大数据全分布式实时计算系统Apache Storm环境搭建
Posted Hadoop生态社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据全分布式实时计算系统Apache Storm环境搭建相关的知识,希望对你有一定的参考价值。
大数据全分布式
实时计算系统Apache Storm环境搭建
今天与大家分享的是关于大数据实时计算系统Apache Storm的环境搭建,服务器配置如下:
主机名称 |
Storm集群 |
|
bigdata112 |
192.168.189.112 |
Nimbus |
bigdata113 |
192.168.189.113 |
Nimbus(备用)、Supervisor |
bigdata114 |
192.168.189.114 |
Supervisor |
我们选用三台机器作为服务器,112作为Nimbus服务主节点,113作为Nimbus服务备用节点(主要用于实现Storm集群的高可用性HA)和Supervisor从节点,114作为Supervisor从节点。现在我们开始:
0、搭建ZooKeeper全分布式环境
搭建Storm集群前,我们需要搭建好ZooKeeper集群,请参见我们之前分享的《ZooKeeper系列(一)之集群环境搭建》一文!这里不再累述。
1、文件上传
将apache-storm-1.0.3.tar.gz文件从Windows系统本地上传至bigdata112的Linux系统/root/tools/目录下,如下图:
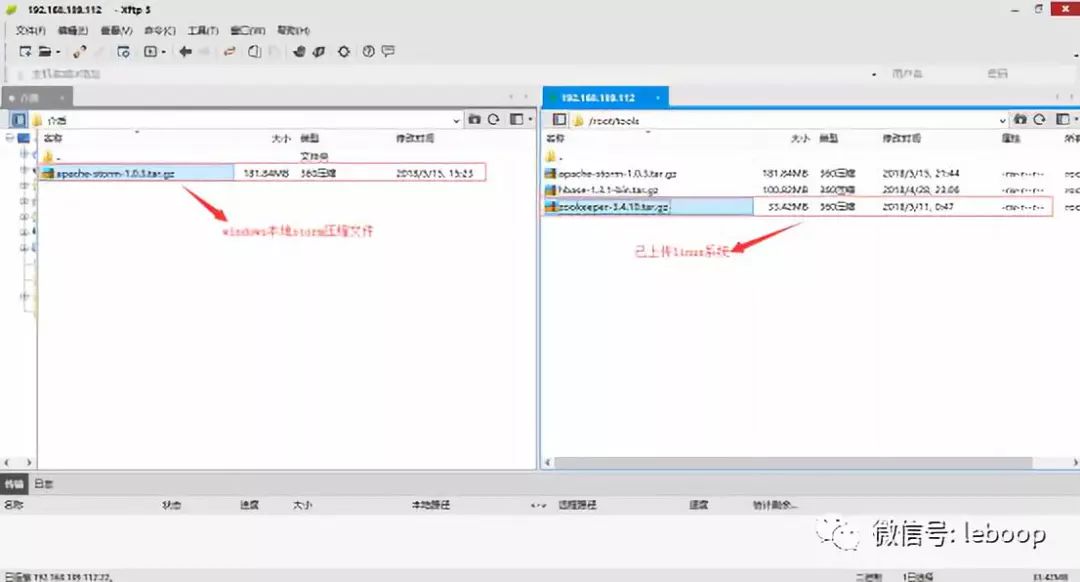
我们登录bigdata112服务器,查看文件是否上传成功,如下:

文件已经上传成功!
2、解压文件
在/root/tools/目录下执行tar -zxvf apache-storm-1.0.3.tar.gz -C ~/training/命令,将上传的安装文件解压到/root/training/目录下,然后进入/root/training/目录查看是否解压成功,如图:

解压成功!
3、添加系统环境变量
执行vi ~/.bash_profile命令打开系统配置文件,在文件最后位置添加以下变量:
export STORM_HOME=/root/training/apache-storm-1.0.3
export PATH=$STORM_HOME/bin:$PATH
关闭并保存配置文件,执行source ~/.bash_profile生效配置文件!
4、修改storm核心配置文件storm.yaml
(1)创建storm任务保存目录tmp
我们进入/root/training/apache-storm-1.0.3目录下,执行mkdir tmp,创建storm任务的保存目录tmp,如图:

(2)修改配置文件storm.yaml
我们进入目录/root/training/apache-storm-1.0.3/conf下,如图:

执行vi storm.yaml命令,打开配置文件,做如下配置:
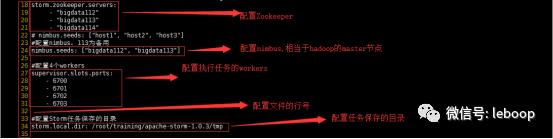
各配置详细如下:
a、配置ZooKeeper
ZooKeeper主要为集群提供协调服务,比如实现分布式锁(进程分布式锁,区别于JVM的线程分布式锁),具体配置如下:
18 storm.zookeeper.servers:
19 - "bigdata112"
20 - "bigdata113"
21 - "bigdata114"
b、配置nibus
为实现集群高可用性(HA),这里我们配置两台nimbus,当bigdata112挂掉,我们可以使用bigdata113作为nimbus继续提供服务,具体配置如下:
24 nimbus.seeds: ["bigdata112", "bigdata113"]
c、配置workers
这里我们配置执行任务的4个workers,通过端口号进行区分,具体如下:
26 #配置4个workers
27 supervisor.slots.ports:
28 - 6700
29 - 6701
30 - 6702
31 - 6703
d、配置任务保存目录
如下配置storm任务的保存目录:
34 storm.local.dir: /root/training/apache-storm-1.0.3/tmp
到这里,bigdata112服务器的storm环境已经搭建完成,下面我们在bigdata113和bigdata114上搭建storm环境!
5、远程拷贝storm
将bigdata112上已经配置好的storm安装目录和.bash_profile系统配置文件远程拷贝到bigdata113和bigdata114上,拷贝命令如下:
(1)目录拷贝
scp -r apache-storm-1.0.3/ root@192.168.189.113:/root/training/
scp -r apache-storm-1.0.3/ root@192.168.189.114:/root/training/
(2)配置文件拷贝
scp -r ~/.bash_profile root@192.168.189.113:~/
scp -r ~/.bash_profile root@192.168.189.114:~/
6、配置文件生效
登录bigdata113和bigdata114服务器,执行source ~/.bash_profile命令使配置文件生效。
至此,我们的storm集群环境已经搭建完成!下面我们测试环境是否搭建成功!
7、测试
(1)启动ZooKeeper集群
分别在三台服务器上执行zkServer.sh start启动ZooKeeper,然后执行zkServer.sh status查看Zookeeper启动情况,如下:
bigdata112,follower模式

bigdata113,leader模式

bigdata114,follower模式

(2)bigdata112上后台启动nimbus、ui、logviewer
服务nimbus启动日志如下:

storm界面管理页面启动日志如下:

storm日志查看器启动日志如下:

执行jps,查看nimbus、ui、logviewer是否正常启动,如下:

进程1591 QuorumPeerMain对应ZooKeeper服务,进程4699 core对应ui服务,4780 logviewer和4558 nimbus分别对应日志查看器服务和nimbus主服务!
(3)bigdata113后台启动nimbus、supervisor、logviewer服务
bigdata113启动详细如下:



查看supervisor、logviewer服务是否启动成功,如下:

已经启动成功!
(4)bigdata114后台启动supervisor、logviewer服务
启动步骤同bigdata113。
(5)登录Storm的ui界面查看
页面上半部分:
页面显示了Storm集群和Nimbus的概况,包括supervisor的数目,已经使用的workers数目,空闲的workers数目,总的workers数目。
页面下半部分:
页面显示了supervisor概况,包括supervisor的主机名称,supervisor对应的id编号,每个supervisor的workers数目!
到这里,整个Storm集群搭建成功!
如果想进一步了解Apache Storm的详细情况,参见官网http://storm.apache.org/
以上是关于大数据全分布式实时计算系统Apache Storm环境搭建的主要内容,如果未能解决你的问题,请参考以下文章