聊聊如何提升推荐系统的结果多样性
Posted 夕小瑶的卖萌屋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊如何提升推荐系统的结果多样性相关的知识,希望对你有一定的参考价值。
文 | 洪九(李戈)
源 | 知乎
个性化推荐系统的出现为处理信息过载问题提供了一个有效的工具,已经成为互联网各大平台(电商、信息流等)的标配,并在技术(个性化召回、个性化排序等)上取得了长足的发展,逐渐从传统模型过度到深度学习时代。但是,当前个性化推荐以及相关算法的关注点大多数在提高推荐的精准性,而忽略了推荐结果的多样性,导致容易出现"high similar items were clustered together"现象,即相似的Item扎堆,用户的兴趣被局限到一个相对"较窄"(信息量为0的"精准推荐")的推荐视野中,进而伤害了用户体验(尤其是兴趣宽泛、偏逛、需求不明确的用户)。如下图,可以看到在手淘的首页推荐流中展示了多个类目的商品,比如3C、卫衣、化妆品等,可见已经关注了多样性问题。

推荐系统的多样性反应了一个推荐列表中内容不相似的程度。通过推荐多样性更高的内容,既能够给用户更多的机会去发现新内容,也能够让推荐系统更容易发现用户潜在的兴趣。但需要注意的是,精确性和多样性是一对Trade Off,提升多样性的代价往往以牺牲准确性为代价,因此如何平衡准确性和多样性是一个需要权衡的地方,或者从另一个角度讲如何在短期目标和长期目标间做平衡。 对比专卖店和大型综合超市(银座、万达等),专卖店(Nike专卖店、苹果专卖店等)的购买准确率高于大型综合超市,但由于大型综合超市的多样性比较好,客人在超市内可以有购物、看电影等多种选择,因此客人在超市内花费的时间就约长,留存也就越高。
需要特别注意的是:多样性不是目标,但是实践证明多样性可以帮助提升时长、点击、用户长期留存等核心业务指标。此外,与精排阶段的点击率预估(用户是否点击)任务不同,多样性处理通常是没有groudtruth(真值)的,通常需要A/B实验来确定多样性策略的优劣。
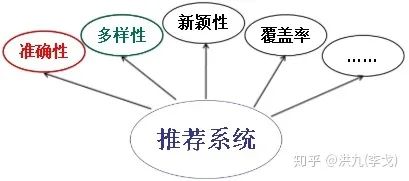
推荐多样性问题的本质是排序中CTR(点击率)或类似(CVR转化率等)预估问题是单点(Point-wise)最优预测,而通常真实业务中往往是给到用户一个列表(List-wise排列组合优化),即Point-wise和List-wise之间往往存在着较大的Gap。
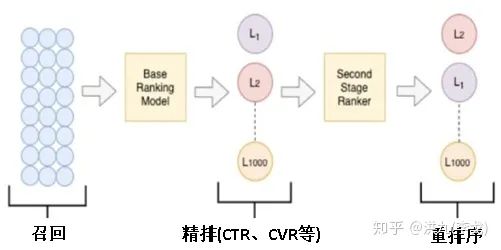
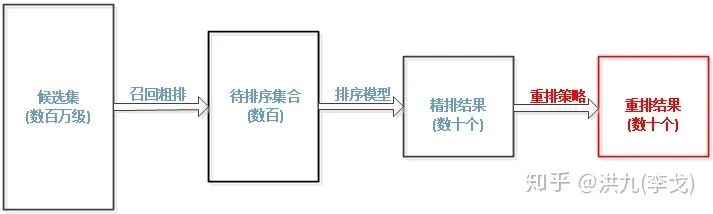
如上图是典型推荐系统的核心流程,为了增强推荐结果的多样性,通常可以在各个阶段采取不同的改进策略。比如在召回阶段,可以融合不同推荐召回算法的推荐结果,即多路召回。在重排序阶段多样性优化策略,工业界的代表性方法有:MRR(Maximal Marginal Relevance), Google、Youtube和Hulu推荐的DPP(Determinantal Point Process),阿里提出的基于Transformer的PRM,Google、Youtube提出的基于强化学习的模型SlateQ等。
下面会分别介绍:
-
推荐多样性类型 -
推荐多样性评价指标 -
推荐多样性策略 -
召回多样性策略 -
精排层(Rank)多样性策略 -
重排序(Rerank)多样性策略 -
于用户多样性偏好的策略
1.推荐多样性类型
推荐多样性类型包括个体多样性、总体多样性、时序多样性。
-
个体多样性
个体多样性从单个用户的视角衡量推荐的多样性,考察系统能够找到用户喜欢的冷门项目的能力。
-
总体多样性
总体多样性主要强调针对不同用户的推荐应尽可能的不同。也就是所谓的"千人千面"。
-
时序多样性
时序多样性是指用户兴趣的动态进化或者用户情景的时变,即与过去的推荐相比,新的推荐体现出的多样性。
评价一个推荐系统的多样性可以从以上三个维度考量。
2. 推荐多样性评价指标**
无法衡量就无法优化,对于多样性通常可以参考如下衡量指标。
2.1 ILS(intra-list similarity)
ILS主要是针对单个用户,一般来说ILS值越大,单个用户推荐列表多样性越差。
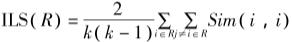
其中, 和 为Item, 为推荐列表长度, 为相似性度量。
2.2 海明距离(Hamming distance)
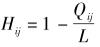
其中, 为推荐列表长度, 为系统推荐给用户 和 两个推荐列表中相同Item的数量。 衡量了不同用户间的推荐结果的差异性,其值越大说明不同用户间的多样性程度越高。
2.3 SSD (self-system diversity)
SSD指推荐列表中没有包含在以前的推荐列表中的比例,主要考察推荐结果的时序多样性。
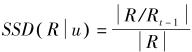
其中, 是 的上一次推荐, 。SSD值越小,推荐列表的时序多样性越好。
2.4 覆盖率(coverage)
覆盖率是推荐给用户的Item占所有Item的比例,用来衡量对长尾Item的推荐能力。
2.5 次重复率
在一次推荐请求中,同一类别的Item连续出现 次的比率。
2.6 Hellinger距离
通过计算生成的topK结果的多样性分布和理想的多样性分布之间的Hellinger距离,来衡量top K结果多样性的好坏。
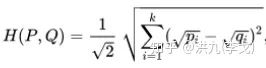
其中, 和 为离散概率分布。
对于特定维度的理想多样性分布,可以基于用户反馈统计。可以参考下文中介绍的思路。
谷育龙Eric:Airbnb搜索:重排序阶段如何优化搜索结果多样性?(https://zhuanlan.zhihu.com/p/239824669)
3.推荐多样性策略
3.1 召回多样性策略
3.1.1 多路召回策略
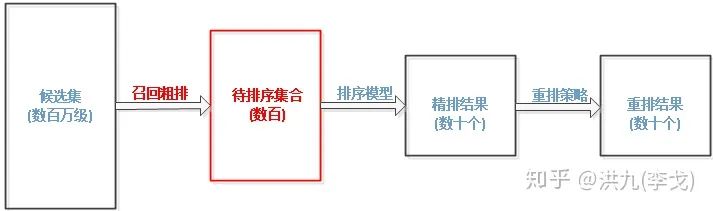
俗话说"巧妇难为无米之炊",从上图召回阶段(红色框)在推荐系统流程中的位置可以看出,如果召回阶段候选集本身不具备多样性,例如只有开心内容,就无法保证整个推荐系统的多样性。因此解决推荐系统的多样性问题,首先需要考虑的是召回阶段的多样性。实践中通常使用多路召回保证更多样的内容可以进入后续阶段,工程上可以采用多线程并发召回。
不同召回策略在准确性、多样性、新颖性、覆盖率等指标上存在较大差异,综合利用各路召回给后面的策略更大的发挥空间。

3.1.2 长尾多样性优化
常见的基于协同过滤的召回算法(ItemCF、DSSM等)容易导致"热门"推荐"热门",使得长尾的"利基"Item被淹没,因而不利于推荐多样性,此时可以考虑如下策略缓解。
-
热度降权
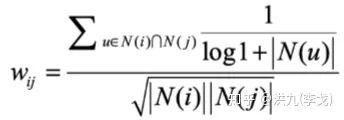
在原有相似度计算公式中对Item的热度做降权。
-
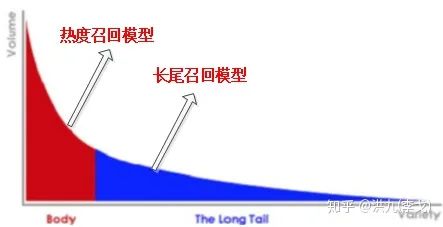
热度模型分割
基本思想如下图所示:
3.1.3 用户兴趣多样性探索
在基于用户兴趣标签的召回策略中,往往使得用户兴趣标签收敛到固定的标签子集。理想的情况是,对于用户明确表达出兴趣的标签以较大的概率曝光,而对于用户没有行为的标签也以一定的概率曝光。
如下图用户-算法-内容三者交互图:
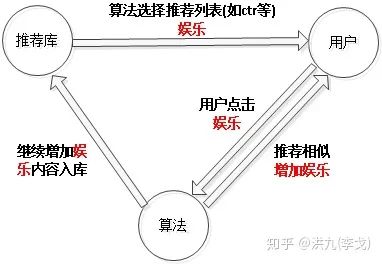
由于推荐库中娱乐类的数量和热度占有较大优势,推荐给用户的娱乐类就比较多,同时用户点击娱乐的概率越大,会更加倾向于给用户推荐娱乐类内容。此外,由于协同过滤算法的效应,导致推荐给其他用户的娱乐类内容也偏多。为了缓解此问题,可以借助MAB(multi-arm bandit)中的EXP3算法。
EXP3,全称是Exponential-weight algorithm for Exploration and Exploitation,即勘探和开发的指数权重算法。EXP3简要流程如下:
EXP3,初始化各个"臂"的权重因子,每一轮:
-
1). 根据"臂"的权重分布随机抽样下一次选择的臂(比如各个标签等)。 -
2). 定义估计量(比如CTR、CVR、时长占比等)。 -
3). 依据反馈更新选中臂的权重因子。
随机抽样保证了每个臂都有可能被抽取到,避免了收敛到固定的几个臂,同时收益较优的臂被抽取的可能性较大,从而确保了推荐的准确性。

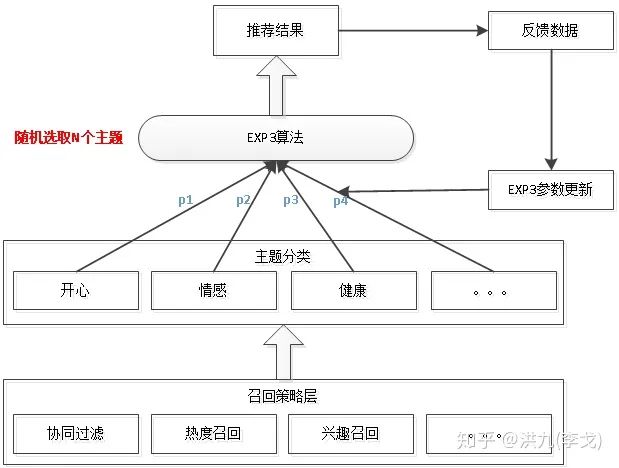
在推荐系统中的运用如下:
Python Code(参考自https://github.com/j2kun/exp3)
from probability import distr, draw
import math
import random
# exp3: int, (int, int -> float), float -> generator
# perform the exp3 algorithm.
# numActions is the number of actions, indexed from 0
# rewards is a function (or callable) accepting as input the action and
# producing as output the reward for that action
# gamma is an egalitarianism factor
def exp3(numActions, reward, gamma, rewardMin = 0, rewardMax = 1):
weights = [1.0] * numActions
t = 0
while True:
probabilityDistribution = distr(weights, gamma)
choice = draw(probabilityDistribution)
theReward = reward(choice, t)
scaledReward = (theReward - rewardMin) / (rewardMax - rewardMin) # rewards scaled to 0,1
estimatedReward = 1.0 * scaledReward / probabilityDistribution[choice]
weights[choice] *= math.exp(estimatedReward * gamma / numActions)
yield choice, theReward, estimatedReward, weights
t = t + 1
def test():
numActions = 10
numRounds = 10000
biases = [1.0 / k for k in range(2,12)]
rewardVector = [[1 if random.random() < bias else 0 for bias in biases] for _ in range(numRounds)]
rewards = lambda choice, t: rewardVector[t][choice]
# 计算最优的臂(娱乐、健康类目等)
bestAction = max(range(numActions), key=lambda action: sum([rewardVector[t][action] for t in range(numRounds)]))
bestUpperBoundEstimate = 2 * numRounds / 3
gamma = math.sqrt(numActions * math.log(numActions) / ((math.e - 1) * bestUpperBoundEstimate))
cumulativeReward = 0
bestActionCumulativeReward = 0
weakRegret = 0
t = 0
for (choice, reward, est, weights) in exp3(numActions, rewards, gamma):
cumulativeReward += reward
bestActionCumulativeReward += rewardVector[t][bestAction]
weakRegret = (bestActionCumulativeReward - cumulativeReward)
regretBound = (math.e - 1) * gamma * bestActionCumulativeReward + (numActions * math.log(numActions)) / gamma
t += 1
if t >= numRounds:
break
print(cumulativeReward)
3.2 精排层(Rank)多样性策略
通过在精排模型中加入User、Item、环境特征,达到在不同的维度的多样性,一般来讲特征越丰富个性化越强同时多样性越强。
3.3 重排序(Rerank)多样性策略
重排序的本质是最大化list-wise的打分函数 ,在相关性和多样性间取得平衡,从运筹学角度来讲是一个典型的组合优化问题,一般也是NP-Hard(不能在有限时间内得到精确最优解)。
3.3.1 基于规则的多样性策略
1).去重策略
对于已经推荐的Item,短时间内不再进行推荐。在内容治理角度讲,需要尽量保证推荐源没有重复Item。
2).频控策略
对于具有相同属性的Item,比如作者、类别等,短时间内控制推荐的次数。这里的"短时间",在不同业务场景不同Item类型都是不一样的,比如用户一次请求、用户session会话周期、商品复购周期等。
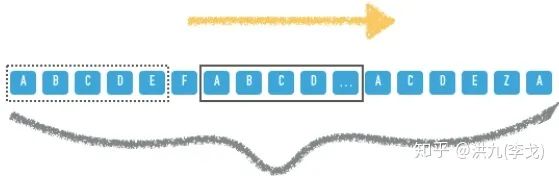
3).打散策略
-
最小间隔 ,即最多允许某一类别连续出现 次,尽量避免用户感觉到内容的同质化。 -
最多次数 , 即最多允许某一类别在一次请求中出现 次。 -
窗口打散,即在大小为 的窗口(下图中 )内不允许出现同一类目的Item。
-
分桶打散
该方法把长度为N的物品序列在关键指标维度下进行分桶打散,桶内可以按相关性进行倒排, 然后依次取桶内排序靠前的物品,最终生成topk个结果。
推荐看这一篇——《百年芭蕾:推荐系统漫谈之多样性策略》https://zhuanlan.zhihu.com/p/268363776
4).长尾加权
降低热门Item被推荐的概率,提升冷门"利基"Item被推荐的概率,提高长尾新颖性。可以使用逆用户频率做加权:
3.3.2 MMR (Maximal Marginal Relevance)- 最大边界相关算法
推荐系统多样性问题需要在准确性和多样性之间做平衡(trade off)。在搜索中,MMR算法将排序结果的相关性与多样性综合在下列公式中:
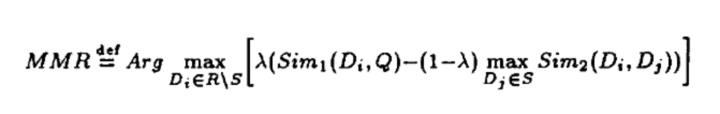
其中, 表示待查询文档, 表示候选集, 表示已经选择的集合, 权重系数(用来调节准确性和多样性), 表示查询文档和候选集间的相关度, 表示候选文档间的相似度。
上式的含义是从未选择的集合(R\S)中选择一个文档 加入到 使得相关性与与已选择列表集合的相关性的差值最大,即选择与用户最相关同时与已选择文档最不相似的文档。
另外,在搜索中 代表查询Query,而在推荐中 可以代表用户。在推荐中, 可以用预估CTR表示, 可以计算两两Item间的泛化特征(类目、Tag、作者等)相似度。
参考代码(如侵删):
def MMR(itemScoreDict, similarityMatrix, lambdaConstant=0.5, topN=20):
s, r = [], list(itemScoreDict.keys())
while len(r) > 0:
score = 0
selectOne = None
# 遍历所有剩余项
for i in r:
firstPart = itemScoreDict[i]
# 计算候选项与"已选项目"集合的最大相似度
secondPart = 0
for j in s:
sim2 = similarityMatrix[i][j]
if sim2 > second_part:
secondPart = sim2
equationScore = lambdaConstant * (firstPart - (1 - lambdaConstant) * secondPart)
if equationScore > score:
score = equationScore
selectOne = i
if selectOne == None:
selectOne = i
# 添加新的候选项到结果集r,同时从s中删除
r.remove(selectOne)
s.append(selectOne)
return (s, s[:topN])[topN > len(s)]
MMR算法的时间复杂度是 ,实际中一次不需要返回给用户太多Item,可以限制下时间复杂度。
3.3.3.3 DPP 行列式点过程多样性算法
先回顾下行列式的相关知识。
-
行列式定义
行列式是由一些数据排列成的方阵经过规定的计算方法而得到的一个数。在二维平面中,矩阵行列式的绝对值代表一个平行四边形的面积;在三维空间中,矩阵行列式的绝对值代表一个平行六面体的体积。
二阶行列式:
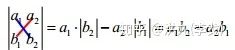
三阶行列式:
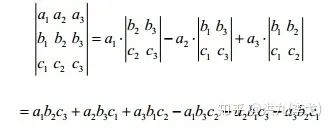
几何意义:
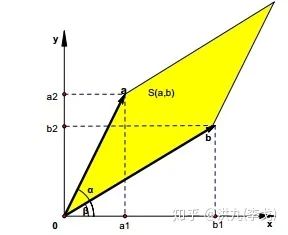
二阶行列式的几何意义就是由行列式的向量所张成的平行四边形的面积。对于两个推荐Item的语义向量,如果向量间的夹角比较小,则向量所构成的面积也就越小,同时行列式值也就越小。相关关系传递如下:
语义向量相似=>夹角较小=>面积较小=>行列式较小
如下图所示:
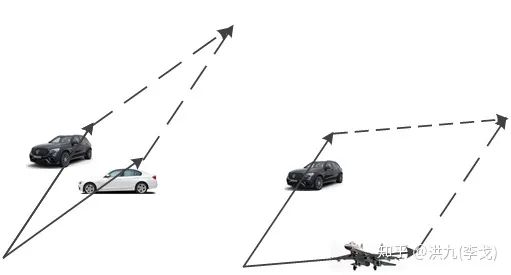
这样我们就在"向量语义相似"和"矩阵行列式"之间建立起联系。
阶行列式定义:

泛化到 阶行列式就是: 行列式中的行或列向量所构成的超平行多面体的有向面积或有向体积。
-
Cholesky Decomposition (Cholesky分解)
如果半正定矩阵 且 ,则 可以分解成如下形式:
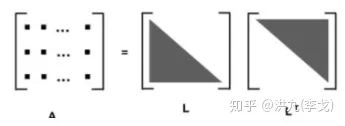
其中 和 如下:
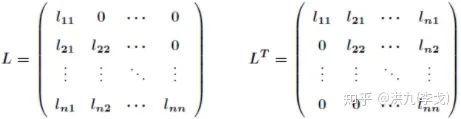
Cholesky分解在线形代数中起到非常重要的作用。Cholesky分解把矩阵分解为一个下三角矩阵以及它的共轭转置矩阵的乘积(类比于实数求平方根运算),与一般的矩阵分解求解方程的方法比较,Cholesky分解效率很高。

Tips:Cholesky是生于19世纪末的法国数学家,曾就读于巴黎综合理工学院。Cholesky分解是他在学术界最重要的贡献。后来,Cholesky参加了法国军队,不久在一战初始阵亡。
-
行列式点过程(Determinantal point process)
行列式点过程(Determinantal Point Process, DPP) 是一种性能较高的概率模型,DPP将复杂的概率计算转换成简单的行列式计算,在图片分割、文本摘要和商品推荐系统中均具有较成功的应用。在推荐中,DPP通过最大后验概率估计,找到商品集中相关性和多样性最大的子集,从而作为推荐给用户的商品集。
(鬼话连篇~_~) 行列式点过程
刻画的是一个离散集合
中每个子集合出现的概率。当
给定空集合的概率时,存在一个由集合
的元素构成的半正定矩阵
,对于每一个集合
的子集
,使得子集
出现的概率
,其中,
表示有行和列的下标属于
构成的矩阵
的子矩阵。
接下来解释讲解,如果将相关性(准确性)和多样性融入到上面所讲的DPP数学模型中。
首先设列向量 ,其中:
-
为item i与user之间的相关性(比如可以为ctr等),且 -
为item i的语义向量 -
为item i 与 item j之间的相似度度量,且
接着构造 矩阵:
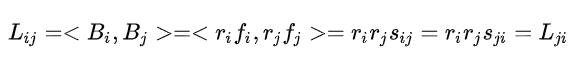
显然, 为实对称矩阵,同时也是半正定矩阵。从 中任意抽取子矩阵 ,那么 矩阵也为实对称矩阵(半正定矩阵)。
进一步由行列式的定义以及运算规则得:
至此,将相关性和多样性统一到 的行列式计算:

即从 中任意抽取子矩阵 使得 最大,则集合 就是我们希望的结果。建立如下的最优化问题:
然而,从一个离散集合中选取子集合是一个组合优化问题,典型的NP-Hard问题。陈拉明团队则利用贪婪算法,提出了一种能加速行列式点过程推理过程的方法。通常NP难的组合优化问题,由于线上实时性的限制,有效解决方法无非是贪心策略以及更聪明的贪心策略,去寻找一个近似最优解。而贪心策略包含两个核心要素:
-
初始解的选取。好的起点非常重要。 -
迭代策略。好的方向事半功倍。
为了构造有效的贪婪算法,陈拉明将原始最优化问题变成如下形式:
因此,这里的迭代策略是每次贪心的选取使得 增长最大的 , 用经济学中的概念就叫做"边际收益",即做出投入产出最大的决策。之所以加 是由于其先增长较快后增长缓慢,因此有利于加快迭代的收敛速度,如下图:
似乎找到了一个好的贪心迭代策略,但实际上行列式 的计算也是非常time-costed,讲到这里,Cholesky分解终于要闪亮登场了。
其中 为可逆的下三角矩阵。对任意 , 的Cholesky分解可以定为:
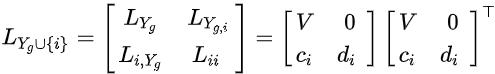
其中,等式右边右上角的子矩阵为0向量,是因为 是一个下三角矩阵。
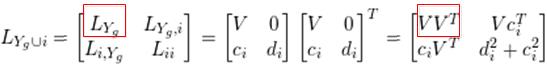
根据矩阵乘法公式(上图, ),行向量 和标量 满足:
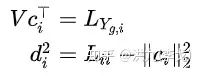
同时也可以根据 的定义得到如下关系:
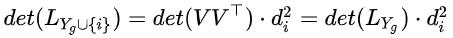
附录推导上述公式所用到的公式如下(自己试着推导下^_^):
-
分块上(下)三角矩阵的行列式
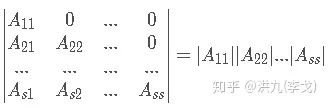
表示矩阵 的行列式
-
矩阵乘积的行列式定义
设 和 都是 阶矩阵,则
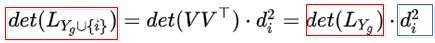
也就是说候选子集的行列式值可以通过增量更新的方法计算,即 和 是已经计算出来了的,当一个新item被添加到 之后, 的Cholesky因子可以被有效更新。
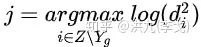
对于每个 , 和 也是可以被增量更新的,将 和 定义为新的需求求解的向量和标量,其中 ,其中 为上一个新添加的item。根据前面的结论可以做如下运算:
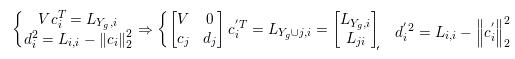
得到 :

进而 :
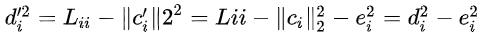
在算法开始时,即 时 ,根据前面提到的如下公式:
可以推导出 ,具体到推荐系统也就是贪心的选择相关性(CTR、CVR等)最大item。

参考代码(出处:绝密伏击:行列式点过程DPP在推荐系统中的应用https://zhuanlan.zhihu.com/p/95607668):
import numpy as np
import math
class DPPModel(object):
def __init__(self, **kwargs):
self.item_count = kwargs['item_count']
self.item_embed_size = kwargs['item_embed_size']
self.max_iter = kwargs['max_iter']
self.epsilon = kwargs['epsilon']
def build_kernel_matrix(self):
rank_score = np.random.random(size=(self.item_count)) # 用户和每个item的相关性
item_embedding = np.random.randn(self.item_count, self.item_embed_size) # item的embedding
item_embedding = item_embedding / np.linalg.norm(item_embedding, axis=1, keepdims=True)
sim_matrix = np.dot(item_embedding, item_embedding.T) # item之间的相似度矩阵
self.kernel_matrix = rank_score.reshape((self.item_count, 1)) \
* sim_matrix * rank_score.reshape((1, self.item_count))
def dpp(self):
c = np.zeros((self.max_iter, self.item_count))
d = np.copy(np.diag(self.kernel_matrix))
j = np.argmax(d)
Yg = [j]
iter = 0
Z = list(range(self.item_count))
while len(Yg) < self.max_iter:
Z_Y = set(Z).difference(set(Yg))
for i in Z_Y:
if iter == 0:
ei = self.kernel_matrix[j, i] / np.sqrt(d[j])
else:
ei = (self.kernel_matrix[j, i] - np.dot(c[:iter, j], c[:iter, i])) / np.sqrt(d[j])
c[iter, i] = ei
d[i] = d[i] - ei * ei
d[j] = 0
j = np.argmax(d)
if d[j] < self.epsilon:
break
Yg.append(j)
iter += 1
return Yg
if __name__ == "__main__":
kwargs = {
'item_count': 100,
'item_embed_size': 100,
'max_iter': 100,
'epsilon': 0.01
}
dpp_model = DPPModel(**kwargs)
dpp_model.build_kernel_matrix()
print(dpp_model.dpp())3.3.3.4 基于概率的启发式算法
前面讲过重排序本质上是个组合优化问题。而MRR、DPP等都是基于贪心的策略,容易陷入局部最优解。了解运筹学相关算法的同学应该听说过模拟退火算法,其以一定概率跳出局部最优解,缓解了贪心法的缺点。
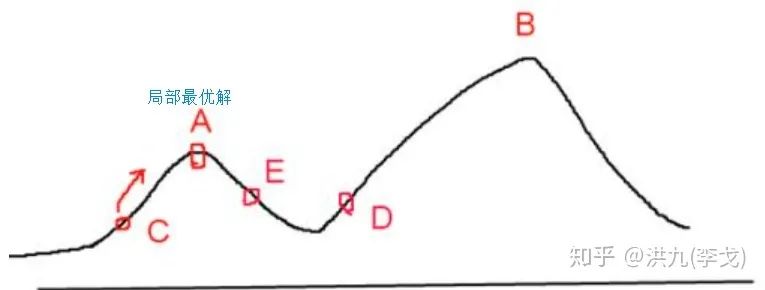
算法流程如下:
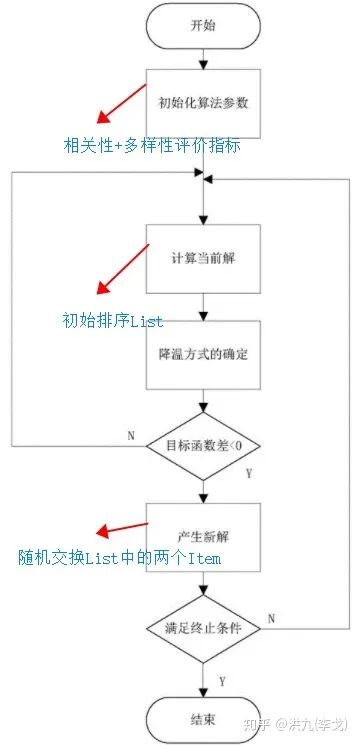
模拟退火的核心:
-
初始解,基于贪心法获得初始解。 -
邻域搜索算子,比如随机交换两个Item。 -
相关参数,收敛性判定准则。
参考谷育龙Eric:Airbnb搜索:重排序阶段如何优化搜索结果多样性?(https://zhuanlan.zhihu.com/p/239824669) 中的Location Diversity Ranker小节。
3.3.3.5 基于模型的多样性打分
3.4 基于用户多样性偏好的策略
目前为止我们在用户维度上无差异的讨论多样性策略,事实上不同用户对多样性的诉求也是不同的。例如针对重度二次元用户,放宽多样性限制反而是比较友好的。针对用户多样性偏好的差异性进一步细化多样性策略也是一个优化方向。
经验上,对低活用户,优先考虑准确率,忽略荐多样性;对高活用户,可以牺牲部分准确性来换取多样性。除去经验性的认知外,对于行为较丰富的高活用户可以设计相关指标来衡量多样性偏好,可以考虑如下指标:
1). 用户交互物品的平均流行度
推荐结果的物品流行程度很大程度上和推荐结果的多样性是正相关联系的。如果一个用户交互过的Item的平均流行度相对较低,则说明该用户的类目偏好性比较强,应该减弱多样性。
2). 用户多样性熵
利用信息论中的熵对多样性进行建模。熵是热力学领域的概念,可以度量"无序化"的程度,在信息论中则用来衡量不确定程度。如果用户访问的各类目Item分布比较均匀,则熵值较大,反之熵值较小(比如只点击二次元内容)。
其中, 为用户对 类目的访问概率。
在得到用户的多样性熵后就可以针对不同用户采用差异化的多样性策略了,比如各种超参数的取值等。
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
[1]推荐系统应该如何保障推荐的多样性?https://www.zhihu.com/question/68299606/answer/776092528
[2]腾讯QQ大数据:神盾推荐--MAB算法应用总结https://blog.csdn.net/kl28978113/article/details/96303148 http://www.360doc.com/content/18/0714/21/3175779_770404760.shtml
[3]曹欢欢:推荐内容的多样性越好,用户的长期留存概率越大http://scitech.people.com.cn/GB/n1/2019/0712/c1007-31229289.html
[4]信息流推荐多样性https://blog.csdn.net/chunyun0716/article/details/103376936
[5]推荐多样性研究讲述https://max.book118.com/html/2017/0329/97669662.shtm
[6]个性化推荐系统的多样性研究进展http://www.doc88.com/p-0137412059454.html
[8]【实践】信息流推荐算法实践 & 深入https://blog.csdn.net/dengxing1234/article/details/79756265
[9]初读师兄论文---面向多样性的推荐算法研究https://blog.csdn.net/qq_28298991/article/details/80697205
[10]Set Cover Problem (集合覆盖问题)https://www.jianshu.com/p/df54fade1269
[11]EXP3算法https://blog.csdn.net/weixin_39550091/article/details/102484513
[12]贪心算法:集合覆盖问题https://blog.csdn.net/zhi_neng_zhi_fu/article/details/101752753
[13]Multi-armed Bandits(多臂老虎机问题)https://blog.csdn.net/wangh0802/article/details/87913867
[14]冷启动中的多臂老虎机问题(Multi-Armed Bandit,MAB)https://blog.csdn.net/Gamer_gyt/article/details/102560272
[15]推荐系统-推荐列表多样性处理
[16]LTV预测模型:如何实现高质量用户增长https://leeguoren.blog.csdn.net/article/details/96989034
[17]通过实例运营策略提升推荐结果多样性https://help.aliyun.com/document_detail/171774.html
[18]面向个性化推荐的偏好多样性建模研究进展https://m.163.com/newsapp/applinks.html
[19]多模态商品推荐与认知智能背后的数学https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/105248807
[20]Hulu是如何提升推荐多样性的?https://blog.csdn.net/hulu_beijing/article/details/107538159
[21]基于行列式点过程的推荐多样性提升算法的直观理解https://www.zhihu.com/question/68299606/answer/776092528
[22]Determinantal point process 入门 https://blog.csdn.net/qq_23947237/article/details/90698325
[23]长尾推荐算法论文阅读笔记合集https://blog.csdn.net/qq_41536315/article/details/104527428
[24]A Generic Top-N Recommendation Framework For Trading-off Accuracy, Novelty, and Coveragehttps://blog.csdn.net/qq_35771020/article/details/87854554
[25]【论文阅读笔记】Challenging the Long Tail Recommendation(挑战长尾推荐)https://blog.csdn.net/qq_41536315/article/details/103762117
[26]Airbnb搜索:重排序阶段如何优化搜索结果多样性?https://zhuanlan.zhihu.com/p/239824669
[27]矩阵行列式的几何意义https://www.cnblogs.com/tsingke/p/10671318.html
[28]fast-map-dpp介绍http://d0evi1.com/fast-map-dpp/
[29]《基于行列式点过程的推荐多样性提升算法》原理详解https://blog.csdn.net/yz930618/article/details/84862751
[30]【推荐系统】行列式点过程(DPP)算法推导https://blog.csdn.net/qq_41629800/article/details/107339054
[31]行列式https://www.pianshen.com/article/94381258640/
[32]基于排序学习的Top-N推荐算法研究
[33]行列式点过程的简单介绍https://www.doc88.com/p-8089116412071.html
[34]baidu Query-Ad Matching算法介绍http://d0evi1.com/baidu-matching/
[35]个性化推荐系统的多样性研究进展http://www.doc88.com/p-0137412059454.html
[36]推荐系统怎样实现多路召回的融合排序https://zhuanlan.zhihu.com/p/90796257
[37]召回模块:多召回策略https://blog.csdn.net/zimiao552147572/article/details/106976141
[38]推荐系统学习笔记——八、推荐系统多路召回融合排序https://blog.csdn.net/Lynnzxl/article/details/105251213
[39]推荐系统从0到1[二]:个性化召回https://cloud.tencent.com/developer/article/1174893
[40]推荐算法总结(召回+排序+工程化)https://blog.csdn.net/qq_34219959/article/details/104495432
[41]推荐系统召回策略之多路召回与Embedding召回https://juejin.im/post/6854573221707317261
[42]【】转载】搜狗信息流推荐算法实践(推荐工作流理解-召回、排序)_败八-CSDN博客https://blog.csdn.net/ChaosJ/article/details/94302505
[43]基于Embedding的推荐系统召回策略https://www.ctolib.com/amp/topics-138378.html
[44]The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries
[45]wide_deep https://github.com/Lapis-Hong/wide_deep
[46]Contextual Bandit算法在推荐系统中的实现及应用https://zhuanlan.zhihu.com/p/35753281
[47]行列式点过程DPP在推荐系统中的应用https://zhuanlan.zhihu.com/p/95607668
[48]Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity https://proceedings.neurips.cc/paper/2018/file/dbbf603ff0e99629dda5d75b6f75f966-Paper.pdf
[49]UC 信息流推荐模型在多目标和模型优化方面的进展https://zhuanlan.zhihu.com/p/86607378
[50]从贪心选择到探索决策:基于强化学习的多样性排序https://zhuanlan.zhihu.com/p/56053546
[51]Diversified Retrieval(多样性检索,MMR,DPP)https://blog.csdn.net/qq_39388410/article/details/109706683
[52]多样性算法在58部落的实践和思考https://blog.csdn.net/hellozhxy/article/details/108982131
以上是关于聊聊如何提升推荐系统的结果多样性的主要内容,如果未能解决你的问题,请参考以下文章