使用Spark+Cassandra打造高性能数据分析平台
Posted 数盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Spark+Cassandra打造高性能数据分析平台相关的知识,希望对你有一定的参考价值。
【数盟倡导”数据创造价值“,致力于打造最卓越的数据科学交流平台,为企业、个人提供最卓越的服务】
摘要:Spark,强大的迭代计算框架,在内存数据计算上无可匹敌。Cassandra,优异的列式存储NoSQL,在写入操作上难逢敌手。自本期《问底》,许鹏将结合实际实践,带大家打造一个由Spark和Cassandra组成的大数据分析平台。
【导读】笔者(许鹏)看Spark源码的时间不长,记笔记的初衷只是为了不至于日后遗忘。在源码阅读的过程中秉持着一种非常简单的思维模式,就是努力去寻找一条贯穿全局的主线索。在笔者看来,Spark中的线索就是如果让数据的处理在分布式计算环境下是高效,并且可靠的。
在对Spark内部实现有了一定了解之后,当然希望将其应用到实际的工程实践中,这时候会面临许多新的挑战,比如选取哪个作为数据仓库,是HBase、MongoDB还是Cassandra。即便一旦选定之后,在实践过程还会遇到许多意想不到的问题。
要想快速的解决开发及上线过程中遇到的系列问题,还需要具备相当深度的Linux知识,恰巧之前工作中使用Linux的经验在大数据领域中还可以充分使用。
笔者不才,就遇到的一些问题,整理出来与诸君共同分享。
1. Cassandra
NoSQL数据库的选择之痛,目前市面上有近150多种NoSQL数据库,如何在这么庞杂的队伍中选中适合业务场景的佼佼者,实非易事。
好的是经过大量的筛选,大家比较肯定的几款NoSQL数据库分别是HBase、MongoDB和Cassandra。
Cassandra在哪些方面吸引住了大量的开发人员呢?下面仅做一个粗略的分析。
1.1 高可靠性
Cassandra采用gossip作为集群中结点的通信协议,该协议整个集群中的节点都处于同等地位,没有主从之分,这就使得任一节点的退出都不会导致整个集群失效。
Cassandra和HBase都是借鉴了Google BigTable的思想来构建自己的系统,但Cassandra另一重要的创新就是将原本存在于文件共享架构的p2p(peer to peer)引入了NoSQL。
P2P的一大特点就是去中心化,集群中的所有节点享有同等地位,这极大避免了单个节点退出而使整个集群不能工作的可能。
与之形成对比的是HBase采用了Master/Slave的方式,这就存在单点失效的可能。
1.2 高可扩性
随着时间的推移,集群中原有的规模不足以存储新增加的数据,此时进行系统扩容。Cassandra级联可扩,非常容易实现添加新的节点到已有集群,操作简单。
1.3 最终一致性
分布式存储系统都要面临CAP定律问题,任何一个分布式存储系统不可能同时满足一致性(consistency),可用性(availability)和分区容错性(partition tolerance)。
Cassandra是优先保证AP,即可用性和分区容错性。
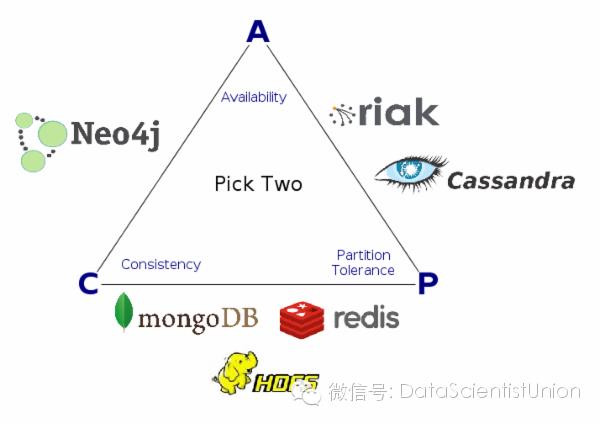
Cassandra为写操作和读操作提供了不同级别的一致性选择,用户可以根据具体的应用场景来选择不同的一致性级别。
1.4 高效写操作
写入操作非常高效,这对于实时数据非常大的应用场景,Cassandra的这一特性无疑极具优势。
数据读取方面则要视情况而定:
如果是单个读取即指定了键值,会很快的返回查询结果。
如果是范围查询,由于查询的目标可能存储在多个节点上,这就需要对多个节点进行查询,所以返回速度会很慢
读取全表数据,非常低效。
1.5 结构化存储
Cassandra是一个面向列的数据库,对那些从RDBMS方面转过来的开发人员来说,其学习曲线相对平缓。
Cassandra同时提供了较为友好CQL语言,与SQL语句相似度很高。
1.6 维护简单
从系统维护的角度来说,由于Cassandra的对等系统架构,使其维护操作简单易行。如添加节点,删除节点,甚至于添加新的数据中心,操作步骤都非常的简单明了。
参考资料
1.http://cassandra.apache.org
2.http://www.datastax.com/doc
3.http://planetcassandra.org/documentation/
2. Cassandra数据模型
2.1 单表查询
2.1.1 单表主键查询
在建立个人信息数据库的时候,以个人身份证id为主键,查询的时候也只以身份证为关键字进行查询,则表可以设计成为:
create table person ( userid text primary key, fname text, lname text, age int, gender int);
Primary key中的第一个列名是作为Partition key。也就是说根据针对partition key的hash结果决定将记录存储在哪一个partition中,如果不湊巧的情况下单一主键导致所有的hash结果全部落在同一分区,则会导致该分区数据被撑满。
解决这一问题的办法是通过组合分区键(compsoite key)来使得数据尽可能的均匀分布到各个节点上。
举例来说,可能将(userid,fname)设置为复合主键。那么相应的表创建语句可以写成
create table person (userid text,fname text,lname text,gender int,age int,primary key((userid,fname),lname);) with clustering order by (lname desc);
稍微解释一下primary key((userid, fname),lname)的含义:
其中(userid,fname)称为组合分区键(composite partition key)
lname是聚集列(clustering column)
((userid,fname),lname)一起称为复合主键(composite primary key)
2.1.2 单表非主键查询
如果要查询表person中具有相同的first name的人员,那么就必须针对fname创建相应的索引,否则查询速度会非常缓慢。
Create index on person(fname);
Cassandra目前只能对表中的某一列建立索引,不允许对多列建立联合索引。
2.2 多表关联查询
Cassandra并不支持关联查询,也不支持分组和聚合操作。
那是不是就说明Cassandra只是看上去很美其实根本无法解决实际问题呢?答案显然是No,只要你不坚持用RDBMS的思路来解决问题就是了。
比如我们有两张表,一张表(Departmentt)记录了公司部门信息,另一张表(employee)记录了公司员工信息。显然每一个员工必定有归属的部门,如果想知道每一个部门拥有的所有员工。如果是用RDBMS的话,SQL语句可以写成:
select * from employee e , department d where e.depId = d.depId;要用Cassandra来达到同样的效果,就必须在employee表和department表之外,再创建一张额外的表(dept_empl)来记录每一个部门拥有的员工信息。
Create table dept_empl (deptId text,
看到这里想必你已经明白了,在Cassandra中通过数据冗余来实现高效的查询效果。将关联查询转换为单一的表操作。
2.3 分组和聚合
在RDBMS中常见的group by和max、min在Cassandra中是不存在的。
如果想将所有人员信息按照姓进行分组操作的话,那该如何创建数据模型呢?
Create table fname_person (fname text,userId text,primary key(fname)); 2.4 子查询
Cassandra不支持子查询,下图展示了一个在mysql中的子查询例子:
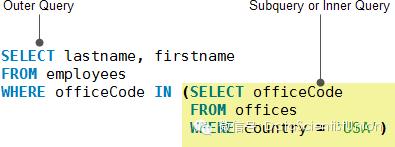
要用Cassandra来实现,必须通过添加额外的表来存储冗余信息。
Create table office_empl (officeCode text,country text,lastname text,firstname,primary key(officeCode,country));create index on office_empl(country);
2.5 小结
总的来说,在建立Cassandra数据模型的时候,要求对数据的读取需求进可能的清晰,然后利用反范式的设计方式来实现快速的读取,原则就是以空间来换取时间。
3. 利用Spark强化Cassandra的实时分析功能
在Cassandra数据模型一节中,讲述了通过数据冗余和反范式设计来达到快速高效的查询效果。
但如果对存储于cassandra数据要做更为复杂的实时性分析处理的话,使用原有的技巧无法实现目标,那么可以通过与Spark相结合,利用Spark这样一个快速高效的分析平台来实现复杂的数据分析功能。
3.1 整体架构
利用spark-cassandra-connector连接Cassandra,读取存储在Cassandra中的数据,然后就可以使用Spark RDD中的支持API来对数据进行各种操作。
3.2 Spark-cassandra-connector
在Spark中利用datastax提供的spark-cassandra-connector来连接Cassandra数据库是最为简单的一种方式。
目前spark-cassandra-connector 1.1.0-alpha3支持的Spark和Cassandra版本如下
Spark 1.1
Cassandra 2.x
如果是用sbt来管理scala程序的话,只需要在build.sbt中加入如下内容即可由sbt自动下载所需要的spark-cassandra-connector驱动
datastax.spark" %% "spark-cassandra-connector" % "1.1.0-alpha3" withSources() withJavadoc()
http://mvnrepository.com/artifact/com.datastax.spark
3.2.1 driver的配置
这些参数即可以硬性的写死在程序中,如
[cpp] view plaincopy
val conf = new SparkConf()
conf.set(“spark.cassandra.connection.host”, cassandra_server_addr)
conf.set(“spark.cassandra.auth.username”, “cassandra”)
conf.set(“spark.cassandra.auth.password”,”cassandra”)
硬编码的方式是发动不灵活,其实这些配置参数完全可以写在spark-defaults.conf中,那么上述的配置可以写成
spark.cassandra.connection.host 192.168.6.201spark.cassandra.auth.username cassandraspark.cassandra.auth.password cassandra
3.2.2 依赖包的版本问题
sbt会自动下载spark-cassandra-connector所依赖的库文件,这在程序编译阶段不会呈现出任何问题。
但在执行阶段问题就会体现出来,即程序除了spark-cassandra-connector之外还要依赖哪些文件呢,这个就需要重新回到maven版本库中去看spark-cassandra-connector的依赖了。
总体上来说spark-cassandra-connector严重依赖于这几个库
cassandra-clientutil
cassandra-driver-core
cassandra-all
另外一种解决的办法就是查看$HOME/.ivy2目录下这些库的最新版本是多少
find ~/.ivy2 -name “cassandra*.jar”
取最大的版本号即可,就alpha3而言,其所依赖的库及其版本如下
com.datastax.spark/spark-cassandra-connector_2.10/jars/spark-cassandra-connector_2.10-1.1.0-alpha3.jarorg.apache.cassandra/cassandra-thrift/jars/cassandra-thrift-2.1.0.jarorg.apache.thrift/libthrift/jars/libthrift-0.9.1.jarorg.apache.cassandra/cassandra-clientutil/jars/cassandra-clientutil-2.1.0.jarcom.datastax.cassandra/cassandra-driver-core/jars/cassandra-driver-core-2.1.0.jario.netty/netty/bundles/netty-3.9.0.Final.jarcom.codahale.metrics/metrics-core/bundles/metrics-core-3.0.2.jarorg.slf4j/slf4j-api/jars/slf4j-api-1.7.7.jarorg.apache.commons/commons-lang3/jars/commons-lang3-3.3.2.jarorg.joda/joda-convert/jars/joda-convert-1.2.jarjoda-time/joda-time/jars/joda-time-2.3.jarorg.apache.cassandra/cassandra-all/jars/cassandra-all-2.1.0.jarorg.slf4j/slf4j-log4j12/jars/slf4j-log4j12-1.7.2.jar
3.3 Spark的配置
程序顺利通过编译之后,准备在Spark上进行测试,那么需要做如下配置
3.3.1 spark-default.env
Spark-defaults.conf的作用范围要搞清楚,编辑driver所在机器上的spark-defaults.conf,该文件会影响到driver所提交运行的application,及专门为该application提供计算资源的executor的启动参数
只需要在driver所在的机器上编辑该文件,不需要在worker或master所运行的机器上编辑该文件
举个实际的例子
spark.executor.extraJavaOptions -XX:MaxPermSize=896mspark.executor.memory 5gspark.serializer org.apache.spark.serializer.KryoSerializerspark.cores.max 32spark.shuffle.manager SORTspark.driver.memory 2g
上述配置表示为该application提供计算资源的executor启动时, heap memory需要有5g。
这里需要引起注意的是,如果worker在加入cluster的时候,申明自己所在的机器只有4g内存,那么为上述的application分配executor是,该worker不能提供任何资源,因为4g<5g,无法满足最低的资源需求。
3.3.2 spark-env.sh
配置举例如下
export SPARK_MASTER_IP=127.0.0.1export SPARK_LOCAL_IP=127.0.0.1
3.3.3 启动Spark集群
第一步启动master
$SPARK_HOME/sbin/start-master.sh
第二步启动worker
$SPARK_HOME/bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
如果想在一台机器上运行多个worker(主要是用于测试目的),那么在启动第二个及后面的worker时需要指定—webui-port的内容,否则会报端口已经被占用的错误,启动第二个用的是8083,第三个就用8084,依此类推。
$SPARK_HOME/bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077 –webui-port 8083
这种启动worker的方式只是为了测试是启动方便,正规的方式是用$SPARK_HOME/sbin/start-slaves.sh来启动多个worker,由于涉及到ssh的配置,比较麻烦,我这是图简单的办法。
用$SPARK_HOME/sbin/start-slave.sh来启动worker时有一个默认的前提,即在每台机器上$SPARK_HOME必须在同一个目录。
注意:
使用相同的用户名和用户组来启动Master和Worker,否则Executor在启动后会报连接无法建立的错误。
我在实际的使用当中,遇到”no route to host”的错误信息,起初还是认为网络没有配置好,后来网络原因排查之后,忽然意识到有可能使用了不同的用户名和用户组,使用相同的用户名/用户组之后,问题消失。
3.3.4 Spark-submit
spark集群运行正常之后,接下来的问题就是提交application到集群运行了。
Spark-submit用于Spark application的提交和运行,在使用这个指令的时候最大的困惑就是如何指定应用所需要的依赖包。
首先查看一下spark-submit的帮助文件
$SPARK_HOME/bin/submit --help
有几个选项可以用来指定所依赖的库,分别为
--driver-class-path driver所依赖的包,多个包之间用冒号(:)分割
--jars driver和executor都需要的包,多个包之间用逗号(,)分割
为了简单起见,就通过—jars来指定依赖,运行指令如下
$SPARK_HOME/bin/spark-submit –class 应用程序的类名 \--master spark://master:7077 \--jars 依赖的库文件 \spark应用程序的jar包
3.3.5 RDD函数使用的一些问题
collect
如果数据集特别大,不要贸然使用collect,因为collect会将计算结果统统的收集返回到driver节点,这样非常容易导致driver结点内存不足,程序退出
repartition
在所能提供的core数目不变的前提下,数据集的分区数目越大,意味着计算一轮所花的时间越多,因为中间的通讯成本较大,而数据集的分区越小,通信开销小而导致计算所花的时间越短,但数据分区越小意味着内存压力越大。
假设为每个spark application提供的最大core数目是32,那么将partition number设置为core number的两到三倍会比较合适,即parition number为64~96。
/tmp目录问题
由于Spark在计算的时候会将中间结果存储到/tmp目录,而目前linux又都支持tmpfs,其实说白了就是将/tmp目录挂载到内存当中。
那么这里就存在一个问题,中间结果过多导致/tmp目录写满而出现如下错误
No Space Left on the device
解决办法就是针对tmp目录不启用tmpfs,修改/etc/fstab,如果是archlinux,仅修改/etc/fstab是不够的,还需要执行如下指令:
systemctl mask tmp.mount
3.4 Cassandra的配置优化
3.4.1 表结构设计
Cassandra表结构设计的一个重要原则是先搞清楚要对存储的数据做哪些操作,然后才开始设计表结构。如:
只对表进行添加,查询操作
对表需要进行添加,修改,查询
对表进行添加和修改操作
一般来说,针对Cassandra中某张具体的表进行“添加,修改,查询”并不是一个好的选择,这当中会涉及到效率及一致性等诸多问题。
Cassandra比较适合于添加,查询这种操作模式。在这种模式下,需要先搞清楚要做哪些查询然后再来定义表结构。
加深对Cassandra中primary key及其变种的理解有利于设计出高效查询的表结构。
create test ( k int, v int , primary key(k,v))
上述例子中primary key由(k,v)组成,其中k是partition key,而v是clustering columns,如果k相同,那么这些记录在物理存储上其实是存储在同一行中,即Cassandra中常会提及的wide rows.
有了这个基础之后,就可以进行范围查询了
select * from test where k = ? and v > ? and v < ?
当然也可以对k进行范围查询,不过要加token才行,但一般这样的范围查询结果并不是我们想到的
select * from test where token(k) > ? and token(k) < ?
Cassandra中针对二级索引是不支持范围查询的,一切的一切都在主键里打主意。
3.4.2 参数设置
Cassandra的配置参数项很多,对于新手来说主要集中于对这两个文件中配置项的理解。
cassandra.yaml Cassandra系统的运行参数
cassandra-env.sh JVM运行参数
在cassandra-env.sh中针对JVM的设置
JVM_OPTS="$JVM_OPTS -XX:+UseParNewGC" JVM_OPTS="$JVM_OPTS -XX:+UseConcMarkSweepGC" JVM_OPTS="$JVM_OPTS -XX:+CMSParallelRemarkEnabled"
JVM_OPTS="$JVM_OPTS -XX:SurvivorRatio=8" JVM_OPTS="$JVM_OPTS -XX:MaxTenuringThreshold=1"JVM_OPTS="$JVM_OPTS -XX:CMSInitiatingOccupancyFraction=80"JVM_OPTS="$JVM_OPTS -XX:+UseCMSInitiatingOccupancyOnly"JVM_OPTS="$JVM_OPTS -XX:+UseTLAB"JVM_OPTS="$JVM_OPTS -XX:ParallelCMSThreads=1"JVM_OPTS="$JVM_OPTS -XX:+CMSIncrementalMode"JVM_OPTS="$JVM_OPTS -XX:+CMSIncrementalPacing"JVM_OPTS="$JVM_OPTS -XX:CMSIncrementalDutyCycleMin=0"JVM_OPTS="$JVM_OPTS -XX:CMSIncrementalDutyCycle=10"
如果nodetool无法连接到Cassandra的话,在cassandra-env.sh中添加如下内容
JVM_OPTS="$JVM_OPTS -Djava.rmi.server.hostname=ipaddress_of_cassandra"
在cassandra.yaml中,注意memtable_total_space_in_mb的设置,不要将该值设的特别大。将其配置成为JVM HEAP的1/4会是一个比较好的选择。如果该值设置太大,会导致不停的FULL GC,那么在这种情况下Cassandra基本就不可用了。
3.4.3 nodetool使用
Cassandra在运行期间可以通过nodetool来看内部的一些运行情况。
如看一下读取的完成情况
nodetool -hcassandra_server_address tpstats
检查整个cluster的状态
nodetool -hcassandra_server_address status
检查数据库中每个表的数据有多少
nodetool -hcassandra_server_address cfstats
To Be Contunued……
from:http://www.csdn.net/article/2014-10-24/2822278-how-to-bulida-spark-and-cassandra-based-high-performance-data-pipeline
—————————————————
数盟网站:www.dataunion.org
数盟微博:@数盟社区
数盟微信:DataScientistUnion
数盟【大数据群】272089418
数盟【数据可视化群】 179287077
数盟【数据分析群】 174306879 ,110875722 ,321311420
—————————————————
更多精彩,点击可得~
以上是关于使用Spark+Cassandra打造高性能数据分析平台的主要内容,如果未能解决你的问题,请参考以下文章
问底许鹏:使用Spark+Cassandra打造高性能数据分析平台
使用Kafka+Spark+Cassandra构建实时处理引擎