技术教程SequoiaDB对接Kafka
Posted 巨杉数据库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术教程SequoiaDB对接Kafka相关的知识,希望对你有一定的参考价值。
1
背景
当前互联网、金融、政府等行业,活动流数据几乎无处不在。对这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。活动流数据的这种处理方式对实时性要求越来越高的场景已经不在适用并且这种处理方式也增加了整个系统的复杂性,为了解决这种问题,分布式开源消息系统Kakfa已被多家不同类型的公司 作为多种类型的数据管道和消息系统使用。
Kafka是一种分布式的,基于发布/订阅的消息系统。提供消息持久化能力,支持消息分区,分布式消费,同时保证每个分区内的消息顺序传输,支持在线水平扩展、高吞吐率,同时支持离线数据处理和实时数据处理。
巨杉数据库SequoiaDB支持海量分布式数据存储,并且支持垂直分区和水平分区,利用这些特性可以将Kafka中的消息存储到SequoiaDB中方便业务系统后续数据分析、数据应用。本文主要讲解巨杉数据库SequoiaDB如何消费Kafka中的消息以及将消息存储到SequoiaDB中。
2
产品介绍
巨杉数据库SequoiaDB是一款分布式非关系型文档数据库,可以被用来存取海量非关系型的数据,其底层主要基于分布式,高可用,高性能与动态数据类型设计,它兼顾了关系型数据库中众多的优秀设计:如索引、动态查询和更新等,同时以文档记录为基础更好地处理了动态灵活的数据类型。PostgreSQL支持标准SQL,巨杉SequoiaDB SSQL套件通过扩展 PostgreSQL功能可以使用标准SQL 语句访问 SequoiaDB 数据库,完成对SequoiaDB 数据库的各种操作。将Kafka中的消息存储到SequoiaDB后,可利用巨杉SequoiaDB SSQL对这些消息数据进行在线实时的数据分析和数据应用。
3
环境搭建
3.1、软件配置
操作系统:windows 7
eclipse:4.5.2
SequoiaDB:1.12.5或以上版本
本项目主要实现从Kafka中消费数据并写入到SequoiaDB中来展示Kafka对接SequoiaDB的整个过程。
创建项目工程如下图:
3.2、kafka启动及topic创建
在kafka启动前启动zookeeper,Kafka启动,执行脚本如下:
./kafka-server-start.sh ../config/server.properties &
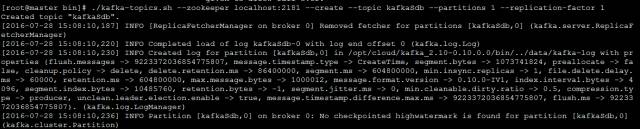
Kafka创建topic,执行脚本如下:
./kafka-topics.sh --zookeeper localhost:2181 --create --topic kafkaSdb --partitions 1 --replication-factor 1
执行结果如下图:
验证Kafka主题,执行脚本如下:
./kafka-topics.sh --zookeeper localhost:2181 –list
执行结果如下图:

4
代码演示
4.1、框架搭建代码展示
Kafka分布式系统分为生产者和消费者,生产者主要产生消息数据供消费者消费,消费者主要消费存储在Kafka中的消息数据。本项目主要演示向SequoiaDB中写入Kafka中的消息,故消息的生产只提供演示代码。生产者和消费者各种参数分别放在各自的配置文件中。
Ø 生产端配置文件如下:
kafka-producer.properties
bootstrap.servers=192.168.1.35:9092
retries=0
linger.ms=1
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
partitioner.class=com.sequoiadb.kafka.DefaultPartitioner
Ø 消费端配置文件如下:
kafka-consumer.properties
bootstrap.servers=192.168.1.35:9092
enable.auto.commit=true
auto.commit.interval.ms=60000
enable.auto.commit=false
auto.offset.reset=earliest
session.timeout.ms=30000
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
Ø Kafka主题、SequoiaDB集合、消息分区配置文件如下:
config.json
[{
topicName:'kafkaSdb',
sdbCLName:'kafkaSdb',
partitionNum:1,
topicGroupName:'kafkaSdb-consumer-group',
pollTimeout:5000
}]
4.2、业务实现代码展示
4.2.1、配置代码展示
本项目将Kafka的配置放在配置文件中如Kafka的主题,主题的分区数,SequoiaDB集合并用java对象进行封装,利用工具类进行获取。
配置信息java实体类如下:
package com.sequoiadb.kafka.bean;
public class KafkaConsumerConfig {
private String topicName;
private String sdbCLName;
private int partitionNum = 1;
private String topicGroupName;
private long pollTimeout = Long.MAX_VALUE;
public String getTopicName() {
return topicName;
}
public void setTopicName(String topicName) {
this.topicName = topicName;
}
public String getSdbCLName() {
return sdbCLName;
}
public void setSdbCLName(String sdbCLName) {
this.sdbCLName = sdbCLName;
}
public int getPartitionNum() {
return partitionNum;
}
public void setPartitionNum(int partitionNum) {
this.partitionNum = partitionNum;
}
public String getTopicGroupName() {
return topicGroupName;
}
public void setTopicGroupName(String topicGroupName) {
this.topicGroupName = topicGroupName;
}
public long getPollTimeout() {
return pollTimeout;
}
public void setPollTimeout(long pollTimeout) {
this.pollTimeout = pollTimeout;
}
public String toString(){
return "[topicName="+this.topicName+",sdbCLName="+this.sdbCLName+",partitionNum="+this.partitionNum",topicGroupName="+this.topicGroupName+",pollTimeout="+this.pollTimeout+"]";
}
}
配置信息获取工具类如下:
package com.sequoiadb.utils;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
public class PropertiesUtils {
private static Properties prop = null;
static{
InputStream in = PropertiesUtils.class.getClassLoader().getResourceAsStream("config.properties");
prop = new Properties();
try {
prop.load(in);
} catch (IOException e) {
e.printStackTrace();
}
}
public static String getProperties(String key){
return (String)prop.get(key);
}
public static void main(String[] argc){
System.out.println(PropertiesUtils.getProperties("scm.url"));
}
}
4.2.2、业务逻辑代码演示
生产者业务逻辑代码展示:
package com.sequoiadb.kafka;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
import org.apache.commons.io.IOUtils;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.sequoiadb.utils.Configuration;
public class PartitionTest {
private static Logger log = LoggerFactory.getLogger(PartitionTest.class);
private static String location = "kafka-producer.properties";// 配置文件位置
public static void main(String[] args) {
Properties props = new Properties();
String json = null;
try {
props.load(Thread.currentThread().getContextClassLoader().getResourceAsStream(location));
InputStream in = Configuration.class.getClassLoader().getResourceAsStream("oracle.json");
json = IOUtils.toString(in);
} catch (IOException e) {
e.printStackTrace();
}
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 1000; i++) {
ProducerRecord<String, String> record = new ProducerRecord<String, String>("oracle", json);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null) {
log.error("the producer has a error:" + e.getMessage());
}
}
});
}
try {
Thread.sleep(1000);
producer.close();
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
}
消费者业务逻辑采用一线程一主题的方式进行消息的消费,主程序入口代码如下:
package com.sequoiadb.kafka;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.sequoiadb.kafka.bean.KafkaConsumerConfig;
import com.sequoiadb.utils.Configuration;
import com.sequoiadb.utils.Constants;
public class KafkaSdb {
private static Logger log = LoggerFactory.getLogger(KafkaSdb.class);
private static ExecutorService executor;
public static void main(String[] args) {
// 获取kafka主题配置
List<KafkaConsumerConfig> topicSdbList = Configuration.getConfiguration();
if (topicSdbList != null && topicSdbList.size() > 0) {
executor = Executors.newFixedThreadPool(topicSdbList.size());
final List<ConsumerThread> consumerList = new ArrayList<ConsumerThread>();
for (int i = 0; i < topicSdbList.size(); i++) {
KafkaConsumerConfig consumerConfig = topicSdbList.get(i);
ConsumerThread consumer = new ConsumerThread(consumerConfig);
consumerList.add(consumer);
executor.submit(consumer);
}
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
for (ConsumerThread consumer : consumerList) {
consumer.shutdown();
}
executor.shutdown();
try {
executor.awaitTermination(5000, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
} else {
log.error("主题为空,请确认主题配置是否正确!");
}
}
}
线程类负责具体的消息的消费,并且将消息数据写入到SequoiaDB中,具体代码如下:
package com.sequoiadb.kafka;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.errors.WakeupException;
import org.bson.BSONObject;
import org.bson.BasicBSONObject;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.sequoiadb.base.CollectionSpace;
import com.sequoiadb.base.DBCollection;
import com.sequoiadb.base.Sequoiadb;
import com.sequoiadb.exception.BaseException;
import com.sequoiadb.kafka.bean.KafkaConsumerConfig;
import com.sequoiadb.utils.ConnectionPool;
import com.sequoiadb.utils.Constants;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
public class ConsumerThread implements Runnable {
private static Logger log = LoggerFactory.getLogger(ConsumerThread.class);
private String location = "kafka-consumer.properties";// 配置文件位置
private Sequoiadb sdb = null;
private CollectionSpace cs = null;
private DBCollection cl = null;
private KafkaConsumer<String, String> consumer = null;
// private String topicName = null;
// private String clName = null;
// private String topicGroupName = null;
// private long pollTimeout = 1000;
private KafkaConsumerConfig consumerConfig;
public ConsumerThread(KafkaConsumerConfig consumerConfig) {
if (null == sdb) {
sdb = ConnectionPool.getInstance().getConnection();
}
if (sdb.isCollectionSpaceExist(Constants.CS_NAME)) {
cs = sdb.getCollectionSpace(Constants.CS_NAME);
} else {
throw new BaseException("集合空间" + Constants.CS_NAME + "不存在!");
}
if (null == cs) {
throw new BaseException("集合空间不能为null!");
} else {
this.consumerConfig = consumerConfig;
this.cl = cs.getCollection(this.consumerConfig.getSdbCLName());
}
Properties props = new Properties();
try {
props.load(Thread.currentThread().getContextClassLoader().getResourceAsStream(location));
} catch (IOException e) {
e.printStackTrace();
}
props.put("group.id", this.consumerConfig.getTopicGroupName());
consumer = new KafkaConsumer<>(props);
}
@Override
public void run() {
log.info("主题为" + this.consumerConfig.getTopicName() + "的消费者线程启动!");
try {
// 订阅topic
consumer.subscribe(Arrays.asList(this.consumerConfig.getTopicName()));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(this.consumerConfig.getPollTimeout());
// consumer.seekToBeginning(Arrays.asList(new
// TopicPartition(this.topicName, 0)));
// consumer.seek(new TopicPartition(this.topicName, 0), 0);
List<BSONObject> list = new ArrayList<BSONObject>();
for (ConsumerRecord<String, String> record : records) {
String value = record.value();
JSONObject valueJson = JSONObject.fromObject(value);
if (valueJson.containsKey("data")) {
JSONArray dataJsonArray = valueJson.getJSONArray("data");
for (int i = 0; i < dataJsonArray.size(); i++) {
BSONObject httpBson = new BasicBSONObject();
JSONObject dataJson = dataJsonArray.getJSONObject(i);
Iterator iter = dataJson.keys();
while (iter.hasNext()) {
String key = (String) iter.next();
String bsonValue = dataJson.getString(key);
httpBson.put(key, bsonValue);
}
list.add(httpBson);
// clHttp.insert(httpBson);
}
} else {
log.error("消息中不存在data节点!");
}
}
if (list != null && list.size() > 0) {
try {
this.cl.bulkInsert(list, DBCollection.FLG_INSERT_CONTONDUP);
log.info("主题为"+this.consumerConfig.getTopicName()+"的消息插入SDB成功,插入记录数为:"+list.size());
} catch (BaseException e) {
e.printStackTrace();
}
}
consumer.commitSync();
}
} catch (WakeupException e) {
} finally {
consumer.close();
}
}
public void shutdown(){
consumer.wakeup();
}
}
5
总结
从上述对接过程中,Kafka中的消息写入SequoiaDB难点是Kafka中主题分区的配置以及多线程如何消费各主题分区中的消息,并且处理消息消费失败的情况。
相关阅读

起飞
以上是关于技术教程SequoiaDB对接Kafka的主要内容,如果未能解决你的问题,请参考以下文章