汽车就会买玻璃水等。
不过也不是所有的下位关系都是能放置在推荐序列的前列中的,例如:笔记本贴纸与笔记本相关,但是不是大家都会贴笔记本贴纸,所以下位关系也存在低概率的情况,这部分就会被其他高概率的遍历逻辑给挤到较后的排列中。
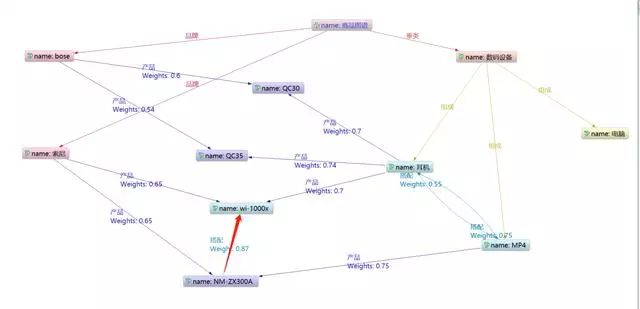
2. 组合属性遍历
在图谱中有的实体由多个相同的父实体连接,这种实体之间通常具有强相关性,就好比是你同父母的亲兄弟,这种推荐也是应用的最多的。
在下面这个实例中就可以理解该用户为bose的忠实用户,计划购买它的耳机,那么我们根据用户搜索QC30的记录,推荐QC35、QC25等结果,这样就既能够提高成交的可能性,也能够实现更高的客单价,实现商家、平台的双赢。
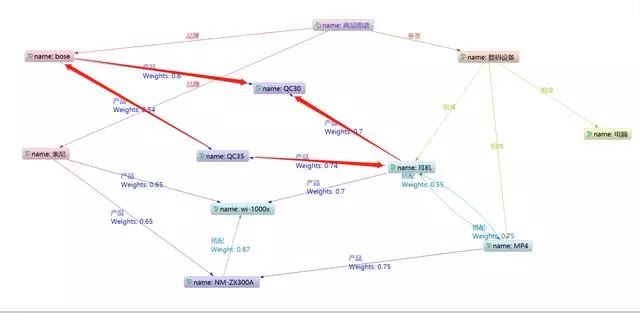
3. 同属性遍历
除了上面两种相关性较强的遍历逻辑之外,相同父实体的子实体也具有相关性,但是我们需要注意当一个实体具有多个父实体的情况下,不是所有的父实体都适合被往下遍历。
例如:用户咨询QC30,那么我们给它推荐bose的家庭音响解决方案就不合适,因为用户本质需求只是购买耳机。
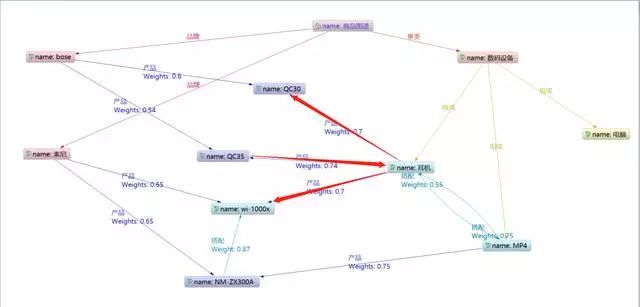
4. 二元实体遍历
二元实体遍历适合同类父实体的场景,同类的父实体通常表示这两个产品是一个互补或者相似的含义。
例如:用户咨询QC30,那么他可能需要一个MP4来搭配他的耳机,同样的情况还有鼠标-键盘、短袖-短裤等。
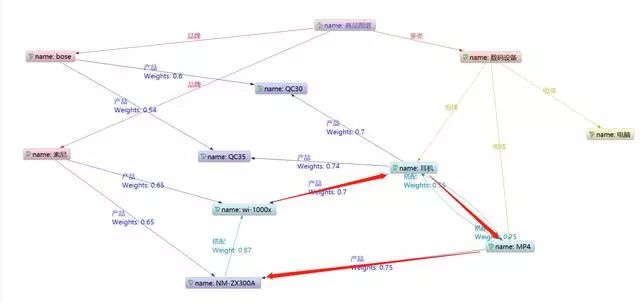
5. 多路径遍历对比
优于图谱中实体之间的关系是网状的,所以在遍历时存在两个实体之间可以通过多种遍历逻辑推理得到。
那么我们就需要采取一种方式来对比那种遍历逻辑的结果才是我们应该采用的。
一般会根据边的权重计算得到两个实体的相关度。
五、如何过滤
根据推荐系统生成的推荐序列过滤推荐结果,这个根据不同业务方的需要会有很大的差别,这里就简单说明一些通用的实例:
1. 时间区间内已经发生期望操作的结果
期望操作是指用户使用产品时,我们期望用户最终实现的行为,可能是点击、购买等。
如果用户已经对推荐的内容发生了期望操作,那么继续推荐这个内容,无疑会浪费有效面积,导致客单量降低。
为了避免这种情况,推荐系统会针对不同的推荐内容设置一个时间区间,在这个时间区间内已经产生过期望操作的就不再进行推荐,例如,服饰可以设置为1个月,快消品则可以设置更短的时间限制。
2. 展示未产生期望操作的结果
一千个读者就有一千个哈姆雷特,面对一千个用户,推荐系统的结果肯定不可能都是一千个都是满意的,所以当推荐的内容用户没有产生期望操作时,系统可以认为该推荐结果对于这个用户是弱关联性推荐或者说是无效推荐,那么系统在再次生成推荐序列是就可以将其过滤,让其他用户可能感兴趣的结果补充进行展示。
3. 同类型的结果
当生成的推荐序列中已经存在很多的同类产品时,我们也需要进行过滤。
同类的结果,用户只会对其中的几个结果产生操作,如果过多地展示同类的内容,就会导致推荐的内容丰富度不够。
一般同类的结果,推荐系统只会保留其中相关度最高的几个,并且在展示上会将同类结果控制放置间隔,避免一起出现。
六、图谱推荐指标
图谱更新前都需要评估相对的效果,只有相对效果优与原先的结果,图谱才能上线。
评估相对结果的指标可以分为服务指标和业务指标。
服务指标是反映图谱服务效果的指标,都是一些客观数据;
业务指标是与业务相关联的,反映的是服务上线后的服务效果的指标。
1. 服务指标
实体识别准确率=实体解析正确数/用户问句总数;
实体识别召回率=实体解析正确数/相关实体总数;
内容相关度=用户评分/推荐数量。
2. 业务指标
展现点击比=用户点击数/展现数量;
转化率=用户产生期望操作数/展现数量。
七、图谱应用的难点
知识图谱虽然在推荐系统中应用存在优势,但是在实际应用中会因为它的种种难点被限制应用,下面和大家一起讲讲图谱应用的困难。
1. 知识图谱schema维护
在推荐系统中应用的图谱都是大规模的图谱,实体都是在万级的,像阿里的商品图谱甚至达到了十亿级。那么大的图谱完全由人工运营维护肯定是不现实的,实际上这些图谱也的确由系统自动进行维护,人工只是辅助进行运营。
系统通过现成的表结构数据、机器阅读理解抽取的实体与关系自动构建知识图谱。
2. 推荐的时效性差
图谱的量级达到了一定,如何快速的万级亿级的实体和属性中找到对应的数据,对于模型来说是一个十分艰巨的工作。
另外大规模的图谱,实体之间的关系密切,如果做到的二元遍历,那么延伸出的实体也是指数量级的,无法直接拿来做推荐。
所以图谱推荐的时效性较差,不适合应用于需要实时返回推荐结果的场景,所以图谱推荐往往应用在用户使用的间隙生成推荐的内容。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。

本期编辑:HNE
本文转载,如有侵权,请联系管理员删除
普及情报思维 传播情报文化
长 按 关 注
【投稿邮箱】
550419913@qq.com
以上是关于知识图谱在推荐系统的落地的主要内容,如果未能解决你的问题,请参考以下文章