入门教程SequoiaDB+PostgreSQL数据实时检索最佳实践
Posted 巨杉数据库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了入门教程SequoiaDB+PostgreSQL数据实时检索最佳实践相关的知识,希望对你有一定的参考价值。
【入门教程】SequoiaDB+Postgresql数据实时检索最佳实践
1. 背景
SequoiaDB数据实时检索的能力体现在索引和数据切分的使用上,创建合适的索引能够快速查询到具备某一特征数据的能力;合理的切分方式能够提高数据查询性能。比如按时间,按地区去统计一些数据时,可以采用主子表的切分方式,将一个海量数据的集合切分成均匀的多个数据块,某些类型的查询性能就可以得到极大提升。
SequoiaDB作为分布式数据库,从设计之初就已经支持SQL访问。目前,SequoiaDB自研的SQL访问组件SequoiaSQL作为企业版的功能之一已经提供给上百家企业用户使用,并且已经实现分布式架构下的SQL 2003支持。
由于大部分开发人员及客户倾向于使用标准的SQL语句作为数据库操作的标准接口,SequoiaDB实现了与PostgreSQL的对接,使得开发者可以使用SQL语句访问SequoiaDB数据库,完成SequoiaDB数据库的增,删,查,改操作。对于SequoiaDB社区版用户,我们可以通过SequoiaDB对接PostgreSQL 实现社区版的分布式SQL访问。这一应用方式基本也可以满足大部分的社区版需求。
2. SequoiaDB与PostgreSQL对接结构
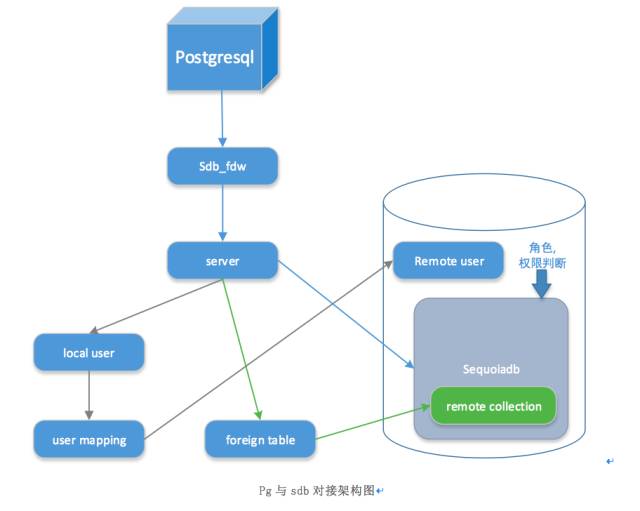
Pg对接sdb步骤:
先创建PostgreSQL本地数据库,
在本地数据库中加载SequoiaDB连接驱动sdb_fdw
基于sdb_fdw,创建server,配置与SequoiaDB的连接参数,包括认证信息,server代表需要访问的数据库
定义好server后,创建外部表,映射到目标server中的可访问对象,即SequoiaDB的集合。
2.1 部署环境
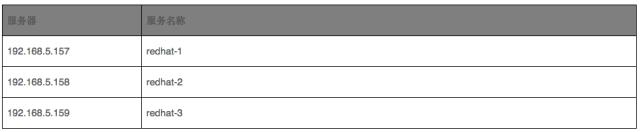
1) 服务器分布
2) 软件配置
操作系统:RedHat7.2
JDK版本:1.7.0_80 64位
SequoiaDB版本:2.6
Postgresql版本:9.3.4
2.2 安装PGSQL
Step1、安装readline库,zlib库
yum install readline-devel
yum install zlib-devel
Step 2、下载pg压缩包,后解压,编译postgreSql
$ tar -zxvf postgresql-9.3.4.tar.gz
$ cd postgresql-9.3.4/
$ ./configure && make && make install
Step 3、切换用户,拷贝PgSql文件
$ su - sdbadmin
$ cp -rf /usr/local/pgsql ~/
Step4 在sdbadmin用户环境变量中添加Pgsql的lib库
vi ~/.bash_profile
export LD_LIBRARY_PATH=/usr/local/pgsql/lib:${LD_LIBRARY_PATH}
Step 5、创建pgSql的数据目录,并初始化数据目录(只能初始化一次)
$ mkdir pg_data
$ bin/initdb -D pg_data/
2.3 安装sequoiadb-postgreSql插件
Step 1、创建pgSql的lib目录
$ PGLIBDIR=$(bin/pg_config --libdir)
$ mkdir -p ${PGLIBDIR}
Step 2、在share目录下创建pgSql的extension目录
$ PGSHAREDIR=$(bin/pg_config --sharedir)
$ mkdir -p ${PGSHAREDIR}/extension
Step 3、从 SequoiaDB 的安装包中,拷贝 PostgreSQL 的扩展文件
从 SequoiaDB 安装后的 PostgreSQL目录中拷贝 sdb_fdw.so 文件到 PostgreSQL 的 lib 目录,并添加软链接。
$ cp -f /opt/sequoiadb/postgresql/sdb_fdw.so_2.2_23000 ${PGLIBDIR}
$ cd ${PGLIBDIR}
$ ln -s sdb_fdw.so_2.2_23000 sdb_fdw.so
将 sdb_fdw.control 和 sdb_fdw--1.0.sql 脚本拷贝到 extension 目录中:
$ cp -f /opt/sequoiadb/postgresql/sdb_fdw.control ${PGSHAREDIR}/extension/ ;
$ cp -f /opt/sequoiadb/postgresql/sdb_fdw--1.0.sql ${PGSHAREDIR}/extension/ ;
Step 4、修改PostgreSQL的日志配置,日志中增加打印时间信息、连接信息等
$ vi pg_data/postgresql.conf
#打印连接信息
log_connections = on
#打印断连信息
log_disconnections = on
log_line_prefix = '%m %p %r'
#出现错误是,断开当前连接
exit_on_error = on
Step5、修改PostgreSQL的连接配置
为了使非本机客户端也能够连接PostgreSQL,我们需要修改pg的连接配置
$ sed -i "s/#listen_addresses = 'localhost'/listen_addresses = '0.0.0.0'/g" pg_data/postgresql.conf
2) 修改信任的机器列表,信任所有机器
sed -i "s/host all all 127.0.0.1\/32 trust/host all all 0.0.0.0\/0 trust/g" /sdbdata/data03/pg_data/pg_hba.conf
Step 6、启动pg进程
bin/postgres -D pg_data/ >> pg.log 2>&1 &
Step 7、创建 PostgreSQL 的 database
$ bin/createdb -p 5432 foo
Step 8、进入 PostgreSQL shell 环境
$ bin/psql foo
2.4 PostgreSQL与SequoiaDB对接流程:
Step 1、加载SequoiaDB连接驱动
foo=# create extension sdb_fdw;
Step 2、配置与sequoiadb连接参数
foo=# create server sdb_server foreign data wrapper sdb_fdw options(address '127.0.0.1', service '11810');
注:用户可以指定多个协调节点,避免一个协调节点出现异常后,postgresql无法使用。如果配置了数据库密码验证,需要配置user与password字段。
3 .PostgreSQL操作SequoiaDB数据库实践
配置好PostgreSQL与SequoiaDB对接后,为使pgsql能够对sdb的集合进行数据操作,还需要建立外表用于映射sdb集合数据。
3.1 搭建表(集合)结构
1) SequoiaDB中dept_test集合结构
{
"_id": {
"$oid": "5950ca9e2f1f2ba90a000000"
},
"dept_id": 1,
"dept_name": "developer",
"dept_location": "beijin"
}
emp_test集合结构
{
"_id": {
"$oid": "5950caaee50314ac0a000000"
},
"emp_id": 1,
"name": "Holmes",
"job": "salesman",
"salary": 8000,
"bonus": 3143,
"hire_date": "2016-03-23",
"manager": 10,
"dept_test_id": 5
}
为提高检索速度,将这两个集合分别根据dept_id和emp_id进行hash切分。因为对数据进行分区能够改善查询性能,平衡IO压力,对分区键为条件的检索可以仅搜索自己关心的分区,提供检索速度。
2) 关联SequoiaDB的集合,建立两个外关联表dept_test和emp_test
create foreign table dept_test(dept_id integer,dept_name varchar,dept_location varchar) server sdb_server options(collectionspace 'foo',collection 'dept_test');
create foreign table emp_test(emp_id integer,name varchar,job varchar,salary integer,bonus integer,hire_date varchar,manager integer,dept_test_id integer) server sdb_server options(collectionspace 'foo',collection 'emp_test');
注:集合空间与集合必须已经存在于SequoiaDB,否则查询出错
PostgreSQL是对字母大小写敏感的的,如果SequoiaDB中的集合空间,集合和字段名是大写的,需要在名字上加上双引号。
3.2 数据实时检索实践
对于多表关联,真正需要查询的数据基本都是可以确定的情形下,sdb可以将这些表数据进行清洗打平操作,将需要查询的数据及查询条件整合到一张或几张查询表(集合)中,在查询字段上建立多个索引保证查询性能。
1) PostgreSQL解析过程
PostgreSQL在执行方面它负责接收SQL查询请求,解析SQL生成逻辑计划,之后对逻辑计划进行优化,并将优化后的逻辑计划转换成执行计划,交由sdb执行,语法方面它既支持基本的操作(select、project、join、group by、filter、order by、limit等),也支持关联子查询和非关联子查询,和支持各种outer-join。

2) 检索实践
a. 简单查询
SELECT * FROM emp_test WHERE salary BETWEEN 5000 AND 10000;
在salary字段上建立索引,可以加快条件的判断速度
b. 关联查询
SELECT name,dept_name,dept_location FROM emp_test JOIN dept_test ON emp_test.dept_test_id=dept_test.dept_id;
在外键dept_test_id上创建索引,可以加快表连接的速度
c. 聚合查询
SELECT dept_test_id,AVG(salary)
FROM emp_test
GROUP BY dept_test_id
HAVING AVG(salary)>8000 order by AVG(salary);
可以在需要排序的列上创建索引,这样查询可以利用索引的排序,加快排序查询时间;但这条SQL语句不能使用索引,因为索引字段被函数调用,不能走索引。
4 结论
SequoiaDB为社区用户提供PostgreSQL对接接口,能够使用PostgreSQL的SQL引擎对SequoiaDB进行查询操作,使得对非关系型数据库不熟悉的业务编程人员也能够通过其熟练的SQL语句对SequoiaDB进行插入查询工作。
SequoiaDB+PostgreSQL可以说为社区用户提供了一个更为简单的技术选择,使得SequoiaDB除了原生API之外,为社区开发者提供了SQL的接口。
当然,如果有更为复杂的需求或者更为庞大的业务数据需要管理,我们还是会推荐购买企业版的SequoiaDB,包括其中的SequoiaSQL分布式SQL引擎。

起飞
以上是关于入门教程SequoiaDB+PostgreSQL数据实时检索最佳实践的主要内容,如果未能解决你的问题,请参考以下文章