一文读懂连接池技术原理设计与实现
Posted Python那些事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂连接池技术原理设计与实现相关的知识,希望对你有一定的参考价值。
如有好Python相关文章欢迎投稿至lansebolang2008@163.com
原创转载均可,转载稿请获取作者授权转载
概述
连接池的作用就是为了提高性能,将已经创建好的连接保存在池中,当有请求来时,直接使用已经创建好的连接对Server端进行访问。这样省略了创建连接和销毁连接的过程(TCP连接建立时的三次握手和销毁时的四次握手),从而在性能上得到了提高。
连接池设计的基本原理是这样的:
(1)建立连接池对象(服务启动)。
(2)按照事先指定的参数创建初始数量的连接(即:空闲连接数)。
(3)对于一个访问请求,直接从连接池中得到一个连接。如果连接池对象中没有空闲的连接,且连接数没有达到最大(即:最大活跃连接数),创建一个新的连接;如果达到最大,则设定一定的超时时间,来获取连接。
(4)运用连接访问服务。
(5)访问服务完成,释放连接(此时的释放连接,并非真正关闭,而是将其放入空闲队列中。如实际空闲连接数大于初始空闲连接数则释放连接)。
(6)释放连接池对象(服务停止、维护期间,释放连接池对象,并释放所有连接)。
说的通俗点,可以把连接池理解为一个一个的管道,在管道空闲时,便可以取出使用;同时,也可以铺设新的管道(当然不能超过最大连接数的限制)。使用完之后,管道就变为空闲了。
通常比较常用的连接池是数据库连接池,HTTP Client连接池,我也自己编写过连接池,如Thrift连接池及插入Rabbitmq队列的连接池。
下面分析三个典型的连接池的设计。
数据库连接池
首先剖析一下数据库连接池的设计与实现的原理。DBUtils 属于数据库连接池实现模块,用于连接DB-API 2模块,对数据库连接线程化,使可以安全和高效的访问数据库的模块。本文主要分析一下PooledDB的流程。
DBUtils.PooledDB使用DB-API 2模块实现了一个强硬的、线程安全的、有缓存的、可复用的数据库连接。
如下图展示了使用PooledDB时的工作流程:
本文主要考虑dedicated connections,即专用数据库连接,在初始化时连接池时,就需要指定mincached、maxcached以及maxconnections等参数,分别表示连接池的最小连接数、连接池的最大连接数以及系统可用的最大连接数,同时,blocking参数表征了当获取不到连接的时候是阻塞等待获取连接还是返回异常:
if not blocking:
def wait():
raise TooManyConnections
self._condition.wait = wait在连接池初始化时,就会建立mincached个连接,代码如下:
# Establish an initial number of idle database connections:
idle = [self.dedicated_connection() for i in range(mincached)]
while idle:
idle.pop().close()里面有close方法,看一下连接close方法的实现:
def close(self):
"""Close the pooled dedicated connection."""
# Instead of actually closing the connection,
# return it to the pool for future reuse.
if self._con:
self._pool.cache(self._con)
self._con = None主要是实现了cache方法,看一下具体代码:
def cache(self, con):
"""Put a dedicated connection back into the idle cache."""
self._condition.acquire()
try:
if not self._maxcached or len(self._idle_cache) < self._maxcached:
con._reset(force=self._reset) # rollback possible transaction
# the idle cache is not full, so put it there
self._idle_cache.append(con) # append it to the idle cache
else: # if the idle cache is already full,
con.close() # then close the connection
self._connections -= 1
self._condition.notify()
finally:
self._condition.release()由上述代码可见,close并不是把连接关闭,而是在连接池的数目小于maxcached的时候,将连接放回连接池,而大于此值时,关闭该连接。同时可以注意到,在放回连接池之前,需要将事务进行回滚,避免在使用连接池的时候有存活的事务没有提交。这可以保证进入连接池的连接都是可用的。
而获取连接的过程正如之前讨论的,先从连接池中获取连接,如果获取连接失败,则新建立连接:
# try to get a dedicated connection
self._condition.acquire()
try:
while (self._maxconnections
and self._connections >= self._maxconnections):
self._condition.wait()
# connection limit not reached, get a dedicated connection
try: # first try to get it from the idle cache
con = self._idle_cache.pop(0)
except IndexError: # else get a fresh connection
con = self.steady_connection()
else:
con._ping_check() # check connection
con = PooledDedicatedDBConnection(self, con)
self._connections += 1
finally:
self._condition.release()关闭连接正如刚刚创建mincached个连接后关闭连接的流程,在连接池的数目小于maxcached的时候,将连接放回连接池,而大于此值时,关闭该连接。
RabbitMQ队列插入消息连接池
异步消息传递是高并发系统常用的一种技术手段。而这其中就少不了消息队列。频繁的向消息队列里面插入消息,建立连接释放连接会是比较大的开销。所以,可以使用连接池来提高系统性能。
连接池的设计实现如下:
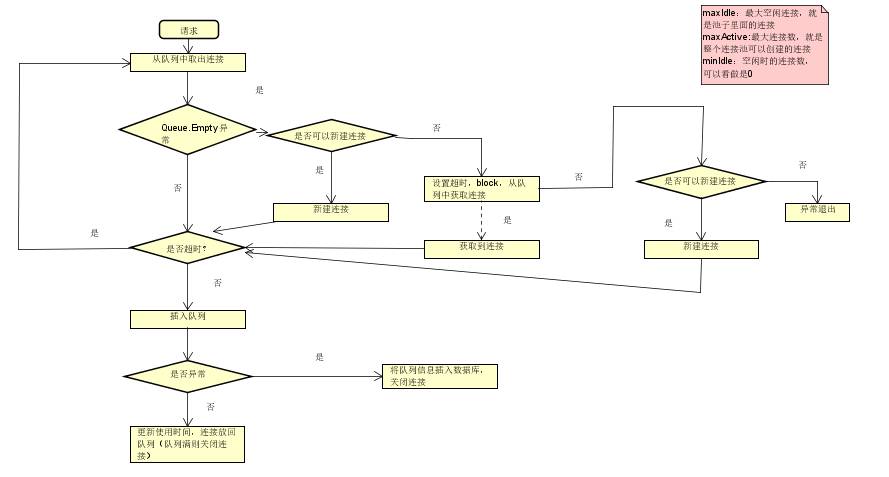
在获取连接的时候,先从队列里面获取连接,如果获取不到,则新建立一个连接,如果不能新建立连接,则根据超时时间,阻塞等待从队列里面获取链接。如果没成功,则做最后的尝试,重新建立连接。代码实现如下:
def get_connection_pipe(self):
"""
获取连接
:return:
"""
try:
connection_pipe = self._queue.get(False)
except Queue.Empty:
try:
connection_pipe = self.get_new_connection_pipe()
except GetConnectionException:
timeout = self.timeout
try:
connection_pipe = self._queue.get(timeout=timeout)
except Queue.Empty:
try:
connection_pipe = self.get_new_connection_pipe()
except GetConnectionException:
logging.error("Too much connections, Get Connection Timeout!")
if (time.time() - connection_pipe.use_time) > self.disable_time:
self.close(connection_pipe)
return self.get_connection_pipe()
return connection_pipe一个RabbitMQ插入消息队列的完整连接池设计如下:
# coding:utf-8
import logging
import threading
import Queue
from kombu import Connection
import time
class InsertQueue():
def __init__(self, host=None, port=None, virtual_host=None, heartbeat_interval=3, name=None, password=None,
logger=None, maxIdle=10, maxActive=50, timeout=30, disable_time=20):
"""
:param str host: Hostname or IP Address to connect to
:param int port: TCP port to connect to
:param str virtual_host: RabbitMQ virtual host to use
:param int heartbeat_interval: How often to send heartbeats
:param str name: auth credentials name
:param str password: auth credentials password
"""
self.logger = logging if logger is None else logger
self.host = host
self.port = port
self.virtual_host = virtual_host
self.heartbeat_interval = heartbeat_interval
self.name = name
self.password = password
self.mutex = threading.RLock()
self.maxIdle = maxIdle
self.maxActive = maxActive
self.available = self.maxActive
self.timeout = timeout
self._queue = Queue.Queue(maxsize=self.maxIdle)
self.disable_time = disable_time
def get_new_connection_pipe(self):
"""
产生新的队列连接
:return:
"""
with self.mutex:
if self.available <= 0:
raise GetConnectionException
self.available -= 1
try:
conn = Connection(hostname=self.host,
port=self.port,
virtual_host=self.virtual_host,
heartbeat=self.heartbeat_interval,
userid=self.name,
password=self.password)
producer = conn.Producer()
return ConnectionPipe(conn, producer)
except:
with self.mutex:
self.available += 1
raise GetConnectionException
def get_connection_pipe(self):
"""
获取连接
:return:
"""
try:
connection_pipe = self._queue.get(False)
except Queue.Empty:
try:
connection_pipe = self.get_new_connection_pipe()
except GetConnectionException:
timeout = self.timeout
try:
connection_pipe = self._queue.get(timeout=timeout)
except Queue.Empty:
try:
connection_pipe = self.get_new_connection_pipe()
except GetConnectionException:
logging.error("Too much connections, Get Connection Timeout!")
if (time.time() - connection_pipe.use_time) > self.disable_time:
self.close(connection_pipe)
return self.get_connection_pipe()
return connection_pipe
def close(self, connection_pipe):
"""
close the connection and the correlative channel
:param connection_pipe:
:return:
"""
with self.mutex:
self.available += 1
connection_pipe.close()
return
def insert_message(self, exchange=None, body=None, routing_key='', mandatory=True):
"""
insert message to queue
:param str exchange: exchange name
:param str body: message
:param str routing_key: routing key
:param bool mandatory: is confirm: True means confirm, False means not confirm
:return:
"""
put_into_queue_flag = True
insert_result = False
connection_pipe = None
try:
connection_pipe = self.get_connection_pipe()
producer = connection_pipe.channel
use_time = time.time()
producer.publish(exchange=exchange,
body=body,
delivery_mode=2,
routing_key=routing_key,
mandatory=mandatory
)
insert_result = True
except Exception:
insert_result = False
put_into_queue_flag = False
finally:
if put_into_queue_flag is True:
try:
connection_pipe.use_time = use_time
self._queue.put_nowait(connection_pipe)
except Queue.Full:
self.close(connection_pipe)
else:
if connection_pipe is not None:
self.close(connection_pipe)
return insert_result
class ConnectionPipe(object):
"""
connection和channel对象的封装
"""
def __init__(self, connection, channel):
self.connection = connection
self.channel = channel
self.use_time = time.time()
def close(self):
try:
self.connection.close()
except Exception as ex:
pass
class GetConnectionException():
"""
获取连接异常
"""
passThrift连接池
Thrift是什么呢?简而言之,Thrift定义一个简单的文件,包含数据类型和服务接口,以作为输入文件,编译器生成代码用来方便地生成RPC客户端和服务器通信的方式。实际上就是一种远程调用的方式,因为协议栈为TCP层,所以相对于HTTP层效率会更高。
Thrift连接池的设计同数据库连接池类似,流程图如下:
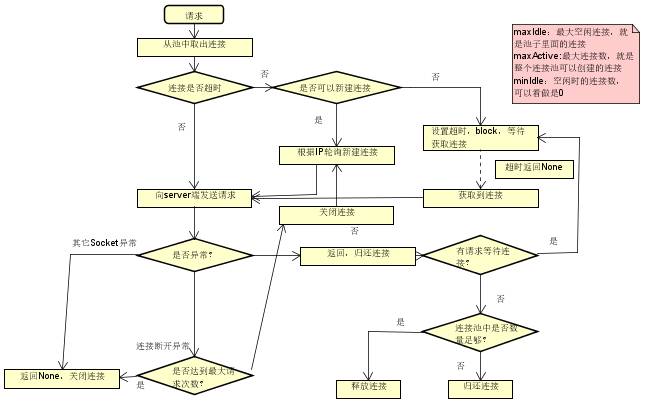
思路依旧是,在获取连接时,先从连接池中获取连接,若池中无连接,则判断是否可以新建连接,若不能新建连接,则阻塞等待连接。
在从池中获取不到队列的时候的处理方式,本设计处理方式为:当获取不到连接时,将这部分请求放入一个等待队列,等待获取连接;而当关闭连接放回连接池时,优先判断这个队列是否有等待获取连接的请求,若有,则优先分配给这些请求。
获取不到连接时处理代码如下,将请求放入一个队列进行阻塞等待获取连接:
async_result = AsyncResult()
self.no_client_queue.appendleft(async_result)
client = async_result.get() # blocking而当有连接释放需要放回连接池时,需要优先考虑这部分请求,代码如下:
def put_back_connections(self, client):
"""
线程安全
将连接放回连接池,逻辑如下:
1、如果有请求尚未获取到连接,请求优先
2、如果连接池中的连接的数目小于maxIdle,则将该连接放回连接池
3、关闭连接
:param client:
:return:
"""
with self.lock:
if self.no_client_queue.__len__() > 0:
task = self.no_client_queue.pop()
task.set(client)
elif self.connections.__len__() < self.maxIdle:
self.connections.add(client)
else:
client.close()
self.pool_size -= 1最后,基于thrift连接池,介绍一个简单的服务化框架的实现。
服务化框架分为两部分:RPC、注册中心。
1、RPC:远程调用,远程调用的传输协议有很多种,可以走http、Webservice、TCP等。Thrift也是世界上主流的RPC框架。其重点在于安全、快速、最好能跨语言。
通常的架构图为:
通过Thrift连接池作为客户端,而Zookeeper作为注册中心,设计服务框架。具体就是服务端在启动服务的时候到Zookeeper进行注册,而客户端在启动的时候通过Zookeeper发现服务端的IP和端口,通过Thrift连接池轮询建立连接访问服务端的服务。
具体设计的代码如下,代码有点长,细细研读一定有所收获的:
# coding: utf-8
import threading
from collections import deque
import logging
import socket
import time
from kazoo.client import KazooClient
from thriftpy.protocol import TBinaryProtocolFactory
from thriftpy.transport import (
TBufferedTransportFactory,
TSocket,
)
from gevent.event import AsyncResult
from gevent import Timeout
from error import CTECThriftClientError
from thriftpy.thrift import TClient
from thriftpy.transport import TTransportException
class ClientPool:
def __init__(self, service, server_hosts=None, zk_path=None, zk_hosts=None, logger=None, max_renew_times=3, maxActive=20,
maxIdle=10, get_connection_timeout=30, socket_timeout=30, disable_time=3):
"""
:param service: Thrift的Service名称
:param server_hosts: 服务提供者地址,数组类型,['ip:port','ip:port']
:param zk_path: 服务提供者在zookeeper中的路径
:param zk_hosts: zookeeper的host地址,多个请用逗号隔开
:param max_renew_times: 最大重连次数
:param maxActive: 最大连接数
:param maxIdle: 最大空闲连接数
:param get_connection_timeout:获取连接的超时时间
:param socket_timeout: 读取数据的超时时间
:param disable_time: 连接失效时间
"""
# 负载均衡队列
self.load_balance_queue = deque()
self.service = service
self.lock = threading.RLock()
self.max_renew_times = max_renew_times
self.maxActive = maxActive
self.maxIdle = maxIdle
self.connections = set()
self.pool_size = 0
self.get_connection_timeout = get_connection_timeout
self.no_client_queue = deque()
self.socket_timeout = socket_timeout
self.disable_time = disable_time
self.logger = logging if logger is None else logger
if zk_hosts:
self.kazoo_client = KazooClient(hosts=zk_hosts)
self.kazoo_client.start()
self.zk_path = zk_path
self.zk_hosts = zk_hosts
# 定义Watcher
self.kazoo_client.ChildrenWatch(path=self.zk_path,
func=self.watcher)
# 刷新连接池中的连接对象
self.__refresh_thrift_connections(self.kazoo_client.get_children(self.zk_path))
elif server_hosts:
self.server_hosts = server_hosts
# 复制新的IP地址到负载均衡队列中
self.load_balance_queue.extendleft(self.server_hosts)
else:
raise CTECThriftClientError('没有指定服务器获取方式!')
def get_new_client(self):
"""
轮询在每个ip:port的连接池中获取连接(线程安全)
从当前队列右侧取出ip:port信息,获取client
将连接池对象放回到当前队列的左侧
请求或连接超时时间,默认30秒
:return:
"""
with self.lock:
if self.pool_size < self.maxActive:
try:
ip = self.load_balance_queue.pop()
except IndexError:
raise CTECThriftClientError('没有可用的服务提供者列表!')
if ip:
self.load_balance_queue.appendleft(ip)
# 创建新的thrift client
t_socket = TSocket(ip.split(':')[0], int(ip.split(':')[1]),
socket_timeout=1000 * self.socket_timeout)
proto_factory = TBinaryProtocolFactory()
trans_factory = TBufferedTransportFactory()
transport = trans_factory.get_transport(t_socket)
protocol = proto_factory.get_protocol(transport)
transport.open()
client = TClient(self.service, protocol)
self.pool_size += 1
return client
else:
return None
def close(self):
"""
关闭所有连接池和zk客户端
:return:
"""
if getattr(self, 'kazoo_client', None):
self.kazoo_client.stop()
def watcher(self, children):
"""
zk的watcher方法,负责检测zk的变化,刷新当前双端队列中的连接池
:param children: 子节点,即服务提供方的列表
:return:
"""
self.__refresh_thrift_connections(children)
def __refresh_thrift_connections(self, children):
"""
刷新服务提供者在当前队列中的连接池信息(线程安全),主要用于zk刷新
:param children:
:return:
"""
with self.lock:
# 清空负载均衡队列
self.load_balance_queue.clear()
# 清空连接池
self.connections.clear()
# 复制新的IP地址到负载均衡队列中
self.load_balance_queue.extendleft(children)
def __getattr__(self, name):
"""
函数调用,最大重试次数为max_renew_times
:param name:
:return:
"""
def method(*args, **kwds):
# 从连接池获取连接
client = self.get_client_from_pool()
# 连接池中无连接
if client is None:
# 设置获取连接的超时时间
time_out = Timeout(self.get_connection_timeout)
time_out.start()
try:
async_result = AsyncResult()
self.no_client_queue.appendleft(async_result)
client = async_result.get() # blocking
except:
with self.lock:
if client is None:
self.no_client_queue.remove(async_result)
self.logger.error("Get Connection Timeout!")
finally:
time_out.cancel()
if client is not None:
for i in xrange(self.max_renew_times):
try:
put_back_flag = True
client.last_use_time = time.time()
fun = getattr(client, name, None)
return fun(*args, **kwds)
except socket.timeout:
self.logger.error("Socket Timeout!")
# 关闭连接,不关闭会导致乱序
put_back_flag = False
self.close_one_client(client)
break
except TTransportException, e:
put_back_flag = False
if e.type == TTransportException.END_OF_FILE:
self.logger.warning("Socket Connection Reset Error,%s", e)
with self.lock:
client.close()
self.pool_size -= 1
client = self.get_new_client()
else:
self.logger.error("Socket Error,%s", e)
self.close_one_client(client)
break
except socket.error, e:
put_back_flag = False
if e.errno == socket.errno.ECONNABORTED:
self.logger.warning("Socket Connection aborted Error,%s", e)
with self.lock:
client.close()
self.pool_size -= 1
client = self.get_new_client()
else:
self.logger.error("Socket Error, %s", e)
self.close_one_client(client)
break
except Exception as e:
put_back_flag = False
self.logger.error("Thrift Error, %s", e)
self.close_one_client(client)
break
finally:
# 将连接放回连接池
if put_back_flag is True:
self.put_back_connections(client)
return None
return method
def close_one_client(self, client):
"""
线程安全
关闭连接
:param client:
:return:
"""
with self.lock:
client.close()
self.pool_size -= 1
def put_back_connections(self, client):
"""
线程安全
将连接放回连接池,逻辑如下:
1、如果有请求尚未获取到连接,请求优先
2、如果连接池中的连接的数目小于maxIdle,则将该连接放回连接池
3、关闭连接
:param client:
:return:
"""
with self.lock:
if self.no_client_queue.__len__() > 0:
task = self.no_client_queue.pop()
task.set(client)
elif self.connections.__len__() < self.maxIdle:
self.connections.add(client)
else:
client.close()
self.pool_size -= 1
def get_client_from_pool(self):
"""
线程安全
从连接池中获取连接,若连接池中有连接,直接取出,否则,
新建一个连接,若一直无法获取连接,则返回None
:return:
"""
client = self.get_one_client_from_pool()
if client is not None and (time.time() - client.last_use_time) < self.disable_time:
return client
else:
if client is not None:
self.close_one_client(client)
client = self.get_new_client()
if client is not None:
return client
return None
def get_one_client_from_pool(self):
"""
线程安全
从连接池中获取一个连接,若取不到连接,则返回None
:return:
"""
with self.lock:
if self.connections:
try:
return self.connections.pop()
except KeyError:
return None
return None推荐阅读
看完本文有收获?请转发分享给更多人
关注「Python那些事」,做全栈开发工程师
以上是关于一文读懂连接池技术原理设计与实现的主要内容,如果未能解决你的问题,请参考以下文章