《因果科学周刊》第4期:因果赋能推荐系统
Posted 智源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《因果科学周刊》第4期:因果赋能推荐系统相关的知识,希望对你有一定的参考价值。
为了帮助大家更好地了解因果科学的最新科研进展和资讯,我们因果科学社区团队本周整理了第4期《因果科学周刊》,推送近期因果科学值得关注的论文和资讯信息, 同时我们也将向大家介绍社区正在推进的活动——因果科学与Casual AI读书会第8期中的主要报告内容、观点。
因果科学社区简介:它是由智源社区、集智俱乐部共同推动,面向因果科学领域的垂直型学术讨论社区,目的是促进因果科学专业人士和兴趣爱好者们的交流和合作,推进因果科学学术、产业生态的建设和落地,孕育新一代因果科学领域的学术专家和产业创新者。
因果科学社区欢迎您加入!
因果科学社区愿景:回答因果问题是各个领域迫切的需求,当前许多不同领域(例如 AI 和统计学)都在使用因果推理,但是他们所使用的语言和模型各不相同,导致这些领域科学家之间沟通交流困难。因此我们希望构建一个社区,通过组织大量学术活动,使得科研人员能够掌握统计学的核心思想,熟练使用当前 AI 各种技术(例如 Pytorch/Pyro 搭建深度概率模型),促进各个领域的研究者交流和思维碰撞,从而让各个领域的因果推理有着共同的范式,甚至是共同的工程实践标准,推动刚刚成型的因果科学快速向前发展。具备因果推理能力的人类紧密协作创造了强大的文明,我们希望在未来社会中,因果推理融入到每个学科,尤其是紧密结合和提升 AI ,期待无数具备攀登因果之梯能力的 Agents (Causal AI) 和人类一起协作,共建下一代的人类文明!

当今的信息革命时代,信息处理和利用能力是 AI 智能水平的一个重要方面。而因果推理能够帮助我们利用 Lorenzian imagined space 中信息进行决策(Schölkopf B., 2019),因果推理是下一代 AI 的必要组件(Pearl J., 2019, Elias B., 2020)。推荐是信息提取的一种特殊形式,它利用过去的行为和用户相似性来生成一系列信息,这些信息是根据最终用户的喜好量身定制的。
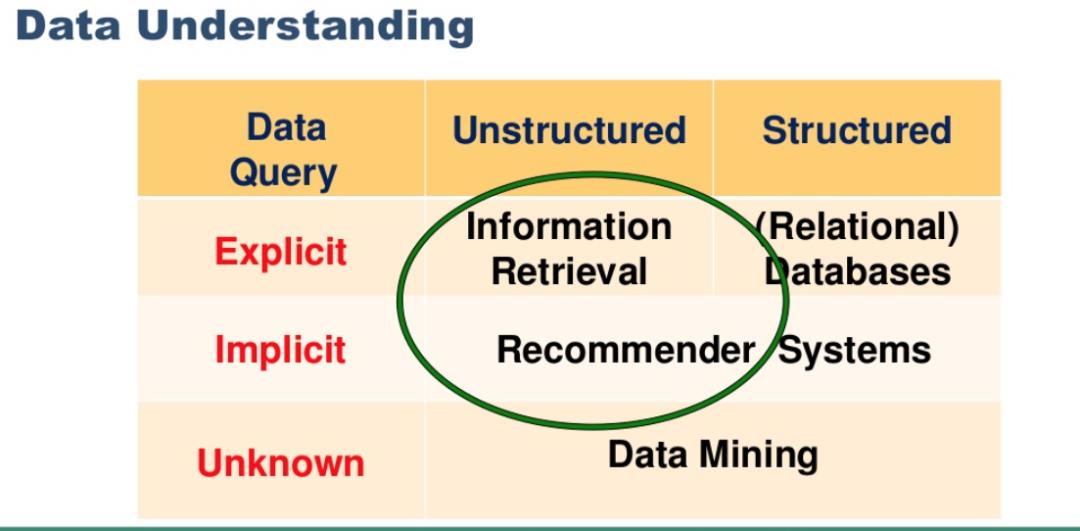
图1:推荐系统的角色(Ricardo Baeza-Yates)
在最近举行的推荐系统最重要的会议 RecSys 2020 中,可以看到学术界和工业界一个重要趋势是有关的 bias 的研究,也就是推荐系统出现的各种偏差让其推荐非预期的 Item。推荐系统的任务被经典地定义为预测用户的偏好和用户评分。然而,它本质上是要回答一个反事实问题:“如果我们‘强迫’用户去看电影,评分会是多少?” 如何使用观测数据正确的训练推荐算法,甚至评估(NOT A/B 测试) 评估推荐系统的性能,使用因果推理 debias 成为其中一个非常 Promising 的方向(Wang Y., 2019, Sharma A., 2015)。
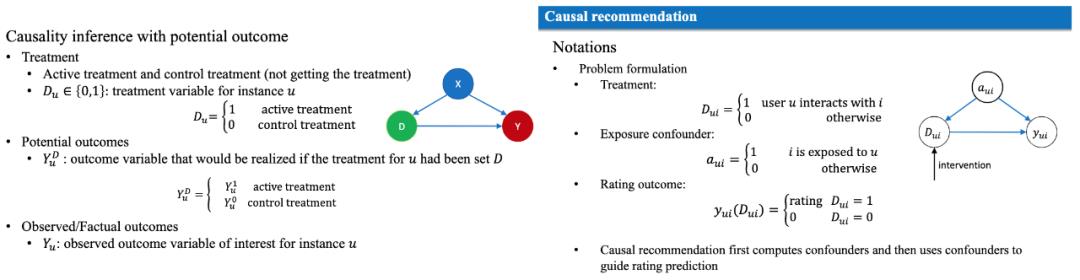
图2: 因果推荐的基本数学形式
此次我们邀请亚利桑那州立大学博士郭若城推荐了一些有关 Causal + RecSyc 的前沿论文,下面是我们的整理:
1.论文推荐
1.1 Unbiased learning to rank
Joachims, Thorsten, Adith Swaminathan, and Tobias Schnabel. "Unbiased learning-to-rank with biased feedback." In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, pp. 781-789. 2017.
翻译摘要:
在人机交互系统中,隐式反馈(例如,点击量,停留时间等)是一个丰富的数据来源。虽然隐式反馈有很多优势(例如,搜集成本低、以用户为中心、及时),它的固有偏差不利于它的有效使用。例如,在搜索排序中,某个结果的位置偏差强烈影响它的点击量,因此,直接使用点击量作为Learning-to-Rank方法(译者注:以下简称LTR)的训练数据会产生次优结果。为了克服这种偏差,我们提出了反事实推理框架,即使在有偏数据下,它也能通过经验风险最小化为无偏的LTR提供理论基础。使用这个框架,我们推导了倾向加权排序的支持向量机用于隐式反馈的判别式学习,这里点击量模型被用来估计倾向性。不同于大部分传统的使用点击量模型去除数据偏差的方法,在没有重复查询的情况下,我们的方法依然能够训练排序函数。除了理论推导,实证分析表明我们提出的学习方法对处理偏差非常有效、对噪声和倾向模型的误识别有稳健性、并且是有效率的。我们也展示了这个方法在现实世界的适用性,在运行的搜索引擎上,它能够持续改善检索水平。
译者:侯茹
Wang, Xuanhui, Nadav Golbandi, Michael Bendersky, Donald Metzler, and Marc Najork. "Position bias estimation for unbiased learning to rank in personal search." In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, pp. 610-618. 2018.
翻译摘要:众所周知,点击量学习的挑战是它的固有偏差,尤其是位置偏差。传统的点击量模型旨在从查询和文档相关性提取信息,在提取相关性信息之后就会去掉估计的偏差。不同于此,最新的无偏Learning-to-Rank方法能够有效地利用偏差,进而着眼于估计偏差而非相关性[20, 31]。现有的方法在小范围的产品流量中随机化搜索结果来估计位置偏差。这不能达到理想结果,因为结果的随机化对用户的搜索体验有不好的影响。本文比较了不同的结果随机化方法并展示了它们对于用户搜索的不利影响。然后,我们研究了如何在不依赖随机化的情况下,从常规的点击量数据推断位置偏差。我们提出了基于回归的期望最大化算法,在位置偏差点击量模型的基础上,能够处理用户搜索中的大量稀疏数据。我们评估了我们的期望最大化算法和Learning-to-Rank方法提取的偏差。我们的结果表明,不使用结果随机化而直接从常规的点击量提取位置偏差是有前景的。提取的偏差能显著改善Learning-to-Rank算法。进一步,我们比较了逐点和逐对的Learning-to-Rank模型。结果表明逐对的模型能更有效地利用估计的偏差。
译者:侯茹
Ai, Qingyao, Keping Bi, Cheng Luo, Jiafeng Guo, and W. Bruce Croft. "Unbiased learning to rank with unbiased propensity estimation." In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pp. 385-394. 2018.
翻译摘要:
用有偏的点击数据学习如何排名是众所周知的挑战。为了学习如何排名,人们探索出多种方法去除点击数据中的偏差,如点击模型、结果交错,还有最近的基于反倾向加权(IPW)的学习如何排名的无偏框架。忽略它们之间的不同点,最近大多数研究致力于从排名算法的学习中单独估计点击偏差(称为倾向模型)。为了估计点击倾向,他们有的进行了在线结果随机化,但这会影响用户体验;有的进行离线参数估计,但对点击数据有特殊要求,而且优化目标(如点击似然)不是直接和排名系统的性能有关。在这个工作中,我们通过结合倾向模型和排名模型来解决这些问题。我们发现从点击数据中估计一个倾向模型是学习无偏排名的一个对偶问题。基于这点观察,我们提出了对偶学习算法(DLA),它可以学习一个无偏的排名器和一个无偏的倾向模型。DLA是自动地无偏地学习排名的框架,因为它从未进行预处理的有偏点击数据中直接学习无偏排名模型。它可以适应偏差分布的变化,可以应用到在线学习中。我们的实验使用了合成的数据集和真实世界的数据集,结果显示:用DLA训练模型的性能明显超过了基于结果随机化的学习排名的算法,和通过用从点击模型中提取的相关性信号训练的模型。
译者:闫和东
Guo, Ruocheng, Xiaoting Zhao, Adam Henderson, Liangjie Hong, and Huan Liu. "Debiasing Grid-based Product Search in E-commerce." In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2852-2860. 2020.
翻译摘要:
随着电子商务在日常生活的广泛使用,丰富的隐式反馈数据为训练和测试网购搜索排序算法提供了基础。尽管便于搜集,隐式反馈数据有多种固有偏差,因为现有的搜索排序算法使得用户的反馈仅局限在接触到的产品,并且受产品展示方式的影响。大部分现有的方法在基于列表的网页搜索场景中实现无偏的排序学习。然而,这些方法不能直接用于电子商务网站,有下述两个原因。第一,在电子商务网站中,搜索引擎结果页面以2维格点表示,而现有的方法并不考虑基于列表的网页搜索和基于格点的产品搜索的用户行为差异。第二,在电子商务网站有多种类型的隐式反馈(例如,点击和购买),我们的目标是将所有类型的隐式反馈作为监督信号。本文考虑了基于格点的产品搜索场景,将无偏的排序学习拓展到电子商务搜索。我们提出了新颖的框架,一方面形成了在无偏的排序学习中使用多种隐式反馈的理论基础,另一方面包含了行省略和缓慢衰减的点击模型,在基于格点产品搜索的逆向倾向评分中抓取独特的用户行为模式。在大量现实世界中不同浏览设备和产品的电子商务搜索记录数据集上的试验表明,我们提出的框架优于最先进的无偏排序学习算法。这些结果同时揭示了在不同浏览设备和产品中用户行为模式如何变化。
译者:侯茹
1.3 Debiasing Recommendation systems
Guo, Ruocheng, Xiaoting Zhao, Adam Henderson, Liangjie Hong, and Huan Liu. "Debiasing Grid-based Product Search in E-commerce." In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2852-2860. 2020.
翻译摘要:
随着电子商务在日常生活的广泛使用,丰富的隐式反馈数据为训练和测试网购搜索排序算法提供了基础。尽管便于搜集,隐式反馈数据有多种固有偏差,因为现有的搜索排序算法使得用户的反馈仅局限在接触到的产品,并且受产品展示方式的影响。大部分现有的方法在基于列表的网页搜索场景中实现无偏的排序学习。然而,这些方法不能直接用于电子商务网站,有下述两个原因。第一,在电子商务网站中,搜索引擎结果页面以2维格点表示,而现有的方法并不考虑基于列表的网页搜索和基于格点的产品搜索的用户行为差异。第二,在电子商务网站有多种类型的隐式反馈(例如,点击和购买),我们的目标是将所有类型的隐式反馈作为监督信号。本文考虑了基于格点的产品搜索场景,将无偏的排序学习拓展到电子商务搜索。我们提出了新颖的框架,一方面形成了在无偏的排序学习中使用多种隐式反馈的理论基础,另一方面包含了行省略和缓慢衰减的点击模型,在基于格点产品搜索的逆向倾向评分中抓取独特的用户行为模式。在大量现实世界中不同浏览设备和产品的电子商务搜索记录数据集上的试验表明,我们提出的框架优于最先进的无偏排序学习算法。这些结果同时揭示了在不同浏览设备和产品中用户行为模式如何变化。
译者:侯茹
Schnabel, Tobias, Adith Swaminathan, Ashudeep Singh, Navin Chandak, and Thorsten Joachims. "Recommendations as treatments: Debiasing learning and evaluation." ICML 2016..
翻译摘要:
大部分推荐系统的评估和训练数据是受限于选择偏差的,这种偏差要么通过用户自身选择产生、要么通过推荐系统的行为产生。本文中,我们提出一种通过因果推断调整模型和估计器的原则性方法来解决选择偏差的问题。这种方法可以在有偏数据上导出无偏的性能估计器,结合矩阵分解的方法显著提升了在真实世界数据中的预测性能。我们从理论和经验上刻画了该方法的鲁棒性,并且发现它具有高度的可行性和可扩展性。
译者:陈晗曦
Chen, Minmin, Alex Beutel, Paul Covington, Sagar Jain, Francois Belletti, and Ed H. Chi. "Top-k off-policy correction for a REINFORCE recommender system." In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, pp. 456-464. 2019.
翻译摘要:
工业界推荐系统会处理非常大的动作空间(action spaces)——数百万 Items 来进行推荐。同时,他们需要服务数十亿的用户,这些用户在任意时间点都是唯一的,使得用户状态空间(user state space)很复杂。幸运的是,存在海量的隐式反馈日志(比如:用户点击,停留时间等)可用于学习。从日志反馈中学习是有偏的,这是因为只有在推荐系统上观察到的反馈是由之前版本的推荐系统选中的。在本文中,我们提出了一种通用的方法,在 Youtube 生产环境上的 Top-k 推荐系统中,使用一个基于策略梯度的算法(policy-gradient-based algorithm,比如:REINFORCE),来解决这样的偏差。该论文的主要贡献有:1)将 REINFORCE 扩展到生产环境推荐系统上,动作空间有数百万;2)使用 off-policy correction 来解决在从多种行为策略中收集的日志反馈的数据偏差;3)提出了一种新的 Top-K off-policy correction 来解释我们一次推荐多个 Items 的策略推荐;4)展示了探索的价值我们通过一系列仿真和 Youtube 的多个真实环境,来展示我们的方法的效果。
译者:龚鹤扬
Yang, Longqi, Yin Cui, Yuan Xuan, Chenyang Wang, Serge Belongie, and Deborah Estrin. "Unbiased offline recommender evaluation for missing-not-at-random implicit feedback." In Proceedings of the 12th ACM Conference on Recommender Systems, pp. 279-287. 2018.
翻译摘要:
隐式反馈推荐器 (Implicit-feedback Recommenders, ImplicitRec) 只利用诸如点击这样的积极的“用户-项目”互动来学习个性化用户偏好。不同推荐器通常使用从在线平台收集的数据集进行离线评估和比较。这些平台受到流行度偏差的影响(比如,受欢迎的项目更容易被呈现给用户并得到互动),因此日志的“基准真相数据”(监督学习的标注数据)存在完全非随机缺失(Missing-Not-At-Random, MNAR)。所以被广泛使用的总体平均评估器(Average-Over-All, AOA)在评估受欢迎的项目的准确推荐时是有偏差的。在这篇文章中,我们(a)研究了AOA的评估偏差,以及(b)使用逆倾向评分(Inverse-Propensity-Scoring, IPS)技术为隐式MNAR数据集开发一个无偏且实用的离线评估器。通过使用四个真实世界数据集和四个广泛使用的算法的广泛实验,我们表明(a)流行度偏差广泛出现在项目呈现和互动中;(b)AOA用于评估ImplicitRec时,由于MNAR数据导致的评估偏差在大多数情况下普遍存在;(c)根据平均绝对误差(MAE),无偏估计显著减少了雅虎音乐数据集中超过30%的AOA评估偏差。
译者:陈天豪
Bonner, Stephen, and Flavian Vasile. "Causal embeddings for recommendation." In Proceedings of the 12th ACM Conference on Recommender Systems, pp. 104-112. 2018.
翻译摘要:
许多现有应用使用推荐的方式来修改自然用户的行为,例如提升销量或网站的浏览时间。这导致了最终的推荐目标与经典设定产生不一致,在经典设置中,通过预测user-item matrix中缺少的条目或最可能的下一个事件,通过与用户过去行为的一致性来评估推荐候选。为了弥补这种不一致,我们优化了一个用于相对用户自然行为增加预期输出的推荐策略。我们展示了这个策略和在完全随机的推荐策略下学习预测推荐输出是等价的。最后,我们提出一种新的领域自适应算法,它从包含偏差推荐策略产生的数据中学习,预测随机推荐策略下的推荐输出。我们将我们的方法和现有的SOTA分解方法进行比较,并且和新的因果推荐方法比较,结果取得了显著的提升。
译者:陈晗曦
2. 会议:RecSys 2020等
RecSys 2020(14th ACM Conference on Recommender Systems Online, Worldwide, 22nd-26th September 2020) 是推荐系统方向最重要的一个会议,它展现了的一个重要趋势是强调 B sias,Ricardo Baeza-Yates 做了一个关于此主题的报告来系统梳理各种不同的 bias 有关研究。
图3: 推荐系统中的 Bias
除了 RecSys 之外,其他与推荐系统相关的重要会议包括 sigkdd, wsdm, sigir 等。
3. 近期社区活动
2020年11月15日上午9点,“因果科学与Causal AI”读书会进行了第8期的线上论文分享,主题是“因果机器学习”。
分享者:郭若城,亚利桑那州立大学在读博士
个人主页:https://www.public.asu.edu/~rguo12
让我们考虑两种动物,会学人说话的鹦鹉和乌鸦喝水中的乌鸦。我们知道鹦鹉只会模仿人类的语音,却不知道语言的意义。而乌鸦可以认识到放入石子就可以使水面上升这一层因果关系。我们可以把鹦鹉看作是能做curve fitting的机器学习模型而把乌鸦看作是体现变量之间因果关系的因果模型。比起问它们谁更聪明,我想更有意义的做法是结合他俩的技能,帮助我们解决实际问题。在机器学习在很多任务中已取得成功的今天,我们想回答的问题是:因果推断能否帮助机器学习在一些任务中做得更好,以及因果推断能否受益于新的机器学习算法?在这次的读书会中,我会从这两个方面来介绍一些现存的结合因果推断和机器学习的研究方向。在传统的利用观测性数据的因果推断中,很多模型往往通过很强的、可能不能被满足的假设来避免考虑hidden confounders。而最近的一些工作中,我们发现利用深度学习模型我们可以利用观测性数据中附带的网络信息弱化这一假设,提升因果推断模型的表现。机器学习模型的一些问题也可以利用其背后的因果模型来解决或者缓解。这里的第一个问题是,如何使神经网络更加鲁棒?从因果性的角度,鲁棒意味着我们要避免学习到spurious correlation?比如在动物图像分类中,骆驼常常出现在沙漠中,如何能避免分类器利用沙漠背景来预测骆驼这个类?最近,在Invariant Risk Minimization (IRM) 这个工作中,作者们把具体问题中因果关系的限制条件转化成了机器学习模型中的inductive bias,从而达到这一目的。而在我们的工作中,我们发现IRM是一个过于宽泛的条件。针对这一问题我们提出了一个简单有效的解决方案。第二个问题是,在使用用户反馈作为标签的机器学习任务中,如何做到利用历史数据在线下对新模型进行评测和优化,使其线上效果得到提升。在最近的推荐系统和搜索的工作中,人们发现把用户反馈标签的因果图融入模型设计将使我们在这一任务中做得更好。
演讲大纲:
Machine learning for causal inference
* Learning causality with networked observational data
Causality-aware machine learning
* Out-of-distribution prediction with causal inductive bias
* Unbiased interactive machine learning
在机器学习已经在很多任务中已经取得成功的今天,我们想回答的问题是:因果推断能否帮助机器学习在一些任务中做得更好以及,因果推断能否受益于新的机器学习算法?在这次的读书会中,郭若城将会从这两个方面来介绍一些现存的结合因果推断和机器学习的研究方向。在传统的利用观测性数据的因果推断中,很多模型往往通过很强的,可能不能被满足的假设来避免考虑hidden confounders。而最近的一些工作中,他们发现利用深度学习模型可以利用观测性数据中附带的网络信息弱化这一假设,提升因果推断模型的表现。
读书会精彩问答:
整理:杨二茶
Q:请问一下若城,是否关注过因果推断和推荐系统match的工作?以及这些工作是否涉及cofounding的问题?
A:用推荐系统的离线数据去match在线distribution曾经有一篇顶会文章叫Causal embedding accommodation用过这个思想。机器学习中提confounding其实是很奇怪的,我们知道,confounding导致bias的原因是因为causal effect estimation。所以当你需要测度T—>Y的因果效应,你去建立confounder的实质是为了建立其他变量的关系,因此,你必须得有数据分布上的变化,才能去解决confounding的问题。机器学习很少去探究一个变量T到另一个变量Y的影响,你只想预测Y而已。推荐系统中也有很多研究,推荐系统对population有什么因果效应,这种情况也是可以通过condition on X来解决。
Q:有没有一些文章来解决bias的问题?举个例子,如果这个场景是给病人吃药,但药有不同成分,不同病人的成分组合不同,对病人抽样有bias,那么我们如果进行debias的工作呢?我们主观上0的分类并不一定是真实场景中的分类?如果我找到一个confounder,但同时confounder又有很多的话,应该如何处理?
A:causal inference的核心解决的就是这个问题,通过control confounder来解决miss的confounder来建模。所以其本质是一个unobserved cofounder的问题,因为你不可能知道所有的confounder,所以你只能尽量发现更多的confounder来预测treatment effect。不控制confounder的话,就很难去掉这种干扰的影响。其实现在,除了随机实验以外,我们还没有其他办法可以去掉其他confounder(对主效应)的影响。
了解读书会具体规则、报名读书会请点击下方文章:
时间:9月20日起,每周日晚19:00-21:00,持续约2-3个月
模式:线上闭门读书会;收费-退款的保证金模式;读书会成员认领解读论文
费用:299元/人
内容安排:
图注:针对读书会的主题,由发起人龚鹤扬设置好了内容框架,每个主题下有一个负责人来负责维护组织相关内容,目前已经定好的如图所示,欢迎对主题感兴趣的联系相关负责人,以及来认领相关主题。
以上是关于《因果科学周刊》第4期:因果赋能推荐系统的主要内容,如果未能解决你的问题,请参考以下文章
[思维模式-12]:《如何系统思考》-8- 工具篇 - 因果回路图/系统循环图/系统控制图,系统思考的关键工具