持续可用与CAP理论 - 一个数据库系统开发者的观点
Posted 技术琐话
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了持续可用与CAP理论 - 一个数据库系统开发者的观点相关的知识,希望对你有一定的参考价值。
本文作者为蚂蚁金服OceanBase研究员日照,发表于2015年。
持续可用
本文主要针对金融数据库,认为金融数据库的持续可用包含两点:一个是强一致性;另外一个是高可用性。
数据库系统必须是强一致性的系统,这是因为数据库系统有事务ACID的基本要求,而弱一致系统无法做到。业内也有一些流行的NOSQL系统,例如各种类Dynamo系统,如开源的Cassandra,对同一个最小数据单位(同一行数据)允许多台服务器同时写入,虽然采用NWR机制处理冲突,但是由于不可能解决多台服务器之间的时序问题,而只能支持弱一致语义。弱一致语义的问题很多,例如无法支持复杂功能,无法构建严谨的测试体系,无法应用到核心场景。虽然弱一致性系统也有一定的应用场景,但本文认为其不符合核心业务持续可用的要求,不予讨论。
高可用性可以有很多种解释,实践中最常见的解释为:在一台服务器,一个交换机,一个机房,或者一个地区整体故障后,系统能够在多长时间内恢复服务。当然,这里的恢复服务是以保证强一致性作为前提条件的。如果能够在秒级(10秒左右)恢复服务,本文认为这个系统是高可用的,绝大部分应用系统都能够容忍硬件故障导致的秒级不可用。
CAP理论
CAP理论网上传了很多版本,大致的意思是:一致性,可用性和分区可容忍性三者只能取其二,不可兼得。由于分区可容忍性是不可选择的,因此,系统设计时只能在一致性和可用性之间权衡。这就带来了一个很悲观的结论:持续可用无法实现。然而,事实是这样吗?
首先,我们回到CAP理论的原始定义:
C(Consistency):A read is guaranteed to return the most recent writefor a given client
A(Availability):Anon-failing node will return a reasonable response within areasonable amount of time (no error or timeout)
P(PartitionTolerance):The system will continue to function when networkpartitions occur.
CAP理论的证明也比较直观,如下:
左图中,假设有两个节点N1和N2,N1和N2之间发生了网络分区(P),N1写入新值y,N2一直是老值x,为了保证一致性(C),读取N2总是返回失败,违反了可用性(A)要求:任何一个没有发生故障的节点必须在有限时间内返回结果,不允许为Error或者Timeout,系统只能保证CP。
右图中,从另外一个角度看,假设总是要保证可用性(A),那么,读到N2中的老值x,由于x和最新写入的y不同,违反了一致性(C)的要求,系统只能保证AP。
CAP理论本身毋庸置疑,证明可以参考Gilbert和Lynch合著的论文。
CAP中的A与高可用的HA
请读者会到CAP理论中关于A的定义:CAP中的A要求任何一个没有发生故障的节点必须在有限的时间内返回结果。然而,如果系统能够做到当某个节点发生网络分区后,将它从系统中剔除,由其它节点继续提供服务。虽然没有满足CAP中A的要求,但是,只要恢复时间足够快,也符合高可用的要求。而高可用才是系统设计的本质需求,CAP中的A只是个理论上的需求。
CAP理论的作者Eric Brewer后来确实也写过一篇文章来说明这个问题:<
Paxos与持续可用
Paxos是图灵奖获得者Lamport的经典之作,第一个版本的论文叫做:<
八卦完了Paxos,下面进入正题。Lamport和JimGray分别是分布式系统和数据库领域的代表任务,同属微软研究院,不过也是共事多年才坐在一起聊两个领域的问题。高可用是分布式系统的长项,为了实现高可用,首先必须至少写三份数据(一主两备)。这是因为,如果只写两份数据,当一份数据出现故障的时候,另外一份数据永远无法证明自己是对,也无法证明自己是错。这就是选举的价值,类Paxos选举协议允许在超过半数(Majority)节点正常的情况下提供服务。因此,当某台服务器,某个交换机,某个IDC甚至某个地区整体故障的时候,只要不超过整个系统的半数,系统都能够很快从错误中恢复过来,而且完全自动,无需人工干预。
强一致性是数据库的长项,做法就是强同步,Oracle,mysql5.7,国内的MySQL定制版本,例如阿里、网易的MySQL版本都支持强一致性。强同步的问题在于性能损耗,例如传统数据库的执行模型(非线程池模型)一般为一个连接对应一个工作线程/进程,采用强同步模式后事务的延时必然延长,从而导致工作线程/进程数增多,高并发情况下日志线程唤醒工作线程导致的上下文切换开销也非常大。另外,为了实现高可用,必须同步至少两个备库,使得情况进一步恶化。
采用Paxos协议的持续可用系统有两种常见的部署方式:
第一种部署方式比较简单,也最为常见。有一个全局Paxos服务,例如Zookeeper,它和其它机器之间保持租约。Master和两个Slave之间保持强同步,事务至少要写入到Master和其中一个Slave才可以返回成功。同一时刻对于同一份数据只有一个Master,全局Paxos服务负责选举,当Master出现故障时,选举日志号最大的Slave接替原来的Master继续提供服务。
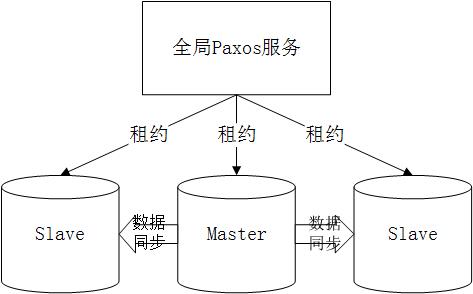
第二种部署方式比较纯粹,只出现在少量的分布式数据库中,例如Google Spanner,OceanBase1.0。Leader(相当于Master)和Follower(相当于Slave)之间直接采用Paxos协议进行数据同步和选举,相比第一种方案,这种方式实现复杂度要高很多,换来的好处是宕机恢复时间更短,系统更优雅。

共享存储与硬件解决方案
数据库领域经常采用共享存储来解决强一致性问题,主库将redo日志持久化到共享存储,如果主库故障,假设共享存储是持续可用的,备库可以从共享存储中读取日志恢复系统。共享存储与share-nothing架构的强同步有何区别呢?共享存储模式下只需要部署一个主库和一个备库,而share-nothing架构下强同步至少需要一个主库加两个备库。为什么呢?假设share-nothing架构只部署了一个主库和一个备库,只要任何一台机器,即使是备库宕机,为了保证强一致性,整个系统都无法提供服务。显然,这样的系统在互联网业务中几乎没有应用场景。
共享存储本质上是硬件解决方案,相比Paxos解决方案,优势是简单成熟,在商用数据库中广泛使用。问题在于成本高,且依赖硬件本身高可靠和高性能,也无法跨IDC部署,只能容忍单台服务器故障,无法容忍单个IDC故障。
强同步性能
数据库的性能分为两个方面:
单个事务的延时:由于多了一次同步操作,单个事务提交的延时加长了。设计系统时能够做的事情是将同步两个备库和主库写磁盘这三个操作完全并行起来,使得增加的额外延时只是三个操作的最大值,而不是三个操作之和。
系统的吞吐量:本质上看,强同步是否影响吞吐量取决于主备之间的网络带宽是否成为瓶颈。在采用万兆网卡或者两块千兆网卡的情况下,吞吐量基本没有影响。
理想的系统应该是一个全异步的系统,避免强同步占用线程/进程等执行资源,且不应该带来额外的上下文切换。日志同步的优化有一些关键点,例如:组提交(GroupCommit),减少日志缓冲区的锁冲突,异步化,避免不必要的上下文切换,数据库提前解行锁避免热点。具体可以参考论文:<
与性能相关联的一个问题是成本。前面已经提到,基于Paxos的持续可用方案至少需要一主两备,如果数据总是有三份,确实比较浪费。一个做到极致的系统应该能够只需要两个副本,第三个副本只存储redo日志即可。
引入选举的难点
假设在关系数据库的基础上引入全局Paxos服务,是否能够解决高可用问题呢?理论上确实是可以的,不过实施起来难度也不小。这是因为,即使是Zookeeper这样成熟的选举服务,使用过程中总是会遇到各种各样的问题,如果期望应用到核心业务,需要对Zookeeper系统完全的掌控力。也就是说,假设Zookeeper这样的服务出现问题,需要能够FixBug,而不是简单重启解决。另外,也需要做一套模拟各种异常的测试系统,确保不会在异常的情况下出现一些严重的问题,例如Zookeeper选出双主导致数据不一致。总而言之,做一个持续可用的选举服务并不是简单地使用开源软件,这是一个全局服务,要么不做,要么就深入下去做到完全掌控。
跨机房问题
跨机房问题分为两类:同城以及异地。前面已经提到,无论如何实现,强同步方案中单个事务至少增加一次网络同步延时。对于同城场景,如果网络环境比较好,例如公司的数据库服务有专用的光纤或者带宽比较高,那么,增加的延时在1~2ms(光折射传播的时间+交换机处理时间),业务是完全可以接受的。因此,可以做到同城持续可用,单个IDC故障时,能够在保证强一致的前提下很快恢复服务。
对于异地场景,由于网络延时较大,例如100ms左右,业务往往不可接受。因此,无法做到跨地域持续可用,整个地区故障时,要么牺牲一致性,要么牺牲可用性,如果选择可用性时可能会丢失最后几秒内的数据。当然,实际上业务上往往会组合使用各种柔性解决方案,例如涉及到钱的业务停服务,其它业务容忍极端情况下的数据丢失;或者在外部系统中记录一些信息,例如记录哪些用户的数据不一致,出现问题是禁止这些用户的写服务,其它用户正常提供服务;或者DBA采用各种办法补数据,等等。
小结
总而言之,在金融数据库中,由于强一致性是必选项,因此,要做到持续可用比较困难,但也并不是不可能,CAP和持续可用并不矛盾。成熟的商业数据库都是基于共享存储的,不过基于Paxos的持续可用方案开始越来越多地应用到核心场景,例如GoogleSpanner,Microsoft SQL Server云版本,Amazon DynamoDB,而AliababaOceanBase也在金融核心场景得到了验证。同时,笔者认为,采用Paxos协议,虽然工程难度很高,但是,只要在实现上做到极致,在同城的情况下,可以容忍单个IDC故障,且性能损耗非常小;而在异地的场景,考虑到光速不可突破,往往由业务在一致性和可用性之间权衡。越来越多的云数据库将会采用Paxos来实现持续可用。
往期推荐:
……
技术琐话
以分布式设计、架构、体系思想为基础,兼论研发相关的点点滴滴,不限于代码、质量体系和研发管理。
以上是关于持续可用与CAP理论 - 一个数据库系统开发者的观点的主要内容,如果未能解决你的问题,请参考以下文章