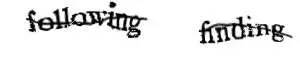关于验证码的那些事儿——12306验证码背后的图灵测试算法博弈
Posted 新奇博物馆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于验证码的那些事儿——12306验证码背后的图灵测试算法博弈相关的知识,希望对你有一定的参考价值。
12306验证码无疑是近期的热点。而当说起12306验证码时,我们在谈些什么?一起来看看搜索引擎大数据… “逆天”、“遭调侃”、“总是错误”…
之前新闻称,12306验证码的一次成功输入率仅为8%(什么?你一次就输对了?别闹,大糖知道你们都是土豪根本不买火车票好吗…)
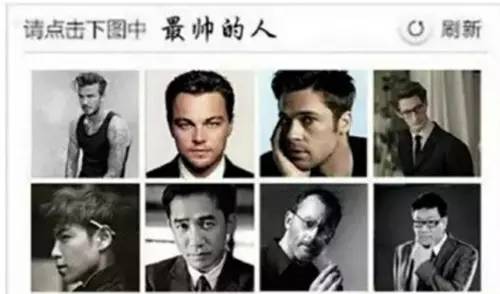
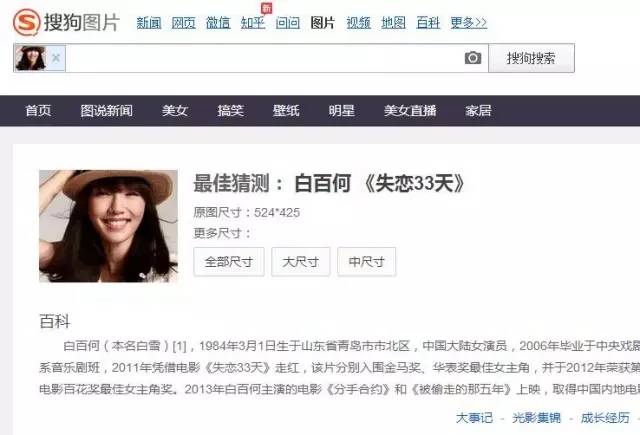
当然,大家对12306验证码的关注可能早就转移到了恶搞和吐槽本身上,相信你见过网友们制作的考验眼力的这张
吐槽之余,可能有些人在好奇12306验证码为何设计得如此之难?未来的验证码又会是什么样子?
其实12306验证码身后是互联网算法的博弈,而这种算法的博弈,从某种程度上反映并促进了人工智能和图灵测试的发展。(听起来是不是很炫酷?)
验证码,可一定是传统意义上的“码”哦。我们先来看看验证码的英文CAPTCHA,这并不是一个原生词,而是Completely Automated Public Turing Test to Tell Computers and Humans Apart的简称。也就是说
从类别上来说,验证码是图灵测试的一种,从目的上来说,验证码是为了区分用户是人还是计算机。
可想而知,为了达到这一目的,验证码设计的主要指导方针就是:人可以轻松识别,而计算机则无法识别。
验证码CAPTCHA基础技术的出现比CAPTCHA这个名字的出现要早几年。
早在1997年,康柏公司(对,就是Compaq,第一家做笔记本电脑的公司)的Mark D. Lillibridge, Martin Abadi, Krishna Bharat和Andrei Z. Broder四位程序员,为了防止脚本机器人自动向他们的搜索引擎提交网址、阻碍网站正常运行,发明了一种选择性限制计算机系统访问的办法(Method for selectively restricting access to computer systems)。
这种方法采用的是字符型图片,同时加入防止OCR(光学字符识别)自动识别的干扰因素。生成的步骤是:自动选择几个字符 → 将字符进行串联 → 将字符进行外观扭曲处理 → 添加干扰背景。最终看到的就是这种:
公司往往注重实践,而研究学者则注重理论。验证码CAPTCHA这一理论定义的提出是2003年,又有4位歪果仁
这四位大师正式提出了验证码的概念。(为何总共出现了8个外国人的名字,只有这2人标出中文名?之后再写一篇文章给大家介绍一下这两位大师吧!)
众所周知,图灵测试是由人类考验计算机,而由于验证码CAPTCHA是由计算机来考人类,人们也称其为一种反向图灵测试。
验证码发明后的近20年间,作为一种在商业中被应用的图灵测试,在全球程序员中隐蔽开展着“出题技术”和“解题技术”的博弈,而这种博弈也促进了算法的不断提升。
最初的验证码,为了防止OCR光学字符识别技术而对字符变形且加入了干扰背景。然而,算法工程师们不断升级OCR技术,即便加入了干扰因素,依然可以对图片中的字符进行识别。
Step1,利用算法将图片中的每一个像素点的值提取出来,并判断出背景部分和字符部分,筛选出字符部分。
Step2,将分离出来的字符与“训练库”里的字符进行匹配,最终识别出答案。
当然这种验证码的难度在不断增加,一方面表现在字符的范围增加,由26个英文字母扩展到字母+数字,或者字母+数字+特殊符号,以及由英文变为中文汉字;另一方面表现在干扰的增加。但不管难度如何增加,应对技术也只是更加智能和准确,并无本质的变化。
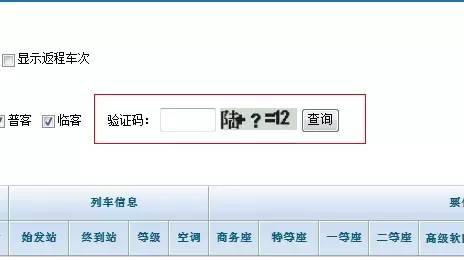
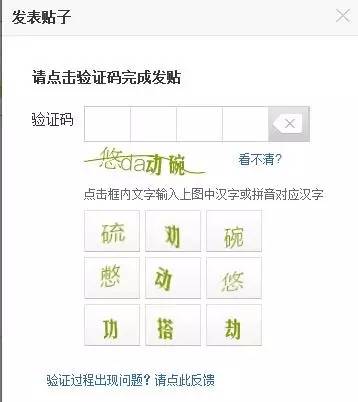
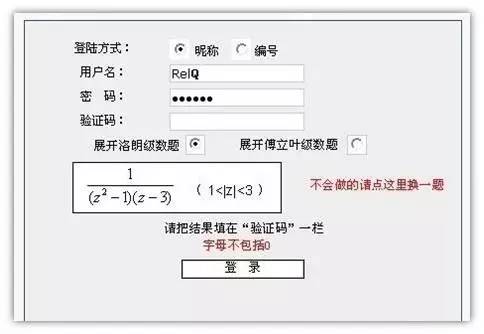
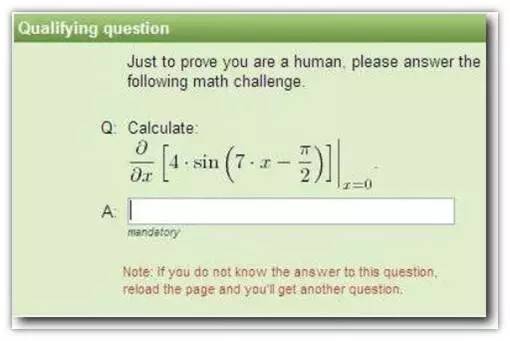
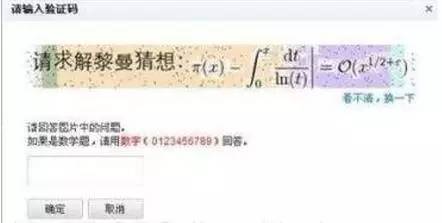
面对越来越精准的OCR技术,验证码出题者们开始扩展思路,不再执着于增加图片识别难度,而是加入了能体现“思考”的内容,力求阻止算法对验证码的自动识别。当然,验证码设置也往往需要考虑到用户特征。一般来说,现在计算式和选择文字的较为常用:
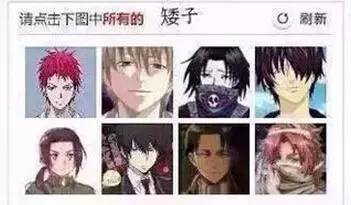
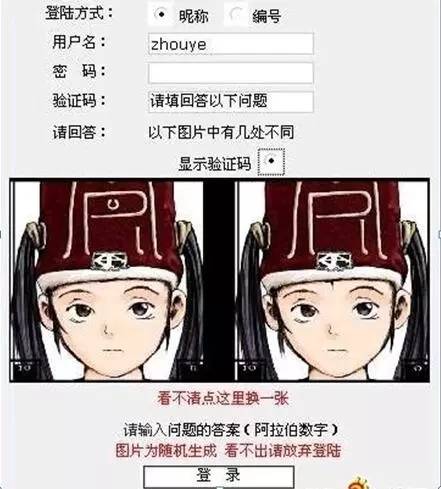
当然也还有各类学术网站针对用户特点设置了这种验证码(明明不是在区分机器和人,而是在区别人与人了好吗?!):
这种类型的验证码往往只存在在特定网站,题库内题目数量较少,极易被穷举后进行人工标识,且是否能正确得出答案往往也不考验机器的算法能力,因此算法工程师们并未就此领域进行探讨。
而12306验证码,则属于图片匹配的新形式,不仅要识别图片中的问题,还需要在8张备选图片中选出正确答案。即:需要理解文字,并且需要通过思考,将文字与实际形象相匹配,识别每一张图的内容是什么。这已经属于需要图像抽象思维能力的层级了,更为难的是,12306验证码已经设计到581个种类,几万张图片,且每张图片像素较低,人眼都很难识别。这也是网上诸多吐槽的原因。
然而,验证码CAPTCHA级别设置到这么高的水平,是否就真的无法用技术突破了呢?跟某技术大牛了解到,其实对于在图像识别方面有深度积累的公司来讲,也并非特别难的事情。而且搜狗搜索已经公布了技术解决方案,据说可以在0.3秒内完成识别,且正确率可达99%。
对候选图片进行识别分类。将候选图片代入图片数据库进行识别,将每张图片所属类别进行标识。
从字数的多少就可以看出…12306验证码的难度主要在Step2…
Step2对候选图片的识别分类,图片识别是对技术要求极高的领域,不仅需要利用到在图片领域深度学习和大数据分析处理能力,同时还需要有大量的数据积累。相信搜狗搜索能推出这样的解决方案,也是基于每天千万量级的图像搜索数据积累,因为深度学习是需要通过模拟人认知图片的过程,多层次地模拟和学习后,才能保障图像识别的准确率。
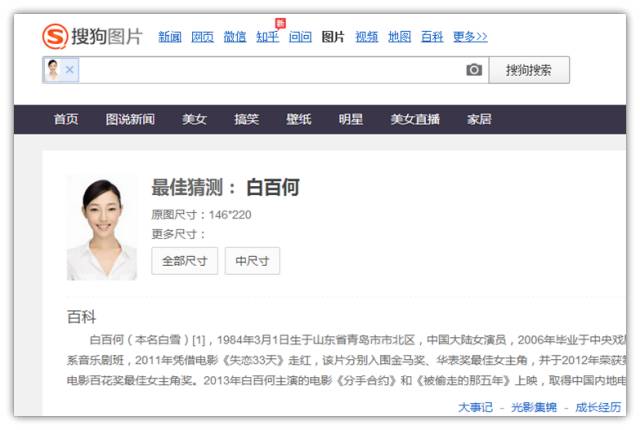
那么,如果真的像白百何那种难度的验证码是否可以正确识别出来呢?大糖亲测了一下,上传了一张白百何图片后,还真的被识别出来了,这就意味着其实网友恶搞的那张图片,搜狗的12306验证码解决方案是可以正确答出来的。
所以大家看,机器深度学习到一定程度的话,其实的确是可以表现出“类人”或者“超越人”的表现。当然这也就对验证码提出了更高的要求。
言归正传,回到验证码领域,其实12306验证码的确是在算法领域对机器提出更高要求的一种验证码类型。从某种程度上来讲,其实反映出了商业领域对更高难技术算法的应用实践。当商业中得以应用,技术往往就可以得到更快速的发展,随着12306验证码被关注,相信让大家注意到了原来技术已经发展到可以读懂图片回答如此高难问题的程度。当然,验证码本意是让人轻松解答而机器无法解答的,而12306验证码明显对人的正确识别造成了障碍,实为违背了验证码的本意。
同时,这种对算法要求更高的验证码和验证码识别技术的博弈,互为技术提高的动力和成果验证方,不断根据博弈方的发展进行可行的自我改进和提升。所以,12306验证码虽然被吐槽“逆天”,其实在技术领域是一件引领算法工程师们挑战图灵测试的极酷的事情呢!
-------------------我是彩蛋的分隔线-----------------
泥萌一定还想看更多好玩儿的验证码对不对?
比如这种:
以上是关于关于验证码的那些事儿——12306验证码背后的图灵测试算法博弈的主要内容,如果未能解决你的问题,请参考以下文章
手把手教你玩转12306验证码的秘密!
15分钟实现数字验证码自动识别,基于OpenCV+Keras
01 | 图形验证码的识别
12306 售票网站新版验证码识别对抗
使用深度学习模型识别12306图片验证码
WPF做12306验证码点击效果