基于 阿里云 RDS PostgreSQL 打造实时用户画像推荐系统
Posted PostgreSQL中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 阿里云 RDS PostgreSQL 打造实时用户画像推荐系统相关的知识,希望对你有一定的参考价值。
背景
用户画像在市场营销的应用重建中非常常见,已经不是什么新鲜的东西,比较流行的解决方案是给用户贴标签,根据标签的组合,圈出需要的用户。
通常画像系统会用到宽表,以及分布式的系统。
宽表的作用是存储标签,例如每列代表一个标签。
但实际上这种设计不一定是最优或唯一的设计,本文将以PostgreSQL数据库为基础,给大家讲解一下更加另类的设计思路,并且看看效率如何。
业务场景模拟
假设有一个2B的实时用户推荐系统,每个APPID代表一个B。
业务数据包括APPID,USERIDs,TAGs。(2B的用户ID,最终用户ID,标签)
业务没有跨APPID的数据交换操作需求,也就是说仅限于APPID内的用户推荐。
查询局限在某个选定的APPID,以及TAG组合,搜索符合条件的USERID,并将USERID推送给用户。
数据总量约10亿,单个APPID的用户数最大约1亿。
TAG总数设计容量为1万个。
查询需求: 包含,不包含,或,与。
并发几百,RT 毫秒级。
接下来我会列举4个方案,并分析每种方案的优缺点。
一、宽表方案分析
通常表的宽度是有限制的,以PostgreSQL为例,一条记录是无法跨PAGE的(变长字段存储到TOAST存储,以存储超过1页大小的列,页内只存储指针),这就使得表的宽度受到了限制。
例如8KB的数据块,可能能存下接近2000个列。
如果要为每个TAG设计一个列,则需要1万个列的宽表。
相信其它数据库也有类似的限制,1万个列的宽表,除非改造数据库内核,否则无法满足需求。
那么可以使用APPID+USERID作为PK,存储为多个表来实现无限个TAG的需求。 以单表1000个列为例,10个表就能满足1万个TAG的需求。
create table t_tags_1(appid int, userid int8, tag1 boolean, tag2 boolean, ...... tag1000 boolean);
.....
create table t_tags_10(appid int, userid int8, tag9001 boolean, tag9002 boolean, ...... tag10000 boolean);
为了提升效率,要为每个tag字段创建索引,也就是说需要1万个索引。
如果TAG的组合跨表了,还有JOIN操作。
1. 优点
没有用什么特殊的优化,几乎所有的数据库都支持。
2. 缺点
性能不一定好,特别是查询组合条件多的话,性能会下降比较明显,例如(tag1 and tag2 and (tag4 or tag5) or not tag6) 。
二、数组方案分析
使用数组代替TAG列,要求数据库有数组类型,同时有数组的高效检索能力,这一点PostgreSQL可以很好的满足需求。
1. 数据结构
APPID, USERID, TAG[] 数组
单个数组最大长度1GB(约支持2.6亿个TAG)
2. 按APPID分区,随机分片
3. query语法
3.1 包含array2指定的所有TAG
数组1包含数组2的所有元素
array1 @> array2
支持索引检索
3.2 包含array2指定的TAG之一
数组1与数组2有重叠元素
array1 && array2
支持索引检索
3.3 不包含array2指定的所有tag
数组1与数组2没有重叠元素
not array1 && array2
不支持索引检索
4. 例子
create table t_arr(appid int, userid int8, tags int2[]) with(parallel_workers=128);
create index idx_t_array_tags on t_arr using gin (tags) with (fastupdate=on, gin_pending_list_limit= 1024000000);
create index idx_t_arr_uid on t_arr(userid);
819200KB约缓冲10000条80K的数组记录,可以自行调整.
1.每个USERID包含10000个TAG(极限)。
insert into t_arr select 1, 2000000000*random(),(select array_agg(10000*random()) from generate_series(1,10000));
nohup pgbench -M prepared -n -r -f ./test.sql -P 1 -c 50 -j 50 -t 2000000 > ./arr.log 2>&1 &
5. 优点
可以存储很多TAG,几亿个足够用啦(行业内有1万个TAG的已经是非常多的啦)。
支持数组的索引查询,但是not不支持索引。
6. 缺点
数据量还是有点大,一条记录1万个TAG,约80KB。
1亿记录约8TB,索引还需要约8TB。
不是所有的数据库都支持数组类型。
三、比特位方案1分析
使用BIT存储TAG,0和1表示有或者没有这个TAG。
1. 数据结构
APPID, USERID, TAG 比特流
单个BIT字段最大支持1GB长度BIT流(支持85亿个TAG)
每个BIT代表一个TAG
2. 按APPID分区,随机分片
3. query语法
3.1 包含bit2指定的所有TAG(需要包含的TAG对应的BIT设置为1,其他为0)
bitand(bit1,bit2) = bit2
3.2 包含bit2指定的TAG之一(需要包含的TAG对应的BIT设置为1,其他为0)
bitand(bit1,bit2) > 0
3.3 不包含bit2指定的所有tag (需要包含的TAG对应的BIT设置为1,其他为0)
bitand(bit1,bit2) = zerobit(10000)
4. 例子
5. 优点
可以存储很多TAG,85亿个TAG足够用啦吧(行业内有1万个TAG的已经是非常多的啦)。
1万个TAG,占用1万个BIT,约1.25KB。
1亿记录约120GB,无索引。
6. 缺点
没有索引方法,查询是只能通过并行计算提升性能。
PostgreSQL 9.6 支持CPU并行计算,1亿用户时,可以满足20秒内返回,但是会消耗很多的CPU资源,因此查询的并行度不能做到很高。
四、比特位方案2分析
有没有又高效,又节省资源的方法呢?
答案是有的。
因为查询通常是以TAG为组合条件,取出复合条件的USERID的查询。
所以反过来设计,查询效果就会很好,以TAG为维度,USERID为比特位的设计。
我们需要维护的是每个tag下有哪些用户,所以这块的数据更新量会很大,需要考虑增量合并与读时合并的设计。
数据流如下,数据可以快速的写入
data -> 明细表 -> 增量聚合 -> appid, tagid, userid_bits
读取时,使用两部分数据进行合并,一部分是tag的计算结果,另一部分是未合并的明细表的结果,两者MERGE。
当然,如果可以做到分钟内的合并延迟,业务也能够忍受分钟的延迟的话,那么查询是就没有MERGE的必要了,直接查结果,那会非常非常快。
1. query
1.1 包含这些tags的用户
userids (bitand) userids
结果为bit位为1的用户
1.2 不包含这些tags的用户
userids (bitor) userids
结果为bit位为0的用户
1.3 包含这些tags之一的用户
userids (bitor) userids
结果为bit位为1的用户
2. 优点
因为数据存储的维度发生了变化,采用以查询为目标的设计,数据的查询效率非常高。
3. 缺点
由于使用了比特位表示USERID,所以必须有位置与USERID的映射关系。
需要维护用户ID字典表,需要使用增量合并的手段减少数据的更新频率。
会有一定的延迟,通常可以控制在分钟内,如果业务允许这样的延迟,则非常棒。
通常业务的USERID会周期性的失效(例如僵尸USERID,随着时间可以逐渐失效),那么需要周期性的维护用户ID字典,同时也要更新USERID比特信息。
架构如图
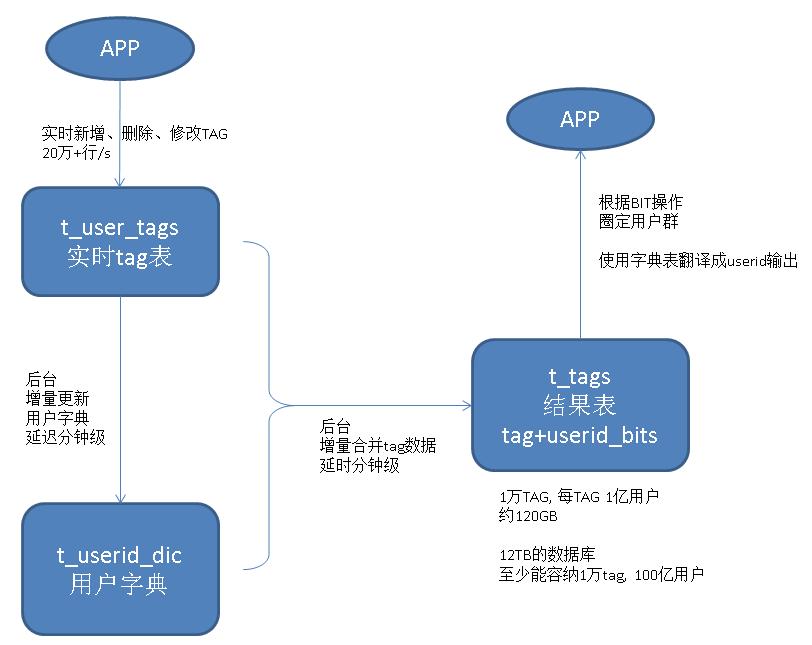
五、比特位方案2实施细节
阿里云RDS PostgreSQL 新增的bit操作函数
本文会用到几个新增的FUNCTION,这几个function很有用,同时会加入阿里云的RDS PostgreSQL中。
get_bit (varbit, int, int) returns varbit
从指定位置开始获取N个BIT位,返回varbit
例如 get_bit('111110000011', 3, 5) 返回11000
set_bit_array (varbit, int, int, vardict int[]) returns varbit
将指定位置的BIT设置为0|1,超出原始varbit长度的部分填充0|1 (超出部分并且在array中的位置BIT依旧按提供的BIT设置)
例如 set_bit_array('1111000011110000', 0, 1, array[1,15]) (1,15设置为0,超出部分设置为1)返回 10110000111100001110
bit_count (varbit, int, int, int) returns int
从第n位开始,统计N个BIT位中有多少个0|1,如果N超出长度,则只计算已经存在的。
例如 bit_count('1111000011110000', 1, 5, 4) 返回 1 (0001)
bit_count (varbit, int) returns int
统计整个bit string中1|0的个数。
例如 bit_count('1111000011110000', 1) 返回 8
bit_fill (int, int) returns varbit
填充指定长度的0 或 1
例如 bit_fill(0,10) 返回 '0000000000'
bit_rand (int, int, float) returns varbit
填充指定长度的随机BIT,并指定1或0的随机比例
例如 bit_rand(10, 1, 0.3) 可能返回 '0101000001'
bit_posite (varbit, int, boolean) returns int[]
返回 1|0 的位置信息,下标从0开始计数, true时正向返回,false时反向返回
例如 bit_posite ('11110010011', 1, true) 返回 [0,1,2,3,6,9,10]
bit_posite ('11110010011', 1, false) 返回 [10,9,6,3,2,1,0]
bit_posite (varbit, int, int, boolean) returns int[]
返回 1|0 的位置信息,下标从0开始计数,true时正向返回,false时反向返回,返回N个为止
例如 bit_posite ('11110010011', 1, 3, true) 返回 [0,1,2]
bit_posite ('11110010011', 1, 3, false) 返回 [10,9,6]
get_bit_2 (varbit, int, int) returns int
返回指定位置的bit, 下标从0开始,如果超出BIT位置,返回指定的0或1.
例如 get_bit_2('111110000011', 100, 0) 返回 0 (100已经超出长度,返回用户指定的0)
数据库内置的BIT操作函数请参考源码
src/backend/utils/adt/varbit.c
表结构设计
使用bit存储用户
userid int8表示,可以超过40亿。
rowid int表示,也就是说单个APPID不能允许超过20亿的用户,从0开始自增,配合BIT下标的表示。
appid int表示,不会超过40亿个。
1. 字典表, rowid决定MAP顺序,使用窗口查询返回顺序。
drop table IF EXISTS t_userid_dic;
create table IF NOT EXISTS t_userid_dic(appid int not null, rowid int not null, userid int8 not null, unique (appid,userid), unique (appid,rowid));
插入用户字典表的函数,可以产生无缝的连续ROWID。
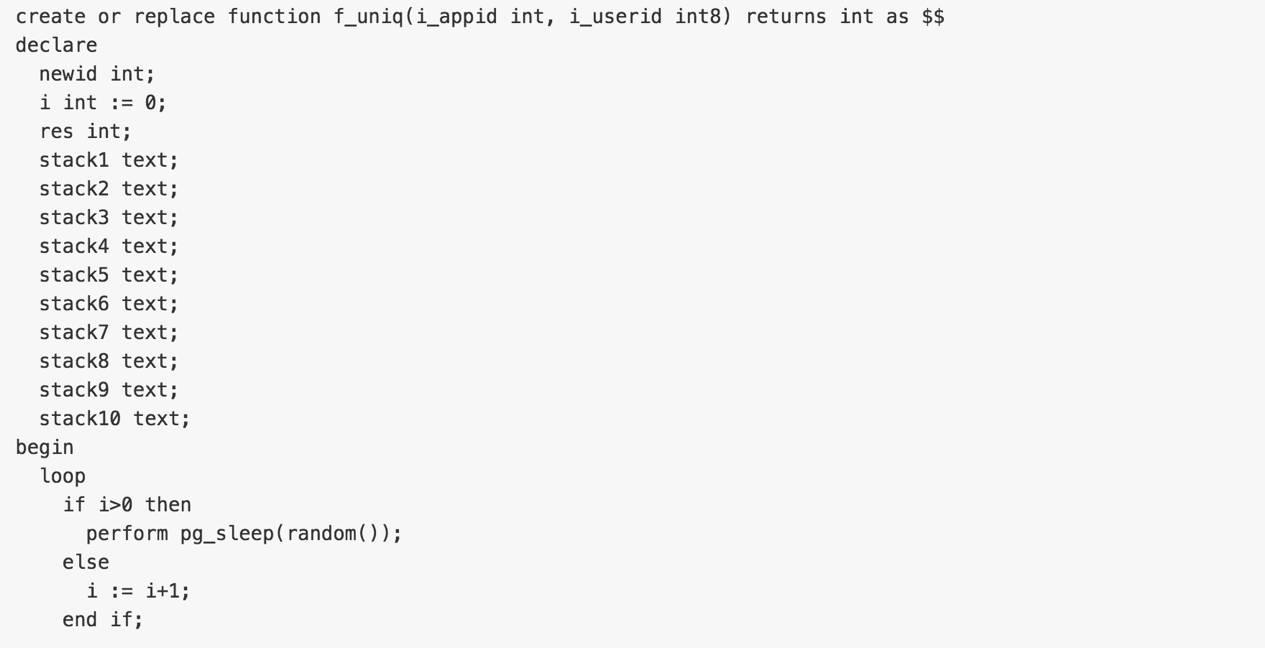



如果以上调用返回NULL,说明插入失败,可能违反了唯一约束,应用端重试即可。
压测以上函数是否能无缝插入,压测时raise notice可以去掉。
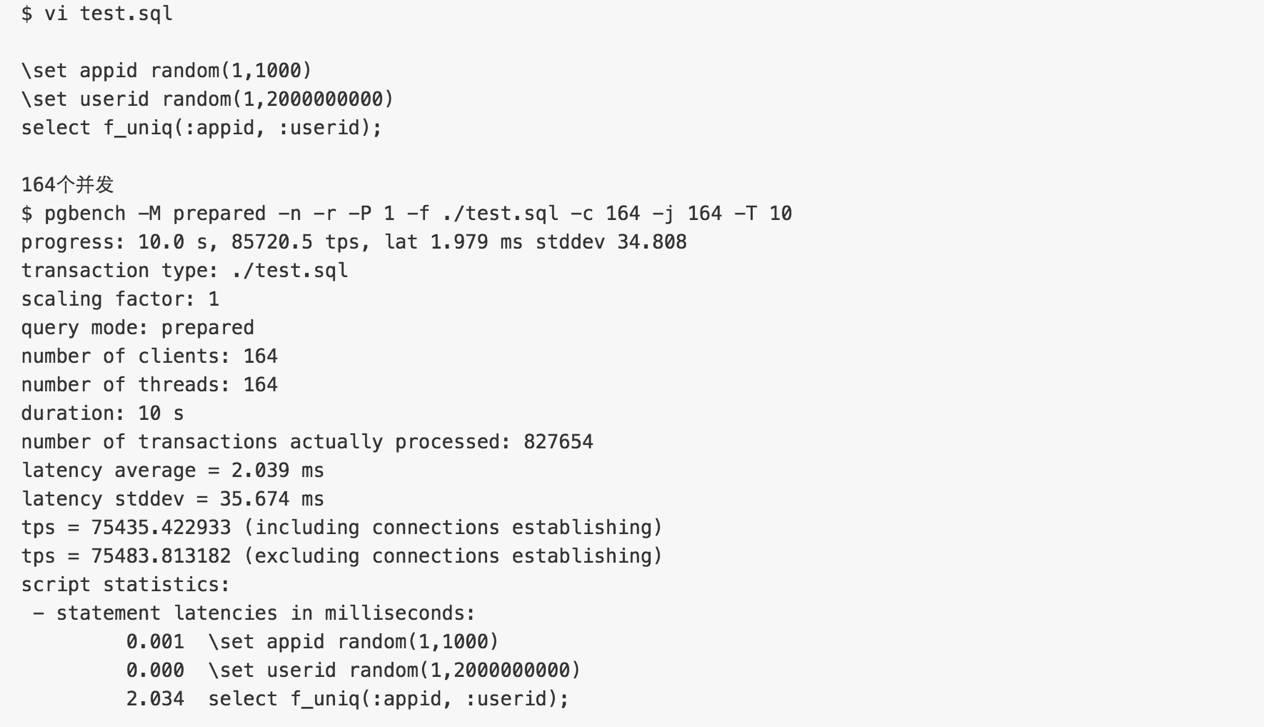
验证
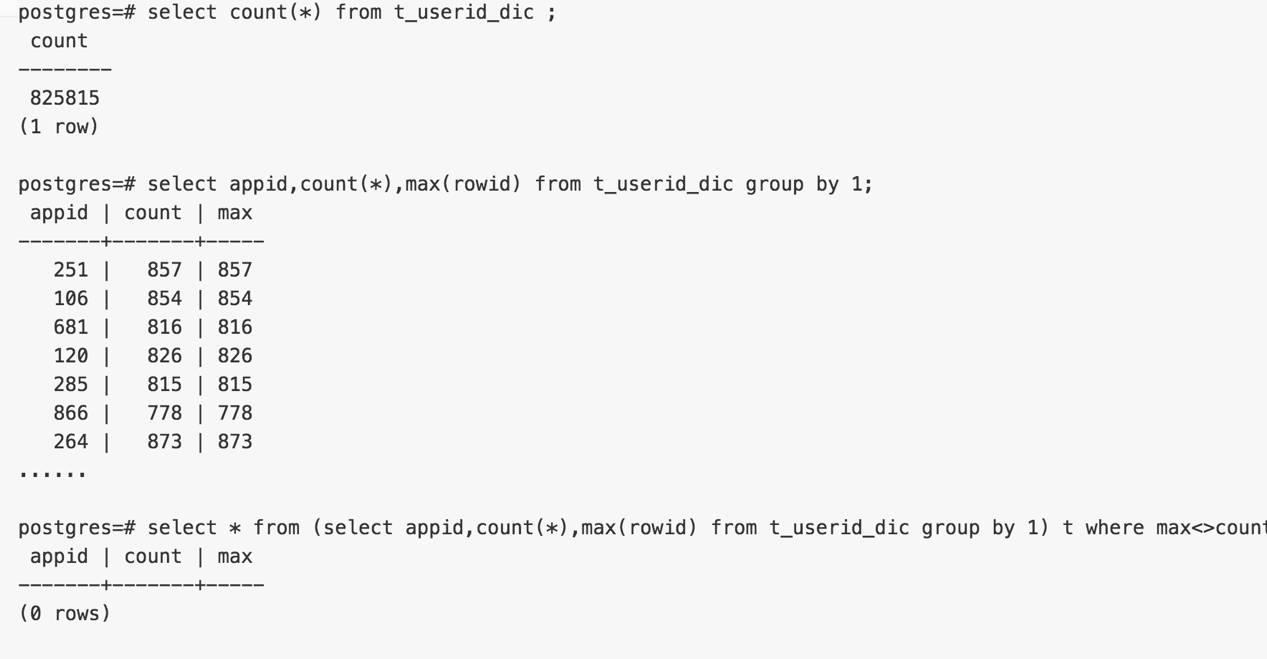
插入速度,无缝需求,完全符合要求。
生成1亿测试用户,APPID=1, 用于后面的测试

2. 实时变更表
为了提高写入性能,数据将实时的写入这张表,后台增量的将这个表的数据合并到TAG表。
drop table IF EXISTS t_user_tags;
create table IF NOT EXISTS t_user_tags(id serial8 primary key, appid int, userid int8, tag int, ins boolean, dic boolean default false);
create index idx_t_user_tags_id on t_user_tags(id) where dic is false;
-- ins = true表示新增tag, =false 表示删除tag。
-- dic = true表示该记录设计的USERID已经合并到用户字典表
-- 这张表的设计有优化余地,例如最好切换使用,以清理数据,比如每天一张,保存31天。
生成1.5千万测试数据(APPID=1 , USERID 总量20亿,随机产生, 新增tagid 范围1-10000, 删除tagid 范围1-1000)
insert into t_user_tags (appid,userid,tag,ins) select 1, 2000000000*random(),10000*random(),true from generate_series(1,10000000);
insert into t_user_tags (appid,userid,tag,ins) select 1, 2000000000*random(),5000*random(),false from generate_series(1,5000000);
3. tag + userids bitmap 表,这个是最关键的表,查询量很大,从t_user_tags增量合并进这个表。

生成1万个TAG的测试数据,每个TAG包含1亿个用户的BIT。方便下面的测试

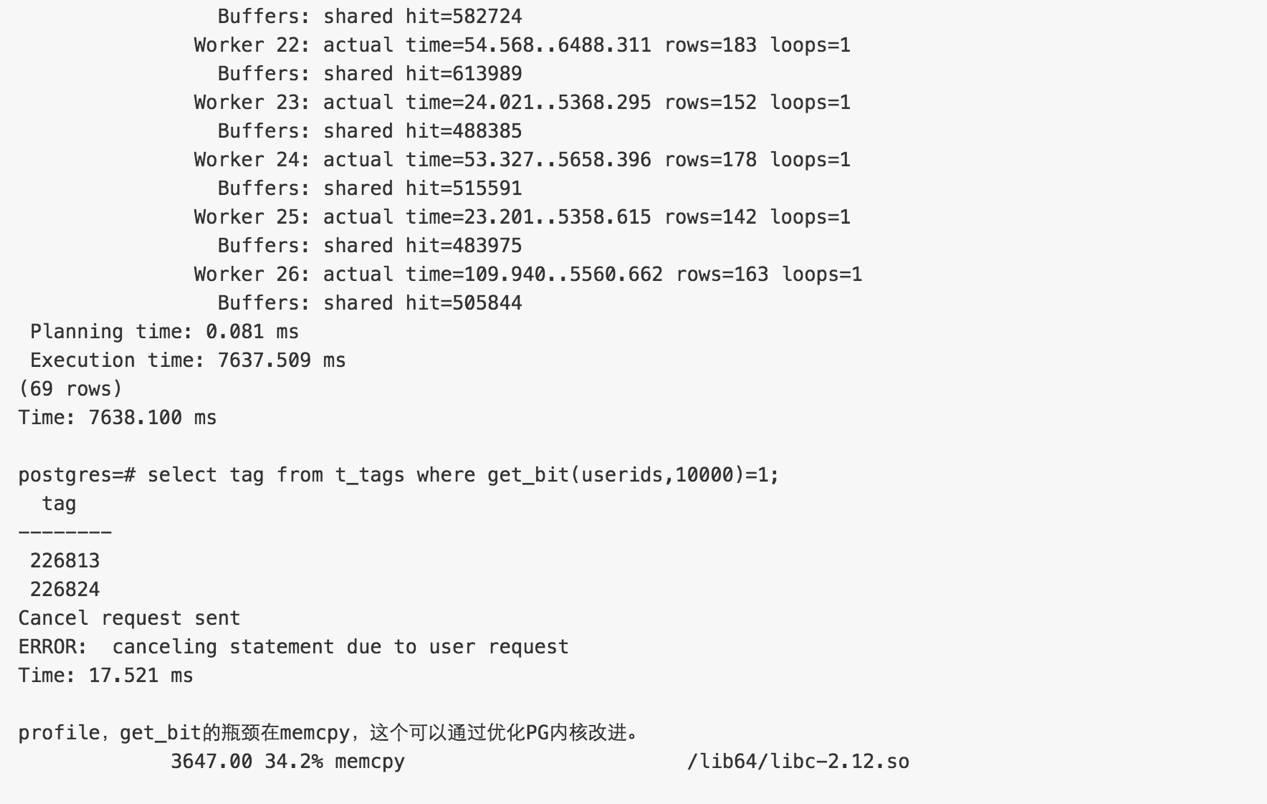
测试TAG组合查询性能
这个指标显示了用户勾选一些TAG组合后,圈定并返回用户群体的性能。
测试方法很简单: 包含所有,不包含,包含任意。
1. 包含以下TAG的用户ID
userids (bitand) userids
结果为bit位为1的用户
测试SQL如下
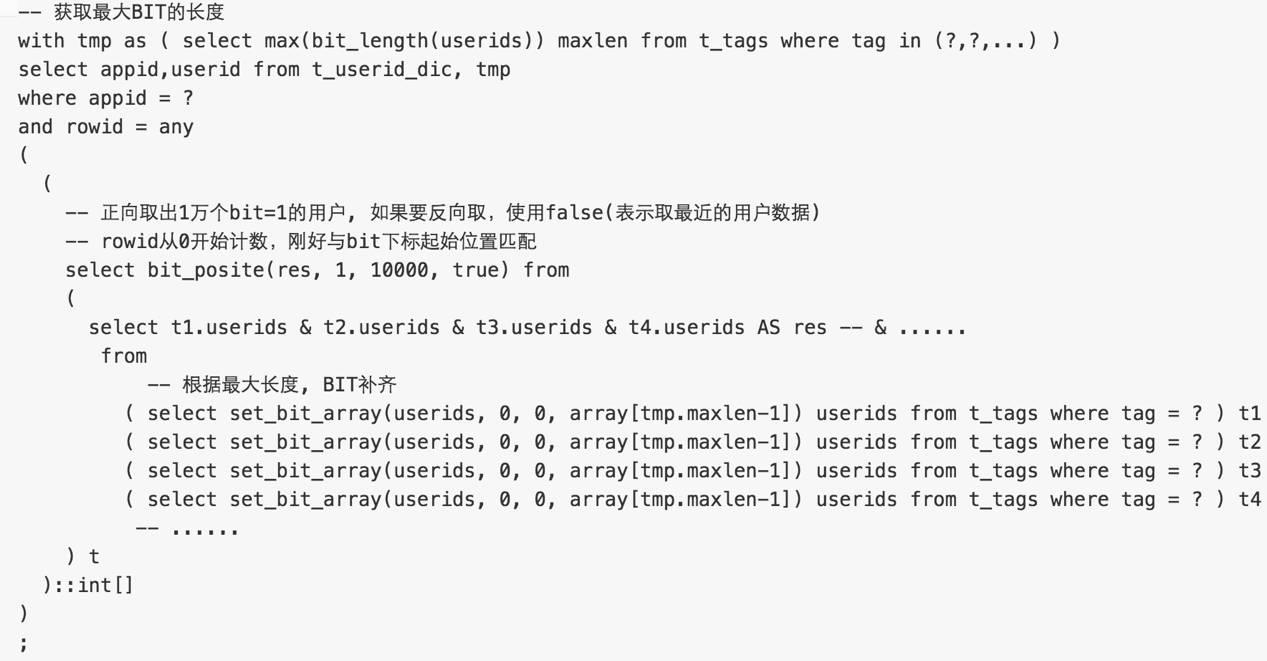
性能数据
with tmp as ( select max(bit_length(userids)) maxlen from t_tags where tag in (226833, 226830, 226836, 226834) )
select appid,userid from t_userid_dic, tmp
where appid = 1
and rowid = any
(
(
select bit_posite(res, 1, 10000, true) from
(
select t1.userids & t2.userids & t3.userids & t4.userids as res
from
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226833 ) t1 ,
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226830 ) t2 ,
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226836 ) t3 ,
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226834 ) t4
) t
)::int[]
)
;
2. 不包含以下TAG的用户
userids (bitor) userids
结果为bit位为0的用户
测试SQL如下

性能数据
with tmp as ( select max(bit_length(userids)) maxlen from t_tags where tag in (226833, 226830, 226836, 226834) )
select appid,userid from t_userid_dic, tmp
where appid = 1
and rowid = any
(
(
select bit_posite(res, 0, 10000, true) from
(
select t1.userids | t2.userids | t3.userids | t4.userids as res
from
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226833 ) t1 ,
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226830 ) t2 ,
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226836 ) t3 ,
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226834 ) t4
) t
)::int[]
)
;
3. 包含以下任意TAG
userids (bitor) userids
结果为bit位为1的用户
测试SQL如下
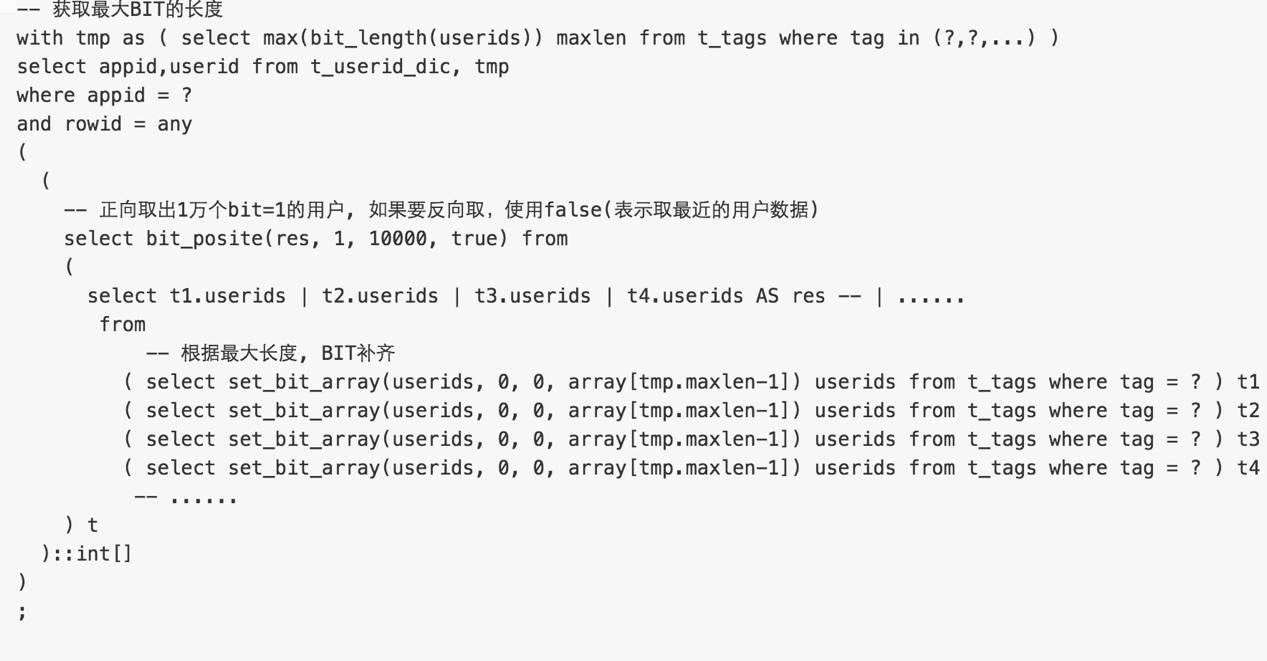
性能数据
with tmp as ( select max(bit_length(userids)) maxlen from t_tags where tag in (226833, 226830, 226836, 226834) )
select appid,userid from t_userid_dic, tmp
where appid = 1
and rowid = any
(
(
select bit_posite(res, 1, 10000, true) from
(
select t1.userids | t2.userids | t3.userids | t4.userids as res
from
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226833 ) t1 ,
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226830 ) t2 ,
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226836 ) t3 ,
( select set_bit_array(userids, 0, 0, array[tmp.maxlen-1]) userids from t_tags,tmp where tag = 226834 ) t4
) t
)::int[]
)
;
高级功能
1. 结合bit_posite,可以实现正向取若干用户,反向取若干用户(例如有100万个结果,本次推广只要1万个用户,而且要最近新增的1万个用户,则反向取1万个用户即可)。
2. 结合get_bit则可以实现截取某一段BIT,再取得结果,很好用哦。
测试新增数据的性能
新增数据即往t_user_tags表插入数据的性能。
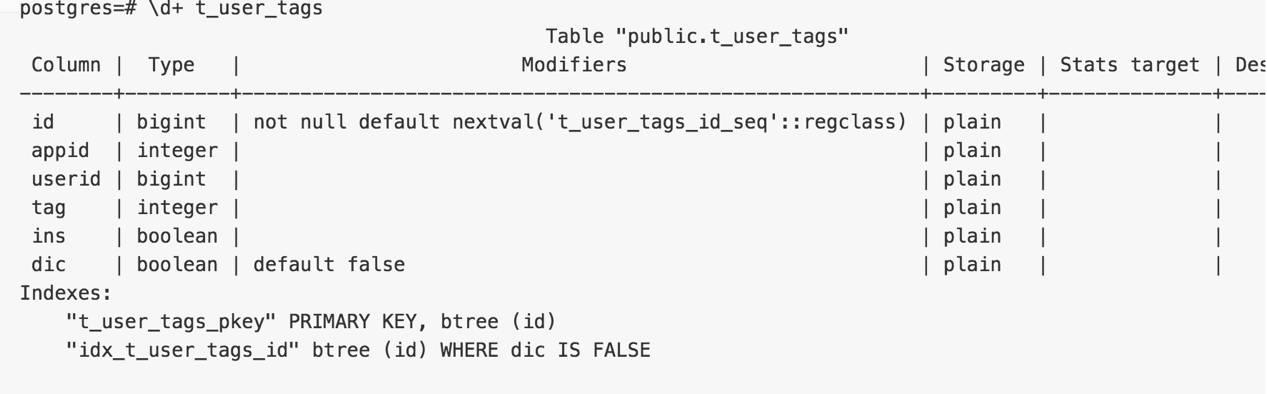
测试如下

性能数据(单步操作的QPS约12.2万,包括新增,删除TAG)
更新的动作需要拆成两个部分,新增和删除,不要合并到一条记录中。
测试数据的合并性能
数据的合并包括3个部分,
1. 更新用户字典表t_userid_dic,
2. 批量获取并删除t_user_tags的记录,
3. 合并标签数据到t_tags。
以上三个动作应该在一个事务中完成。
考虑到t_tags表userids字段1亿BIT约12.5MB,更新单条记录耗时会比较长,所以建议采用并行的模式,每个TAG都可以并行。
更新字典封装为函数如下
从t_user_tags表取出数据并更新数据字典,被取出的数据标记为允许合并。
此操作没有必要并行,串行即可,搞个后台进程无限循环。

-- 插入本次需要处理的临时数据到数组
-- f_uniq失败也不会报错,这里需要修改一下f_uniq仅对UK冲突不处理,其他错误还是需要处理的,否则t_user_tags改了,但是USER可能没有进入字典。
with tmp as (update t_user_tags t set dic=true where id>=min_id and id<=min_id+v_rows returning *)
select count(*) into f_uniq_res from (select f_uniq(appid,userid) from (select appid,userid from tmp group by 1,2) t) t;
end;
$$ language plpgsql;
由于批量操作,可能申请大量的ad lock, 所以需要增加max_locks_per_transaction, 数据库参数调整
max_locks_per_transaction=40960
验证
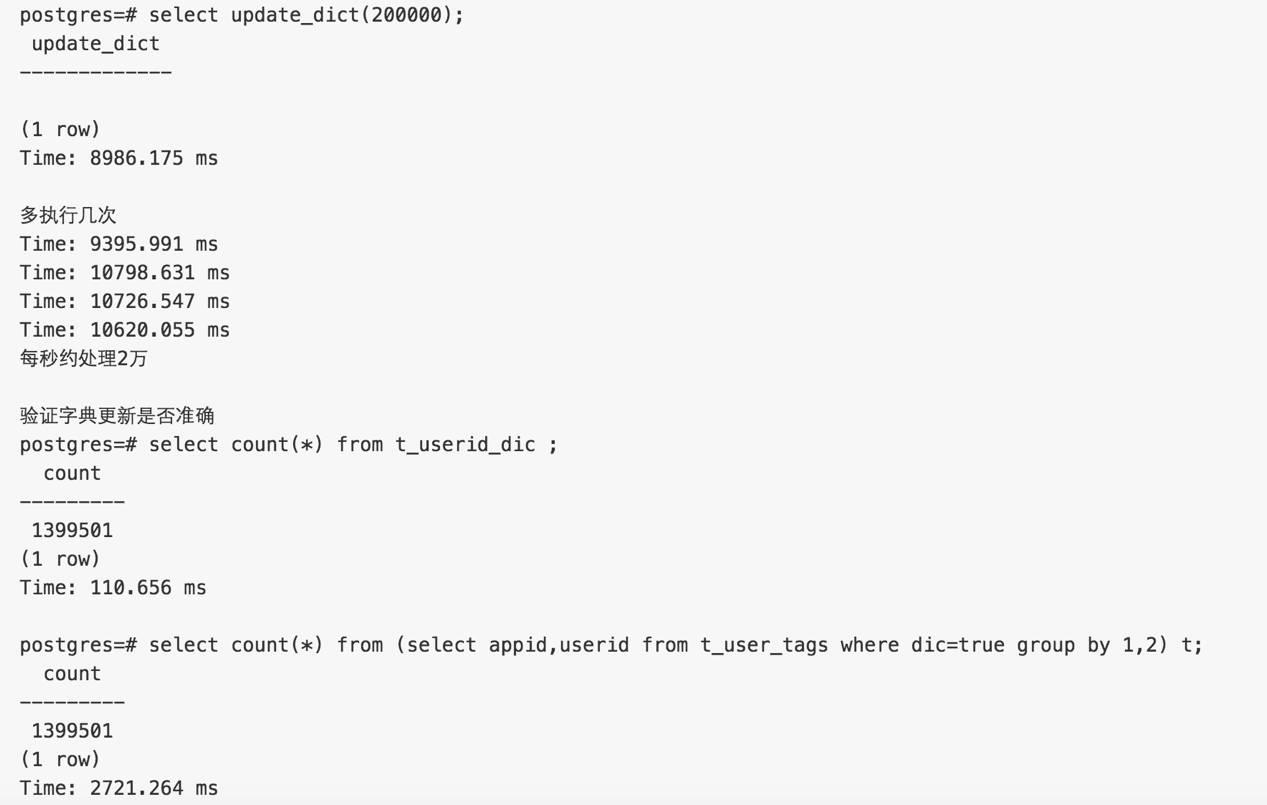
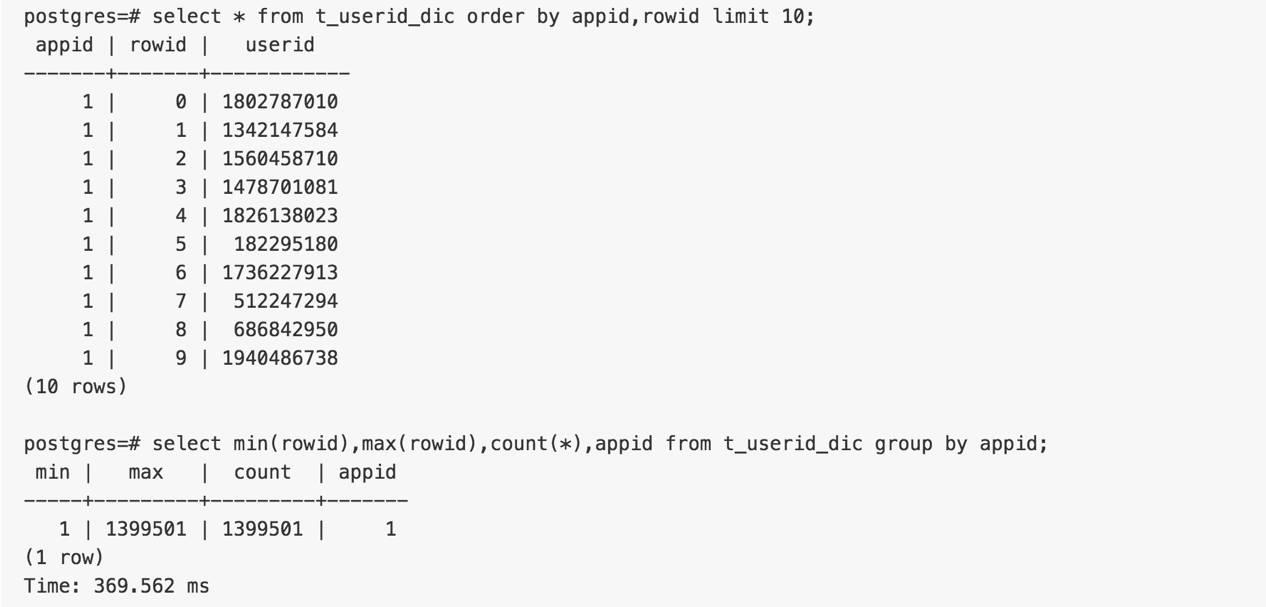
虽然没有必要并行,但是这个函数需要保护其并行的安全性,所以接下来验证并行安全性

验证并行结果的安全性,结果可靠
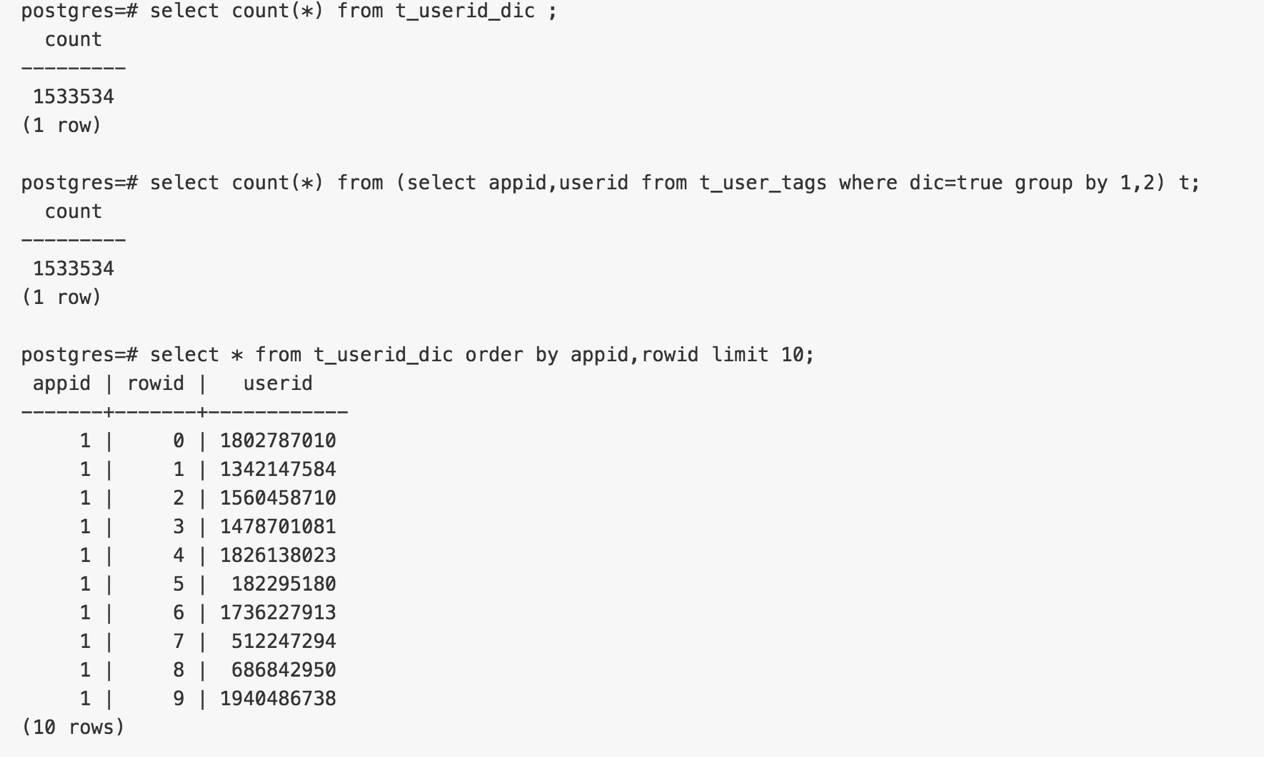

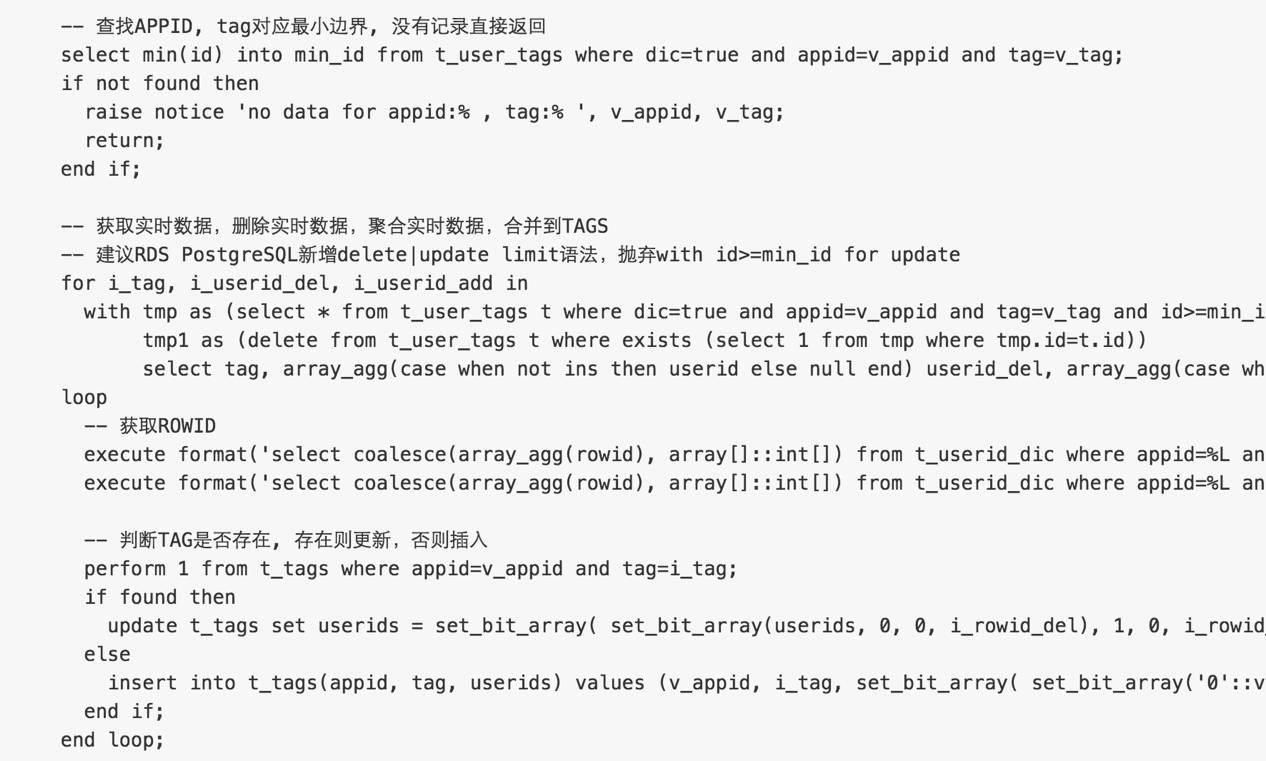
数据合并封装为函数如下
前面已经处理了字典的更新,接下来就可以将t_user_tags.dic=true的数据,合并到t_tags中。
考虑更新T_TAGS可能较慢,尽量提高并行度,不同TAG并行。
-- 不要对同一个APPID并行使用APPID与APPID+tag的模式.




速度测试

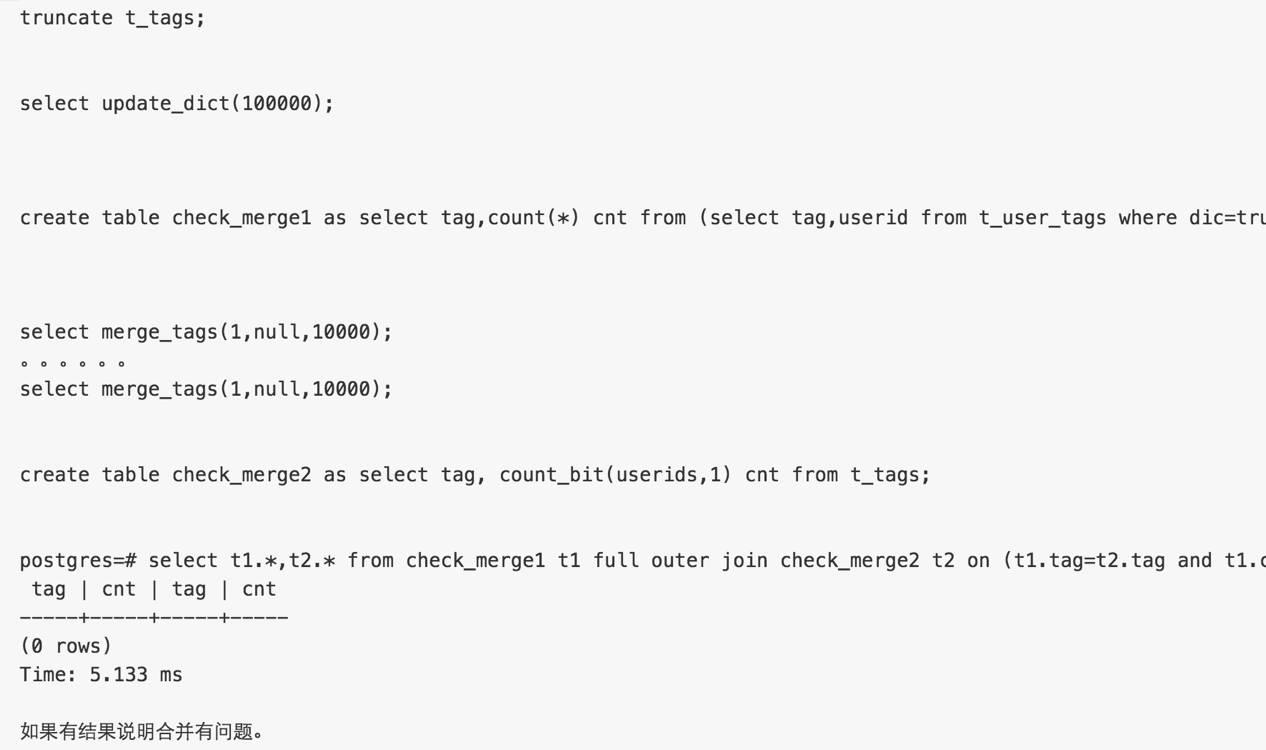
验证方法,merge的结果数据与被merge的数据一致即可。
符合要求
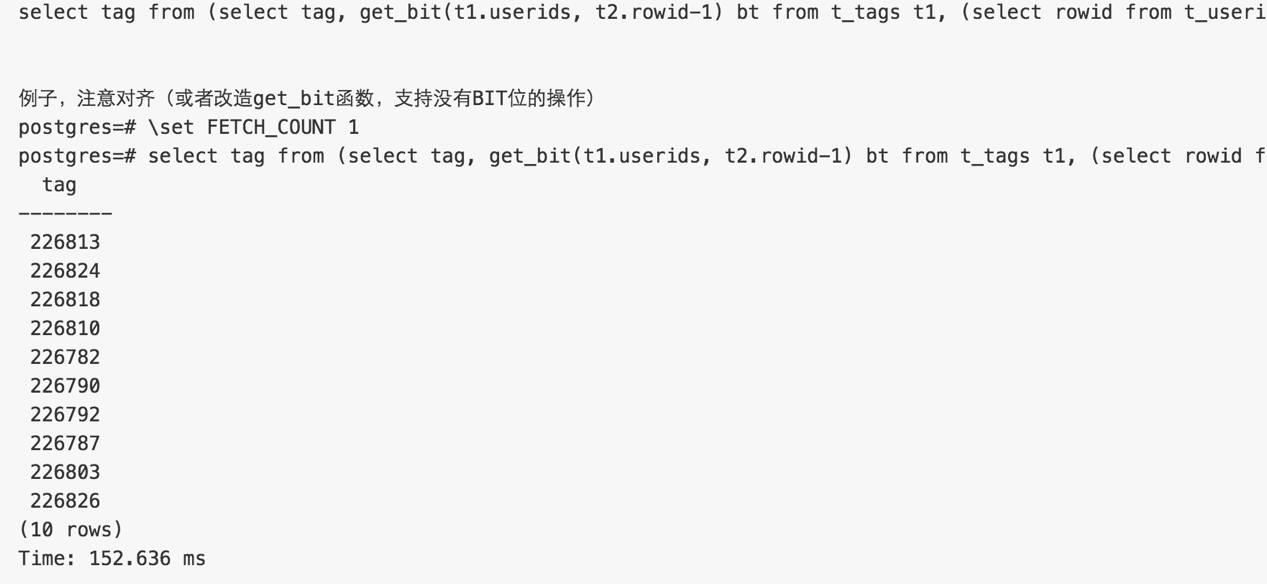
查询单个用户有哪些TAG
找到userid对应的rowid, 根据userids rowid位置的bit,判断是否有该tag
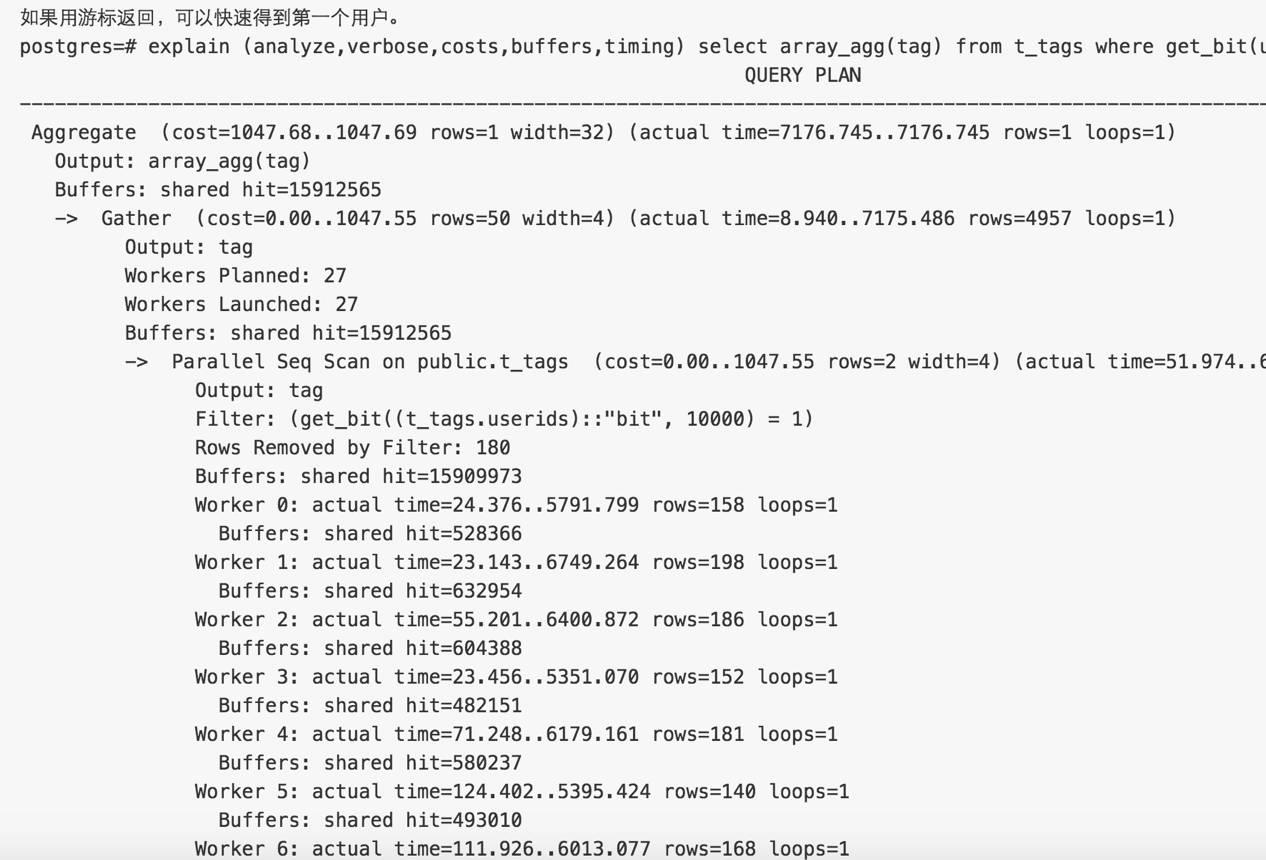
查询单个用户有哪些TAG是一个比较重的操作,如果碰到有很多TAG并且用户数非常庞大时,建议使用并行。

分片
大APPID,按USER号段切分
APPID+号段分片
如果一个APPID 1万个TAG,1亿用户,只占用120GB。
通常是出现倾斜时才需要重分布。
PostgreSQL使用postgres_fdw可以原生支持数据分片。
参考之前写的文档
同一个APPID的一批TAG必须在一个节点
扩展阅读
机器学习,生成TAG,本文不涉及。
参考 MADlib、R ,聚类分析 PostgreSQL都可以非常好的支持。
Postgres大象会2016官方报名通道:
http://www.huodongxing.com/event/8352217821400
扫码报名
以上是关于基于 阿里云 RDS PostgreSQL 打造实时用户画像推荐系统的主要内容,如果未能解决你的问题,请参考以下文章