MariaDB插上大数据的翅膀?——可能只是一厢情愿
Posted InsideMySQL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MariaDB插上大数据的翅膀?——可能只是一厢情愿相关的知识,希望对你有一定的参考价值。
姜承尧
IT圈最会讲故事的男人

今早收到MariaDB的邮件,告知ColumnStore引擎1.0.6版本GA发布。内心第一反应这是什么鬼?后花了整个下午阅读了下文档,发现其实就是之前已经关门大吉的InfiniDB存储引擎,换了个名字被整合到了MariaDB 10。
仔细研究MariaDB甚至回到最早的mysqlAB,你会发现Monty并不是开源的无产阶级先驱,他赚钱的钱并不少,当然对比InnoDB存储引擎的创始人HeikkiTuuri来说是拿少了,这个可以稍后另开一文好好聊聊。
因为最近公司在大刀阔斧的建设大数据平台,为不免俗套,对大数据的产品还算有所涉猎。看了ColumnStore的架构后发现其实所谓的大数据(bigdata),基本也都这么个套路。
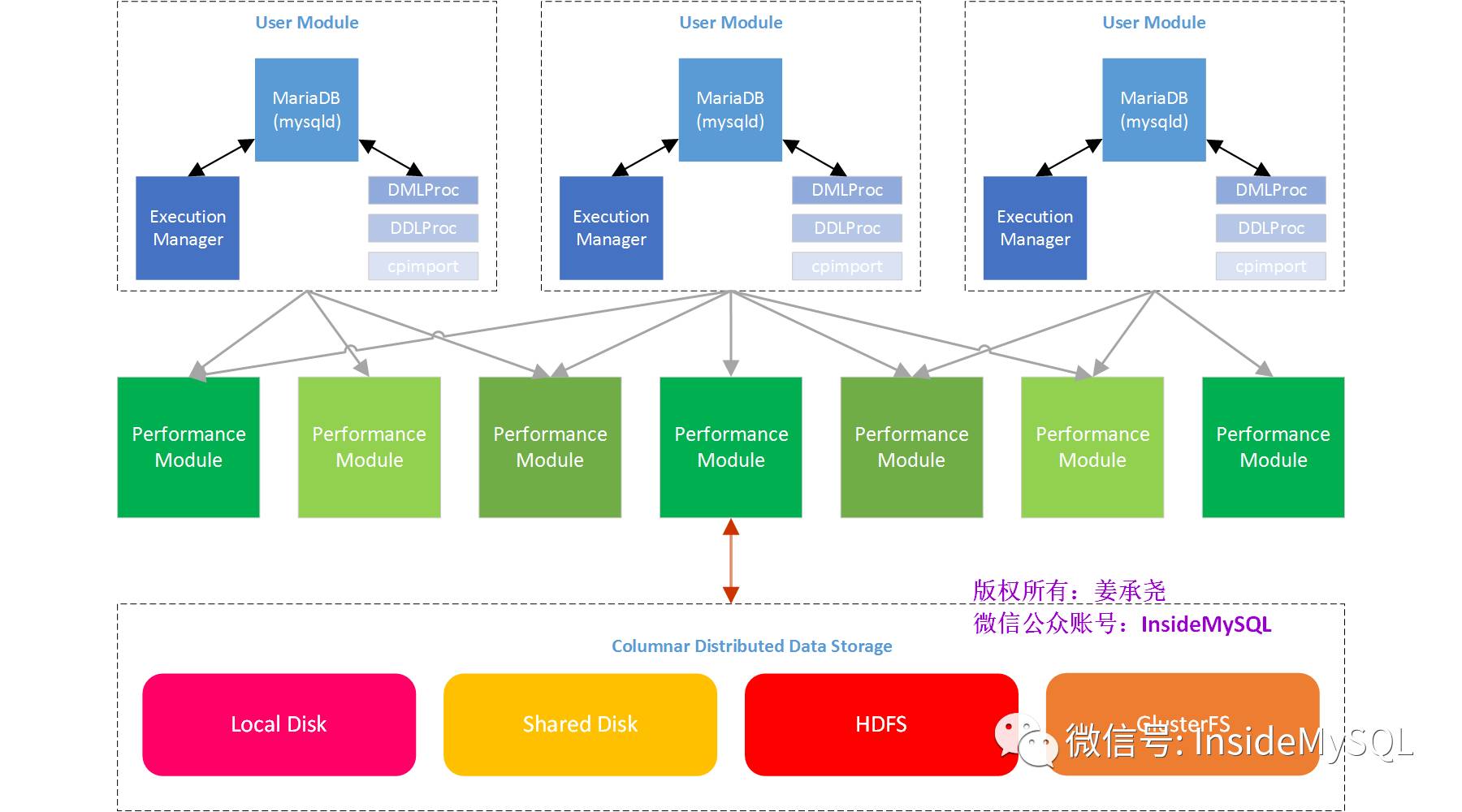
上图是根据文档整理的MariaDBColumn Store的架构图。与常见的大数据平台类似,分为计算层和存储层,同时也都是可扩展的。计算层需要由下面的几个主要进程构成:
MariaDB(mysqld):收集用户请求的一个SQL入口,存储元数据信息;
Execution Manager:收到MariaDB进程发送过来的语法树,转化成对应的任务列表(JOB LIST),包括优化、取数据、(HASH)JOIN、汇总、分组。这是UserModule的核心进程;
DMLProc:将DML语句发送到指定的Performance Module执行;
DDLProc:将DDL语句发送到指定的Performance Module执行;
cpimport:数据导入进程
Performance Module:接受Execution Manager发送过来的任务调度,分布式扫描,(HASH)JOIN与汇总
存储方面,目前的1.0.6版本支持本地磁盘与共享存储,后期官方还计划支持HDFS和GlusterFS这样的分布式文件系统,以提升数据的可靠性。
既然叫ColumnStore引擎,这意味着数据是根据列来进行存储的。粗看与Hive的Parquet和Kudu的存储方式比较类似,与之前的MySQL的InfoBright存储引擎更为接近。
ColumnStore引擎表是没有二级索引的,数据按列存放在Extent中,根据列的类型,每个Extent的大小为8M ~64M,默认采用snappy算法进行压缩。Extent是由8K大小的block所组成。每个Extent有Extent Map,用于记录每个block的最大值(maxvalue)与最小值(maxvalue),用于范围查询与数据过滤。越看越觉得就是InfoBright知识网(Knowledge Grid)的简化版本。
一代关系型数据库大师Michael Stonebraker对于Hadoop大数据平台是嗤之以鼻的,曾在多个正式与非正常的场合与其互斯。然而,这并没阻止Hive、Impala、Spark这些大数据产品的飞速发展。相反,InfoBright、InfiniDB、C-Store反而落得了一个“倒闭”的结局。
反观传统的数据库厂商,微软并没有基于SQL Server去做大数据软件产品,Oracle甚至拿不出一个大数据时代的MPP产品,EMC也甩手了Greenplum。这么看来,InfiniDB想借尸还魂,成功的可能性微乎其微。那么,到底是什么原因导致了传统关系型数据库在大数据时代的集体沉沦呢?
猜你喜欢
以上是关于MariaDB插上大数据的翅膀?——可能只是一厢情愿的主要内容,如果未能解决你的问题,请参考以下文章