如何使用OpenStack,Docker和Spark打造一个云服务
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用OpenStack,Docker和Spark打造一个云服务相关的知识,希望对你有一定的参考价值。
IBM中国研究院高级研究员陈冠诚主要从事Big Data on Cloud,大数据系统性能分析与优化方面的技术研发。负责和参与过SuperVessel超能云的大数据服务开发,Hadoop软硬件协同优化,MapReduce性能分析与调优工具,高性能FPGA加速器在大数据平台上应用等项目。在Supercomputing(SC),IEEE BigData等国际顶级会议和期刊上发表过多篇大数据数据处理技术相关的论文,并拥有八项大数据领域的技术专利。曾在《程序员》杂志分享过多篇分布式计算,大数据处理技术等方面的技术文章。以下为媒体针对陈冠诚的专访:问:首先请介绍下您自己,以及您在Spark 技术方面所做的工作。
陈冠诚:我是IBM中国研究院的高级研究员,大数据云方向的技术负责人。我们围绕Spark主要做两方面的事情:第一,在IBM研究院的SuperVessel公有云上开发和运维Spark as a Service大数据服务。第二,在OpenPOWER架构的服务器上做Spark的性能分析与优化。
问:您所在的企业是如何使用Spark 技术的?带来了哪些好处?
陈冠诚:Spark作为新一代的大数据处理引擎主要带来了两方面好处:
相比于MapReduce在性能上得到了很大提升。
在一个统一的平台上将批处理、SQL、流计算、图计算、机器学习算法等多种范式集中在一起,使混合计算变得更加的容易。
问:您认为Spark 技术最适用于哪些应用场景?
陈冠诚:大规模机器学习、图计算、SQL等类型数据分析业务是非常适合使用Spark的。当然,在企业的技术选型过程中,并不是说因为Spark很火就一定要使用它。例如还有很多公司在用Impala做数据分析,一些公司在用Storm和Samaza做流计算,具体的技术选型应该根据自己的业务场景,人员技能等多方面因素来做综合考量。
问:企业在应用Spark 技术时,需要做哪些改变吗?企业如果想快速应用Spark 应该如何去做?
陈冠诚:企业想要拥抱Spark技术,首先需要技术人员改变。是否有给力的Spark人才会是企业能否成功应用Spark最重要的因素。多参与Spark社区的讨论,参加Spark Meetup,给upstrEAM贡献代码都是很好的切入方式。如果个人开发者想快速上手Spark,可以考虑使用SuperVessel免费的Spark公有云服务,它能快速创建一个Spark集群供大家使用。
问:您所在的企业在应用Spark 技术时遇到了哪些问题?是如何解决的?
陈冠诚:我们在对Spark进行性能调优时遇到很多问题。例如JVM GC的性能瓶颈、序列化反序列化的开销、多进程好还是多线程好等等。在遇到这些问题的时候,最好的方法是做好Profiling,准确找到性能瓶颈,再去调整相关的参数去优化这些性能瓶颈。
另一方面,我们发现如果将Spark部署在云环境里(例如OpenStack管理的Docker Container)时,它的性能特征和在物理机上部署又会有很大的不同,目前我们还在继续这方面的工作,希望以后能有机会跟大家继续分享。
问:作为当前流行的大数据处理技术,您认为Spark 还有哪些方面需要改进?
陈冠诚:在与OpenStack这样的云操作系统的集成上,Spark还是有很多工作可以做的。例如与Docker Container更好的集成,对Swift对象存储的性能优化等等。
问:您在本次演讲中将分享哪些话题?
陈冠诚:我将分享的话题是“基于OpenStack、Docker和Spark打造SuperVessel大数据公有云”:
随着Spark在2014年的蓬勃发展,Spark as a Service大数据服务正成为OpenStack生态系统中的新热点。另一方面,Docker Container因为在提升云的资源利用率和生产效率方面的优势而备受瞩目。在IBM中国研究院为高校和技术爱好者打造的SuperVessel公有云中,我们使用OpenStack、Docker和Spark三项开源技术,在OpenPOWER服务器上打造了一个大数据公有云服务。本次演讲我们会向大家介绍如何一步一步使用Spark、Docker和OpenStack打造一个大数据公有云,并分享我们在开发过程中遇到的问题和经验教训。
问:哪些听众最应该了解这些话题?您所分享的主题可以帮助听众解决哪些问题?
陈冠诚:对如何构造一个大数据云感兴趣的同学应该会对这个话题感兴趣,开发SuperVessel的Spark as a Service服务过程中我们所做的技术选型、架构设计以及解决的问题应该能对大家有所帮助 参考技术A 哪个地区 参考技术B 从一项颠覆性的技术成果转化并衍生出一整套社区体系,Docker在发展速度上打破了一个又一个历史纪录。然而,Docker项目在采纳与普及方面表现出惊人态势的同时,也给我们带来了一系列疑问与困惑。在今天的文章中,我希望将注意力集中在朋友们最为关注的评论议题身上。随着Docker项目在人气方面的持续飙升,很快刚刚接触这一新生事物的读者在实践过程中不禁产生了这样的疑问:如果已经决定使用Docker,是否还有必要同时使用OpenStack?在给出自己的观点之前,我打算首先就背景信息入手为各位进行讲解,从而更为透彻地认清这个命题背后所隐藏的理论基础。背景信息从最为简单的构成形式出发,Docker实际上旨在提供一套能够在共享式基础设施之上对软件工作负载进行管理的容器环境,但同时又确保不同负载之间彼此隔离且互不影响。以KVM为代表的虚拟机系统所做的工作也差不多:创建一套完整的操作系统堆栈,通过虚拟机管理程序将与该系统相关的设备囊括进来。然而与虚拟机解决方案的区别在于,Docker在很大程度上依赖于Linux操作系统所内置的一项功能——名为LXC(即Linux容器)。LXC利用内置于操作系统当中的各项功能将不同进程的内存进行划分,甚至能够在一定程度上拆分CPU与网络资源。Docker镜像不需要像一套全新操作系统那样进行完整的引导过程,这样一来软件包的体积就能得到大幅压缩、应用程序运行在共享式计算资源之上时也将具备更为显著的轻量化优势。除此之外,Docker还允许工作负载直接访问设备驱动程序、从而带来远超过虚拟机管理程序方案的I/O运行速度。在这种情况下,我们得以直接在裸机设备上使用Docker,而这就带来了前面提到的核心问题:如果已经使用了Docker,我们还有必要同时使用OpenStack等云方案吗?前面的结论绝非信口开河,BodenRussell最近针对Docker与KVM等虚拟机管理程序在性能表现上的差异进行了基准测试,并在DockerCon大会上公布了测试结果。本次基准测试提供相当详尽的具体数据,而且如预期一样,测试结果显示引导KVM虚拟机管理程序与引导Docker容器之间存在着显著的时间消耗差异。本次测试同时表明,二者之间在内在与CPU利用率方面同样存在着巨大区别,具体情况如下图所示。红色线条为KVM,蓝色线条为Docker。这种在性能表现上的显著区别代表着两套目的相近的解决方案在资源密度与整体利用率方面大相径庭。而这样的差异也将直接体现在运行特定工作负载所需要的资源总量上,并最终反映到实际使用成本当中。结论整理·上述结论并不单纯指向OpenStack,但却适用于OpenStack以及其它与之类似的云基础设施解决方案。在我看来,之所以问题的矛头往往最终会被指向OpenStack,是因为OpenStack项目事实上已经在私有云环境领域具备相当高的人气,同时也是目前我们惟一会考虑作为Docker替代方案的技术成果。·问题的核心不在于OpenStack,而在于虚拟机管理程序!很多性能基准测试都将Docker与KVM放在了天秤的两端,但却很少将OpenStack牵涉于其中。事实上,前面提到的这次专项基准测试同时将OpenStack运行在KVM镜像与Docker容器环境之下,结果显示这两类技术成果能够带来理想的协作效果。考虑到这样的情况,当我们选择将OpenStack运行在基于Docker的Nova堆栈当中时——正如OpenStack说明文档提供的下图所示——那些资源利用率参数将变得无关紧要。·在这种情况下,云基础设施能够在容器或者虚拟机管理程序当中提供一套完整的数据中心管理解决方案,而这仅仅属于庞大系统整体当中的组成部分之一。以OpenStack为代表的云基础设施方案当中包含多租户安全性与隔离、管理与监控、存储及网络外加其它多种功能设置。任何云/数据中心管理体系都不能脱离这些服务而独立存在,但对于Docker或者是KVM基础环境却不会做出过多要求。·就目前来讲,Docker还不算是一套功能全面的虚拟化环境,在安全性方面存在多种严重局限,缺乏对Windows系统的支持能力,而且因此暂时无法作为一套真正可行的KVM备用方案。尽管正在持续进行当中的后续开发工作将逐步弥合这些差距,但抱持着相对保守的心态,这些问题的解决恐怕也同时意味着容器技术将在性能表现方面有所妥协。·另外需要注意的是,原始虚拟机管理程序与经过容器化的实际应用程序性能同样存在着巨大差异,而且下面这幅来自基准测试的图表清楚地说明了这一点。目前可能合理的解释在于,应用程序通常会利用缓存技术来降低I/O资源开销,而这大大影响了测试结果对真实环境中运行状态的准确反映。·如果我们将Docker容器打包在KVM镜像当中,那么二者之间的差异将变得可以忽略不计。这套架构通常利用虚拟机管理程序负责对云计算资源的控制,同时利用Heat、Cloudify或者Kubernetes等流程层在虚拟机资源的容纳范围之内进行容器管理。总结由此我得出了这样的结论:要想正确地看待OpenStack、KVM以及Docker三者之间的关系,正确的出发点是将其视为一整套辅助堆栈——其中OpenStack扮演整体数据中心管理方案的角色,KVM作为多租户计算资源管理工具,而Docker容器则负责与应用部署包相关的工作。在这样的情况下,我们可以汇总出一套通用型解决模式,其中Docker分别充当以下几种角色:·Docker提供经过认证的软件包,并保证其能够与稳定不变的现有基础设施模型顺利协作。·Docker为微服务POD提供出色的容器化运行环境。·在OpenStack之上使用Docker,并将其作用与裸机环境等同的运行平台。前面说了这么多,我确实亲眼见证过不少经过精确定义的工作负载实例,对于它们来说是否使用云基础设施仅仅是种自由选项而非强制要求。举例来说,如果我出于DevOps的目的而考虑建立一套小型自动化开发与测试环境,那么我个人更倾向于在裸机环境上直接使用Docker机制。而虚拟机与容器这两类环境之间,流程层将成为一套绝佳的抽象对接工具。将流程框架与Docker共同使用的一大优势在于,我们能够根据实际需求、随时在OpenStack以及裸机环境之间进行切换。通过这种方式,我们将能够选择任意一种解决选项——只要其切实符合我们流程引擎对于目标环境的具体需要。OpenStackOrchestration(即Heat)在最新发布的Icehouse版本当中已经明确表示支持Docker环境。Cloudify作为一款基于TOSCA的开源流程框架,原本适用于OpenStack以及VMware、AWS乃至裸机等云环境,而最近也开始将Docker支持纳入自身。谷歌Kubernetes主要面向的是GCE协作目标,但我们也能够通过自定义来使其适应其它云或者运行环境。
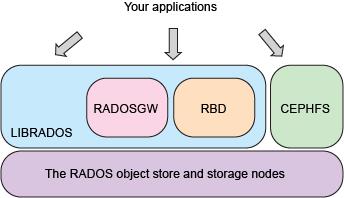
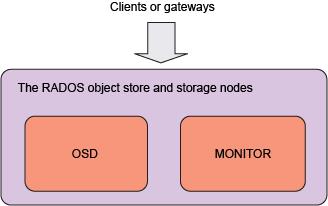
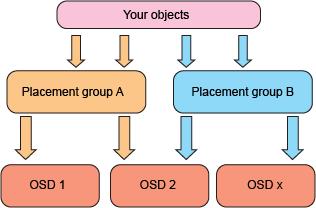
Openstack+KVM+Ceph+Docker 集成云计算中
对于以基础架构即服务形式部署和设计云计算产品的公司而言,数据复制和存储机制仍然是确保为客户提供完整性和服务连续性的实际前提条件。云计算提供了一种模型,其中数据的位置没有其他基础架构模型中那么重要(比如在一些模型中,公司直接拥有昂贵的存储硬件)。Ceph 是一个开源、统一、分布式的存储系统,提供了一种便捷方式来部署包含商用硬件、低成本且可大规模扩展的存储平台。了解如何创建一个 Ceph 集群(从单一点实现对象、块和文件存储)、Ceph 的算法和复制机制,以及如何将它与您的云数据架构和模型相集成。作者提出了一种将 Ceph 集群集成到 OpenStack 生态系统中的简单而又强大的方法。