我就是认真:正确保障网络连接状态的通断,一文读懂 Keepalive 工作机制
Posted 高效运维
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我就是认真:正确保障网络连接状态的通断,一文读懂 Keepalive 工作机制相关的知识,希望对你有一定的参考价值。

场景一:Nginx的HTTP Keepalive功能
首先介绍一下“keepalive_timout”参数,这个参数的时间值意味着:一个http连接在传输完最后一个网络报文后,到它被服务端主动关闭之前的最长空闲时间。当httpd守护进程发送完一个响应后,理应马上主动关闭相应的http连接,但设置 keepalive_timeout后,httpd 守护进程会想说:”再等等吧,看看客户端还有没有请求过来”,这一等,便是 keepalive_timeout时间。
如果守护进程在这个等待的时间里,一直没有收到客户端发过来的 http请求,则关闭这个 http 连接。
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
server {
listen 8000;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
}使用IE浏览器访问url,正常得到结果后隔一段时间刷新页面,之后再隔一段时间后第二次刷新页面(两次等待的时间间隔小于上面配置的65秒)。整个过程使用tcpdump抓取nginx服务监听端口8000的网络包,结果如下:
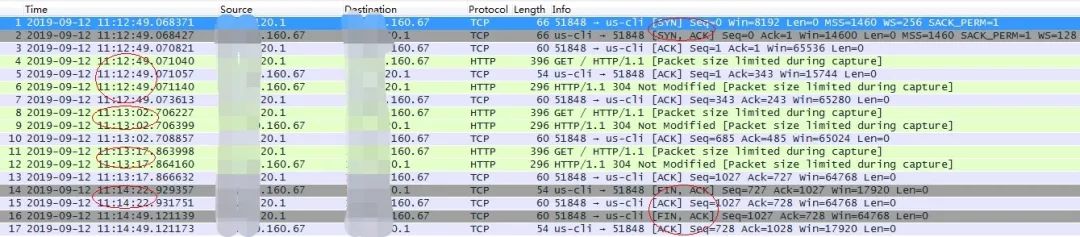
如果将IE浏览器换为火狐浏览器,同样的操作抓包结果会有什么不同呢?
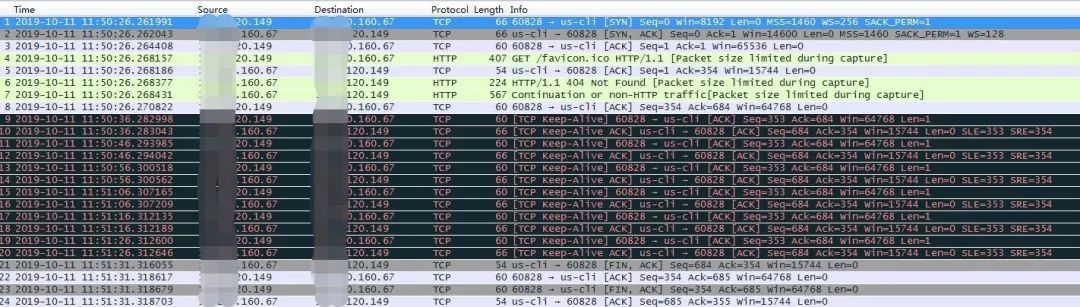
火狐浏览器默认会发送TCP KeepAlive探测包到服务端,当到达keepalive_timeout时间后,nginx依旧会关闭tcp连接。该实验说明nginx作为静态资源服务器时并不会处理TCP Keep-Alive探测报文,这种四层网络探测报文到达后是由操作系统直接做出应答的。
场景二:连接异常关闭、客户端不能接收到响应的情况
upstream WLS {
server 10.10.10.106:17101;
}
server {
server_name testWLS;
listen 9000;
error_log logs/testWLS_debug.log;
location /testWLS {
proxy_pass http://WLS;
proxy_http_version 1.1;
proxy_method POST;
proxy_read_timeout 30s;
proxy_set_header Connection "";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}浏览器正常访问url后等待响应,在整个过程中网络抓包内容如下:
nginx->服务端网络包

浏览器->nginx网络包(和上个网络包不是同一个实验下的抓取的)
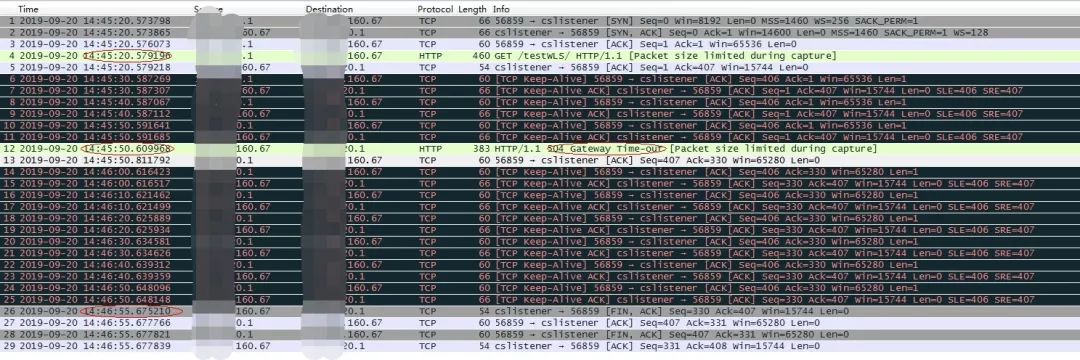
场景三:Nginx的TCP Keepalive功能

代理转发服务器配置
upstream rrups {
server 1.1.1.106:8011;
keepalive_timeout 60;
}
server {
server_name rrups.test;
listen 8000;
#error_log logs/rrups.log debug;
location / {
proxy_pass http://rrups;
proxy_http_version 1.1;
proxy_method POST;
proxy_set_header Connection "";
}
}上游服务器配置
server {
listen 8011 so_keepalive=15s:20s:;
default_type text/plain;
return 200 "106 server port 8011 response!";
}
代理转发服务器keepalive_timeout超时时间设置为60秒,上游服务器Tcp keepalive设置为15秒没有数据报文则发送探测报文,之后每隔20秒发送一次,发送次数使用系统默认的值。
浏览器访问代理转发nginx的监听端口8000,nginx将请求转发到106主机的8011端口(为了方便测试只配置了一台上游服务器),浏览器首次访问正常得到结果后,空闲一段时间刷新页面再次得到结果(间隔小于15秒),在代理转发服务器上使用tcpdump全程抓取到上游服务器的网络包,结果如下:
思考
类似Nginx的keepalive_timeout设置的是七层HTTP协议的超时时间,并不会处理TCP/IP四层网络模型的探测报文。那么类似Nginx的TCP KeepAlive是不是没有意义呢?答案当然是否定的。
但是,这些设备是可以捕获并处理TCP探测报文的,此时便可以通过设置类似Nginx的so_keepalive参数,或者直接修改操作系统默认的TCP Keepalive参数,在这些设备空闲连接超时前发送TCP探测报文,告诉这些设备连接是活动的暂时不要断开。
引申
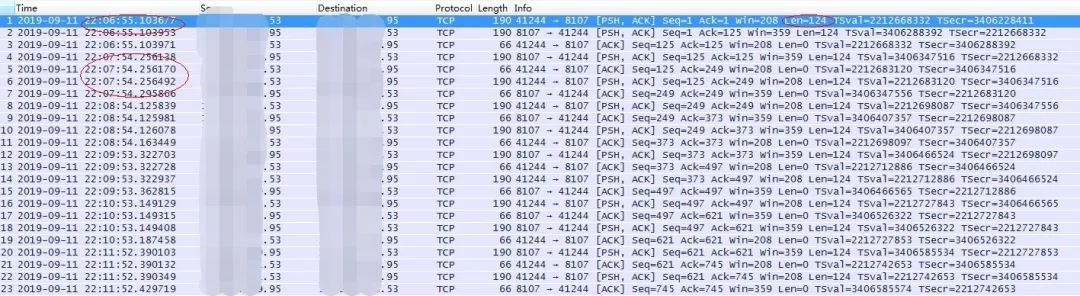
其实上面介绍的WTC探测属于应用层心跳探测,应用层心跳实现在第七层,so_keepalive是实现在TCP协议栈(四层即传输层),本质没有任何区别,但应用层需要自己来定义心跳包格式。既然有了TCP心跳,为什么还要应用层心跳呢?对于TCP心跳,只要当前连接是可用的,对方就会ACK我们的心跳,而对于当前对端应用是否能正常提供服务,TCP层的心跳机制是无法获知的。
总结
Keepalive相关参数使用的上下文和使用场景不尽相同。需要注意的是,这些参数的设置只能保证参数设置方在设置的条件范围内不会主动断开连接,但不能保证其上下游会先断开连接,在设置的时候需要综合考虑相关上下游服务器或网络设备的keepalive设置。
当出现连接被无故断开的时候,首先应查看相关软件和系统设备日志,一般会得到“连接超时/网络断开”类似的错误信息,然后需要排查请求链路上的相关软件和系统设备的超时时间设置,之后我们需要在请求链路上的相关服务器设备上收集tcpdump,找到主动断开连接的一方,并且计算出连接是在保持多长时间后被断开的,进而判断出是哪个参数生效的,最后我们需要根据实际情况调整相关参数或优化系统架构。
想与这么优质的文章作者面对面嗨聊?GOPS 2020 全球运维大会 · 深圳站,光大证券网络安全总监分享精彩议题。
以上是关于我就是认真:正确保障网络连接状态的通断,一文读懂 Keepalive 工作机制的主要内容,如果未能解决你的问题,请参考以下文章