基于Storm与Cassandra的实时计算与大数据实践
Posted 奥鹏研发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Storm与Cassandra的实时计算与大数据实践相关的知识,希望对你有一定的参考价值。
平时成绩(形成性考核成绩)一直是网络教学平台的根本性需求,由于其贯穿学生所有学习流程,规则和维度可弹性配置,对准确性、及时性要求比较迫切,而且数据量级十分巨大,是所有业务系统的一个性能瓶颈和业务难点。
引言
业务分析
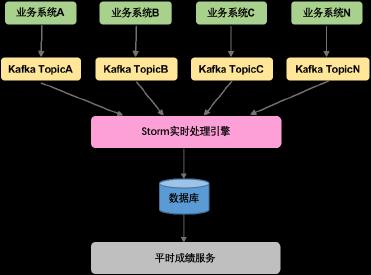
业务系统采集学生的学习行为数据传递给大数据,包括:课程签到、问答讨论、课件观看、学习时长,大数据负责数据的清洗和汇总,然后提交给平时成绩服务计算,得出学生的平时成绩。
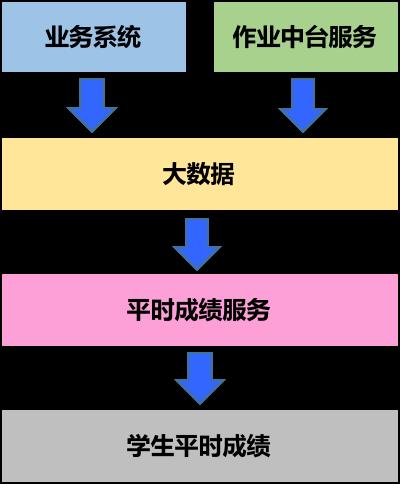
数据计算模型
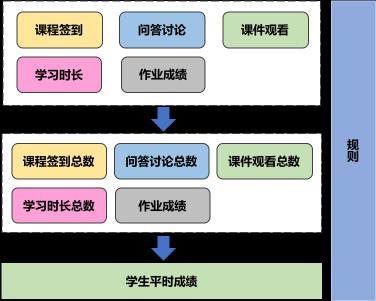
挑战
1. 数据规模大
平时成绩服务需要的数据贯穿于学生的所有学习过程,数据类型多,且部分数据采集频率高,所以数据规模较大,如果采用关系型数据库存储,数据量预估如下:
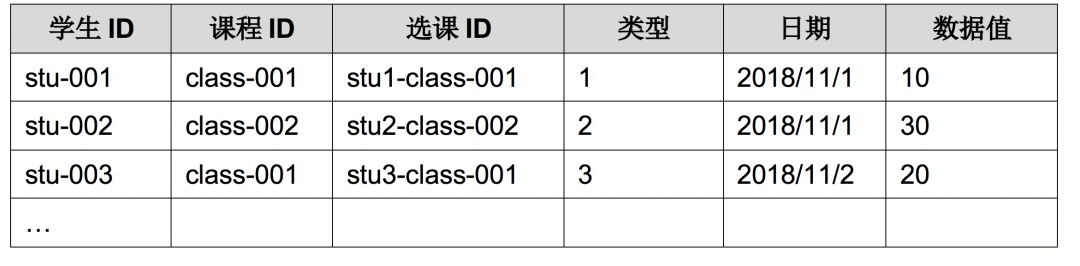
学生每日学习过程数据存储结构
年数据量保守预估:
学习行为(不含作业)数:100万学生*每人选10门课*4个行为*10天=4亿
作业数:100万学生*每人选10门课*3篇作业=3000万
年总数据量=4亿+3000万=4亿3000万,如果将来扩展学生的学习行为,数据规模会进一步扩大,如果采用关系型数据库存储如此规模的数据,则数据库势必会成为整个系统的瓶颈点,所以需要寻找好的存储方案解决该问题。
2. 实时性要求高
系统应在学生的每次学习过程结束后,结合其历史数据,快速计算出该学生最新的平时成绩,学生可通过课程学习空间及时了解到自己学习过程数据与平时成绩的变动情况。
技术选型
1. 实时处理引擎
目前比较流行的实时处理引擎有Storm、Flink和Spark。每个引擎都有其特点和应用场景,下表是对以上三个引擎的简单对比:
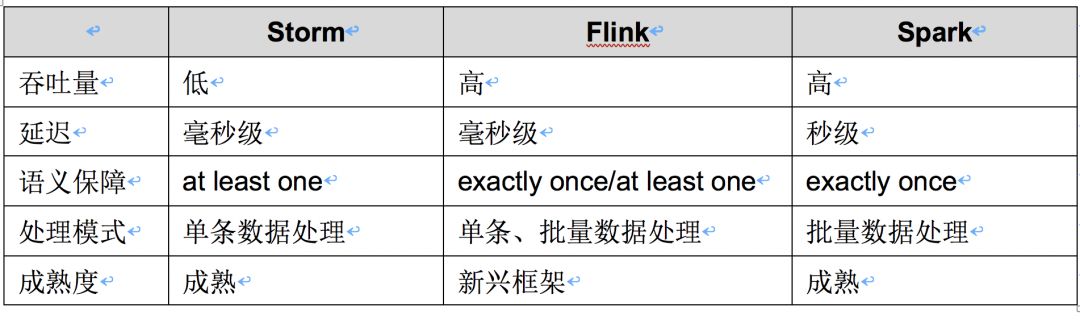
考虑到每个引擎的成熟度和特点,以及高可用性,我们选择了Storm作为本系统的实时处理引擎。
2. 分布式数据库
学生的学习过程数据规模较大,根据其使用场景,可以分为两类:计算过程数据和计算结果数据。计算过程数据主要是学生的学习行为,其规模较大,且插入频繁,但只参与学生平时成绩的计算,并不对外提供查询;计算结果数据是学生的平时成绩结果,其规模相对较小,但更新频繁,需要对外提供查询,并支持排序、多种组合条件的查询需求。
综上所述,可以将计算结果数据保存到关系型数据库中,支持排序以及多种组合条件的查询,将计算过程数据保存到分布式数据库中,将数据读写分散到多个节点中,减小关系型数据库的压力,从而提高整体性能。
目前比较成熟和流行的分布式数据库主要有Cassandra和HBase,这两个数据库产品都有其特点和应用场景,下表是对Cassandra和HBase的简单对比:

综合考虑读写性能、高可用和部署运维的难易度,我们选择了Cassandra作为本系统的分布式数据库。
在Cassandra中,学生每日学习过程数据存储结构如下表所示:
其中:学生ID作为Partition Key对数据分区,Cassandra用学生ID决定集群中的哪个节点来记录该数据。
实施方案
总结
以上就是平时成绩服务的设计思路与框架,并且已应用到系统中。为了给学生更好的学习体验,在业务不断增长的情况下,对用户行为数据的实时分析就需要更加全面,所以在实时数据分析方面,将来还有很多有价值的功能需要我们去实现。
数据量大、实时性要求高,是本系统设计过程中两个最大的挑战,在技术选型上,我们基于产品成熟度、编程模型复杂度、部署运维工作量等方面做了细致的分析,在数据分类和功能设计上,也做到了合理规划,后续会持续完善数据挖掘和流转的速度,更好的发挥数据价值。
以上是关于基于Storm与Cassandra的实时计算与大数据实践的主要内容,如果未能解决你的问题,请参考以下文章