推荐多样性重排算法之MMR
Posted Wang_AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐多样性重排算法之MMR相关的知识,希望对你有一定的参考价值。
“ 本文介绍了推荐系统中的多样性重排序算法Maximal Marginal Relevance (a.k.a MMR) ,并给出了该算法的python实现代码。”
文章来源:icebear https://zhuanlan.zhihu.com/p/102285855
Maximal Marginal Relevance (a.k.a MMR) 算法目的是减少排序结果的冗余,同时保证结果的相关性。最早应用于文本摘要提取和信息检索等领域。在推荐场景下体现在,给用户推荐相关商品的同时,保证推荐结果的多样性,即排序结果存在着相关性与多样性的权衡。
MMR算法原理
MMR算法将排序结果的相关性与多样性综合于下列公式中:
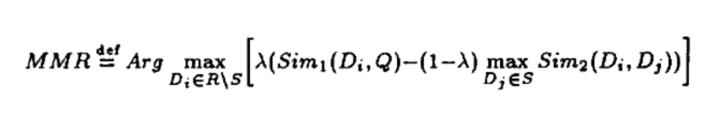
: 用户;
: 推荐结果集合;
: 中已被选中集合; R\\S: 中未被选中集合;
λ : 权重系数,调节推荐结果相关性与多样性
这个公式的含义是每次从未选取列表中选择一个使得和(可以是用户也可以是)的相关性与与已选择列表集合的相关性的差值最大,这就同时考虑了最终结果集合的相关性和多样性,通过 因子来平衡。
Python实现
def MMR(itemScoreDict, similarityMatrix, lambdaConstant=0.5, topN=20):
s, r = [], list(itemScoreDict.keys())
while len(r) > 0:
score = 0
selectOne = None
for i in r:
firstPart = itemScoreDict[i]
secondPart = 0
for j in s:
sim2 = similarityMatrix[i][j]
if sim2 > second_part:
secondPart = sim2
equationScore = lambdaConstant * (firstPart - (1 - lambdaConstant) * secondPart)
if equationScore > score:
score = equationScore
selectOne = i
if selectOne == None:
selectOne = i
r.remove(selectOne)
s.append(selectOne)
return (s, s[:topN])[topN > len(s)]
实验结果
MMR算法需要输入推荐商品的相关分数及商品间相似度矩阵。简单起见,采用Item-based协同过滤算法进行Top- N商品推荐。利用协同过滤算法矩阵分解的Item Factors作为商品的向量表征,计算余弦相似度,并将相似度进行线性映射到[0,1]区间,得到商品相似度矩阵。用户 对商品 的相关分数计算如下式:
某用户最近历史浏览商品序列如下图,分别为 男式地表强温廓形羽绒服 、 透气保暖元绒棉花被 、 男式加厚保暖长款羽绒服 、 男式地表强温工装羽绒服 。

按照协同过滤算法为用户推荐Top10商品,除了直观上对比Top10推荐结果,推荐系统中常常采用下面多样性定量评价指标:
基于用户浏览的四件商品进行Top-10推荐, 协同过滤 推荐结果与 协同过滤+MMR推荐结果如下两图,前者推荐结果相对单一,满屏幕全是羽绒服。后者在推荐坑位有限的情况下,多样性指标上明显更优,除了羽绒服、羽绒被外,还有大衣、运动服、羽绒马甲等商品。



可以根据实际推荐场景,选择合适的相似度计算方法和 值。 越大,推荐结果越相关; 越小,推荐结果多样性越高。
参考文献
-
The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries (https://www.cs.cmu.edu/~jgc/publication/The_Use_MMR_Diversity_Based_LTMIR_1998.pdf)
-
Maximal Marginal Relevance to Re-rank results in Unsupervised KeyPhrase Extraction (https://medium.com/tech-that-works/maximal-marginal-relevance-to-rerank-results-in-unsupervised-keyphrase-extraction-22d95015c7c5)
(完)
以上是关于推荐多样性重排算法之MMR的主要内容,如果未能解决你的问题,请参考以下文章