如何高效地将SQL数据映射到NoSQL存储系统中
Posted 程序员日志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何高效地将SQL数据映射到NoSQL存储系统中相关的知识,希望对你有一定的参考价值。
↑↑↑
当你决定关注「日志君」,你已然超越了99%的程序员
日志君导读:
SQL与NoSQL的结合使用能够相互利用两者的优点。FoundationDB的键-值存储系统为SQL层带来的好处包括可伸缩性、容错性及全局ACID的事务属性。你的应用程序同样也能从中受益,因此赶紧尝试一下吧!
通常来说,我们都知道:
SQL数据库只限在单机上运行,但它提供了更强的事务管理、schema与查询功能。
NoSQL数据库为了伸缩性与容错性的目的,放弃了事务管理与schema。
而FoundationDB的SQL层结合了这两个方面:它首先是一个开源的SQL数据库,能够线性地伸缩与提升容错性,并且还具有真正的ACID事务功能。曾经互不相容的两种特性,现在已融合在一个统一的系统中。
对于处于以下几种情况的公司来说,这一特性是非常重要的:
新的项目要为大规模的伸缩性进行计划。
现有的项目遇到了数据库伸缩性的瓶颈。
现有的许多项目希望能用一个唯一的、容错性强的数据库抽象层统一工作模式。
在本文中,我将为读者介绍,并解释是怎样将SQL数据映射到后台系统中的。
NoSQL数据库 ——FoundationDB的键-值存储系统
FoundationDB是一个分布式的键-值存储系统,支持全局ACID事务操作,并且性能出众。在安装系统时,可以指定。数据分发为容错性提供了支持:当某个服务器或网络的某部分产生故障时,数据库仍然可以正常操作,你的应用也不会受到影响。
键-值与SQL架构
我们开发的这套架构能够在键-值存储系统上支持多个层,每个层都能够在FoundationDB的基础上提供一套不同的数据模型,例如SQL数据库、文档数据库或图形数据库。许多使用者也自行创建了自定义的层。
下图中列出架构中的了关键部分。处于最底层的是FoundationDB集群,无论集群的实际大小如何,对它的操作与一个单独的逻辑数据库并没有分别。SQL层则以一种无状态的中间层方式运行在键-值存储系统之上。这一层通过SQL与应用程序进行通信,并使用FoundationDB的客户端API与键-值存储系统进行通信。由于SQL层是无状态的,因此可以并行地运行任意数据的SQL层。
SQL层为键-值存储系统带来了如Google的F1般的能力
SQL层是对SQL与键-值存储API进行转换的一套逻辑严密的层。首先,SQL层会从一条SQL语句开始,将其转换为最高效地键-值操作。这种方式类似于编译器将代码转换为低级别的执行格式。并且,这种转换是完全符合ANSI SQL 92标准的。开发者可以将该功能与ORM、REST API进行接合,或者直接使用SQL层的命令行界面进行调用。从代码的角度来说,SQL层与键-值存储是完全分离的,它是通过FoundationDB的Java绑定方式与键-值存储进行通信的。感兴趣的读者可以查看,其代码是完全开源的。眼下唯一能够和这套系统进行比较的是,后者是一套基于该公司的Spanner技术所创建的SQL引擎。
如以下的简单图例所示,SQL层是由一系列组件所组成的。应用程序通过某种受支持的SQL客户端向SQL层发送查询语句,在解析之后转换为一棵计划节点树。优化器(Optimizer)会计算最佳的执行计划,并以一棵操作符树的方式表现出来,随后由执行框架(Execution Framework)运行。在执行阶段,对数据的请求将被发送到存储虚拟(Storage Abstraction)层,这一层通过使用Java的键-值API在数据与FoundationDB集群之间进行传输。数据库模型将存放在Information Schema层中,这一层将被其它多个组件所调用。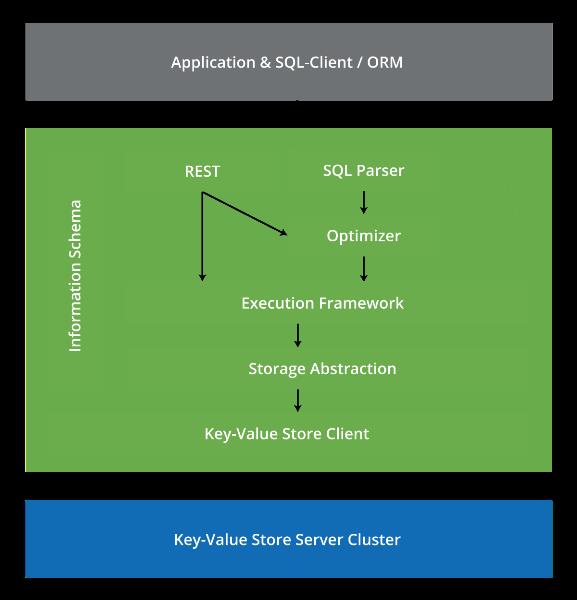
将SQL数据映射到键-值存储系统
SQL层需要管理两种类型的数据,首先是信息Schema的元数据,它负责描述所创建的表与可用的索引。其次,它还需要存储实际的数据,包括表内容、索引及序列。我们首先来描述一下这些数据是如何保存在键-值存储系统中的。
本质上讲,每个键都是对应了某张表中的特定行的指针,而值则包含了该行的数据。键的分配是由Table-Group所决定的,它是包含了一个或多个表的组。稍后会对这个概念的细节进行更深入的讲解。SQL层会通过使用键-值存储目录层为每个Table-Group创建一个目录,存储目录层是为用户管理键空间的一个工具,它为每个独立的目录分配一个简短的字节数组,作为该目录的唯一键。同时,它也维护着其它元数据,以实现通过名称进行查找的功能。
下面这个例子演示了如何创建目录的映射,通过以下语句分配键。
CREATE TABLE schema_a.table1(id INT PRIMARY KEY, c CHAR(10));
CREATE TABLE schema_a.table2(id INT PRIMARY KEY);
在键-值存储系统中有一些预定义的目录:
在存储数据时,可以选择使用以下三种格式中的一种:“元组(Tuple)”、“原始数据(Row_Data)”或者是“Protobuf”。如果使用默认的Tuple存储格式,那么每一行内容都将保存为一个单独的键-值对,键是通过连接以下字符串所生成的元组:目录前缀、该表在Table-Group中的位置,以及主键。而值的内容则是由该行中的所有列所组成的一个元组。
举例来说,以下代码对之前创建的表进行操作,产生对应的键与值。
INSERT INTO schema_a.table1 VALUES (1, 'hello'), (2, 'world');
INSERT INTO schema_a.table2 VALUES (5);
了解了键-值存储系统中键的结构之后,你就能够从存储系统中直接读取数据了。我们将使用FoundationDB的Python API来演示这一功能。在SQL层中,键与值是通过“.pack()”方法进行编码,并通过“.unpack()”方法进行解码的。下面的示例为你演示如何获取并解码数据。
import fdb fdb.api_version(200)
db = fdb.open()
directory = fdb.directory.open(db,('sql','data','table','schema_a','table1'))
for key, value in db[directory.range()]: print fdb.tuple.unpack(key), ' --> ', fdb.tuple.unpack(value)
以上代码会输出类似下面的结果:
(215, 1, 1) --> (1, u'hello')
(215, 1, 2) --> (2, u'world')
现在让我们再来近距离观察一下Table-Group。每个独立的表都属于一个单独的组,如果某张额外的表能够创建一个对第一张表的“组外键”引用,那么它也能够加入到同一个组中。当我们为某张表创建组外键时,字表将与父表所在的目录进行交互。字表将成为Table-Group的一部分,在源表之后进行命名。这两张表的数据在将同一个目录中进行交互,这保证了范围扫描的高速,并且在Table-Group之内访问对象及表连接的开销极小。为了演示这一特性,我们将继续之前的示例,这一次的SQL语句如下:
CREATE TABLE schema_a.table3(id INT PRIMARY KEY, id_1 INT, GROUPING FOREIGN KEY (id_1) REFERENCES schema_a.table1(id));
INSERT INTO schema_a.table3 VALUES (100, 2), (200, 2), (300, 1);
该语句将返回以下结果:
directory = fdb.directory.open(db,('sql','data','table','schema_a','table1'))
for key, value in db[directory.range()]: print fdb.tuple.unpack(key), ' --> ', fdb.tuple.unpack(value)
(215, 1, 1) --> (1, u'hello')
(215, 1, 1, 2, 300) --> (300, 1)
(215, 1, 2) --> (2, u'world')
(215, 1, 2, 2, 100) --> (100, 2)
(215, 1, 2, 2, 200) --> (200, 2)
由于第三张表的键都处于第一张表中各行的命名空间范围内,因此第三张表中所有插入的行都能够与第一张表的行相关联。键中的两个额外的值分别对应了Table-Group中的位置以及第三张表中的主键。对表1与表3通过引用键进行连接也无需通过标准的连接操作实现,直接通过线性扫描就语句了。这种排序方式比起传统的关系型数据库系统有着极大的优势。
由于键都已经经过排序,因此索引可以直接利用这一点所带来的便利性。所有的表索引只包含一个键值,其中包括两部分内容。每个索引都创建于该表所属的目录之下,一个名为index的子目录中,这是该键元组的第一部分内容。第二个部分是一个组合,首先是该索引所对应的各个列的值,之后则是指定这一行所必须的列的值。
举例来说,我们可以为这张表的c列创建一个索引。
CREATE INDEX index_on_c ON schema_a.table1(c) STORAGE_FORMAT tuple;
接下来使用Python读取这个索引的内容,我们需要在Python解释器中加入以下内容:
directory = fdb.directory.open(db, ('sql', 'data', 'table', 'schema_a', 'table1', 'index_on_c'))
for key, value in db[directory.range()]: print fdb.tuple.unpack(key), ' --> ', fdb.tuple.unpack(value)
这段代码会输入类似于下图中的内容,显示了键的两个组成部分:即该索引所在的目录的字节值,以及创建索引的c列的值加上主键的值。最后一个部分将被索引的值链接到某个特定的行,而该索引键所对应的值为空。
(20127, u'hello', 1) --> ()
(20127, u'world', 2) --> ()
如果要对SQL层的行为进行更多的控制调整,可以使用以下三种存储格式:一是之前描述过的元组格式,一是列键格式,以及protobuf格式。列健格式会为某一行的每个列值创建一个独立的键-值对。而protobuf存储格式为会每一行创建一个protobuf消息。
接下来还需要对元数据进行存储与组织。SQL层使用protobuf消息与基于SQL的数据的结构进行通信。这个结构是由schema、组、表、列、索引与外键等对象共同组成的。
SQL与NoSQL的混合模式
如果在应用程序级别使用只读的键-值API,那么SQL层就能够在客户端进行直接访问。可以通过键-值API直接访问数据,但如果增加或改写了SQL层所用的关键数据,那就很可能破坏系统的运行。这里例举一些可能会产生的问题:缺乏对索引的维护、缺乏应有的限定,以及忽略了对数据及元数据的版本维护。而这种方式的好处,哪怕是在进行数据读取时也并不明显,因为SQL层本身的额外开销就非常小。因此总的来说,性能的开销主要取决于网络延迟。
结论
SQL与NoSQL的结合使用能够相互利用两者的优点。FoundationDB的键-值存储系统为SQL层带来的好处包括可伸缩性、容错性及全局ACID的事务属性。你的应用程序同样也能从中受益,因此赶紧尝试一下吧!对应那些要执行大量的小批数据读取及写入的应用程序来说,FoundationDB提供了一个高伸缩并且安全的解决方案,并且可以任意使用SQL或NoSQL。
程序员日志
打造面向资深开发者的第一新媒体
深度丨有料丨有意思
【欢迎投稿】
以上是关于如何高效地将SQL数据映射到NoSQL存储系统中的主要内容,如果未能解决你的问题,请参考以下文章