01 | 图形验证码的识别
Posted AI悦创
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了01 | 图形验证码的识别相关的知识,希望对你有一定的参考价值。
目前,许多网站采取各种各样的措施来反爬虫,其中一个措施就是使用验证码。随着技术的发展,验证码的花样越来越多。验证码最初几个数字组合的简单的图形验证码,后来加入了英文字母和混淆曲线。有的网站还能看到中文验证码,这使得识别语法困难。
后来 12306 验证码的出现使得行为验证码开始发展起来,用过 12306 的用户肯定多少为它的验证码头疼过。为什么这么说呢?
因为,我们需要识别文字,然后点击与文字描述相符合的图片,验证码完全正确,验证才能通过。现在这种具有交互式的验证码越来越多,如 极验滑动验证码 此类验证码需要 滑动拼合滑块才可以验证(我不过我个人更喜欢叫它拼图验证码)。点触验证码则需要你完全点击正确结果才可以完成验证,另外还有其它的:滑动九宫格验证码、计算验证码等等。
以下为 12306 验证码示例图:
一:图形验证码
我们首先识别最简单的一种验证码,即图形验证码。这种验证码最早出现,现在也很常见,一般由 4 位字母或者数字组成。
例如,中国知网的注册页面有类似的验证码。
链接为:中国知网的注册页面
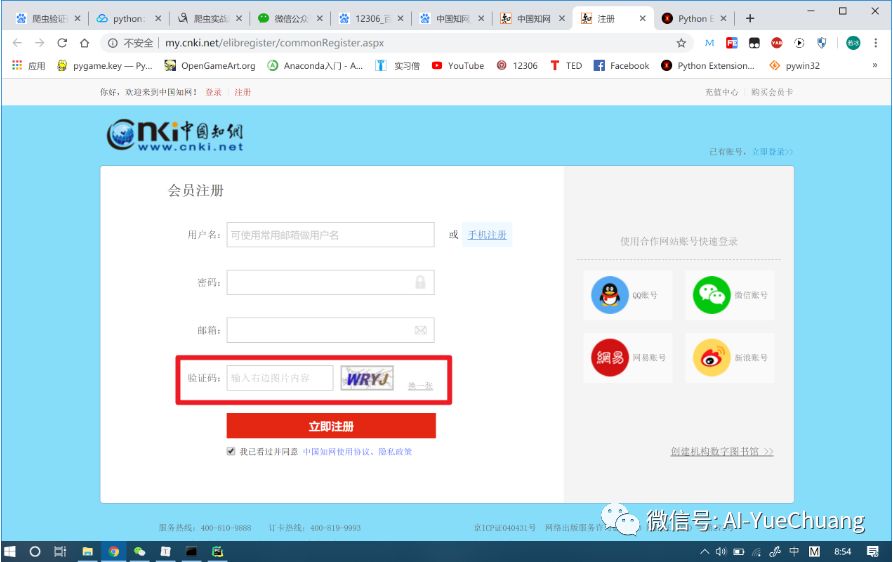
我们可以发现,这个注册页面的表单最后一项就是图形验证码,我必须完全正确的输入图片中的字符才能完成注册。
1. 本节目标
以知网为例,我将教你们使用 OCR 技术识别图形验证码的两种方法。
2. 准备工作
识别图形验证码需要的第三方库:tesserocr 和 Pillow 和一个依赖以及语言包。
下面中 1 步安装时间较久,可以先暂时跳过不安装,直接 pip 命令安装。如果出现的问题和下面提到的问题,可以直接使用下面提到的解决方法操作,实在不行。再安装这个 OCR 软件。
# 常规操作,按以下顺序逐步操作# 下面中 1 步安装时间较久,可以先暂时跳过不安装,直接 pip 命令安装。如果出现的问题和下面提到的问题,可以直接使用下面提到的解决方法操作,实在不行。再安装这个 OCR 软件。# 1. 去以下网址下载对应的 exe 安装包(注意:如果你去其他网址下载:不带 dev 的名称,dev 为开发版本,不稳定。不带 dev 为稳定版本,我们下载稳定版本即可)# 安装时,切记勾选 Additional language data(download) 的选项来支持 OCR 识别语言包。详细请看 PDF 安装文档。https://github.com/UB-Mannheim/tesseract/wiki# 1步为了照顾小白,小编为此还编写的 tesseract-ocr 的安装 PDF 文档。后台回复:ORCPDF# 2. 接下来安装库pip install tesserocr# 如果报错,去网上下载适配的 whl 文件,下载网址:https://github.com/simonflueckiger/tesserocr-windows_build/releases# 安装Pillowpip install Pillow
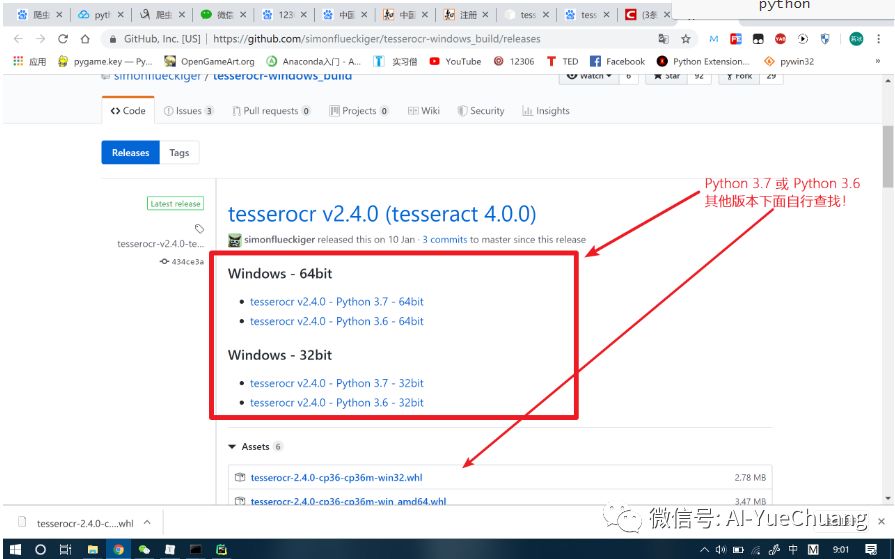
# 下载完,去 whl 所在的文件夹打开 cmd# 然后输入:pip install whl的文件名
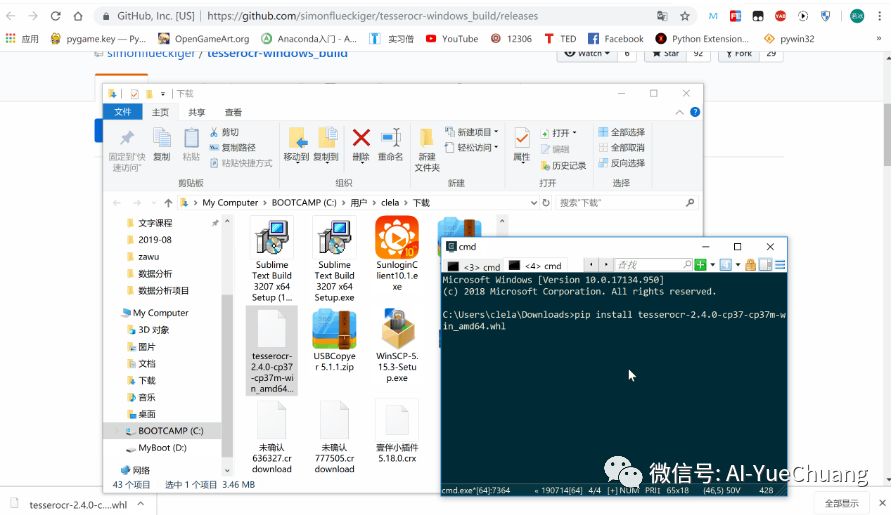
安装成功:
温馨提醒:如果你遇到如下报错则是你的代码 whl 文件与 Python 不匹配。
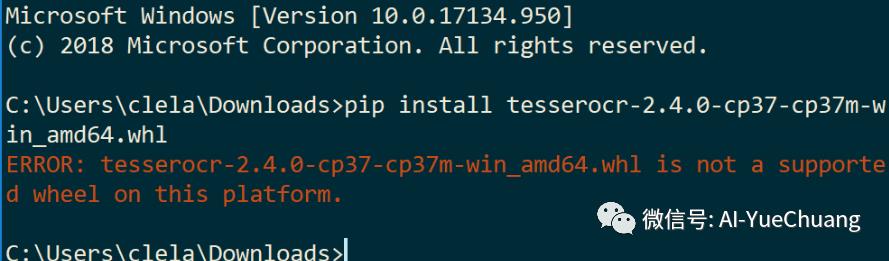
如果出现此问题:
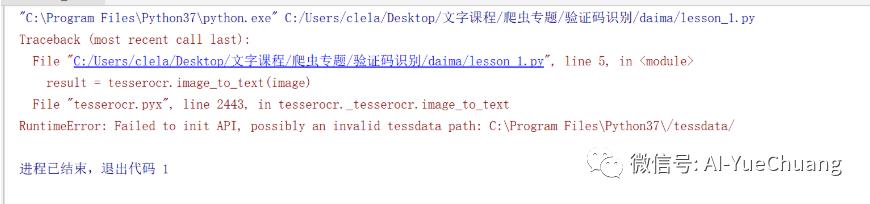
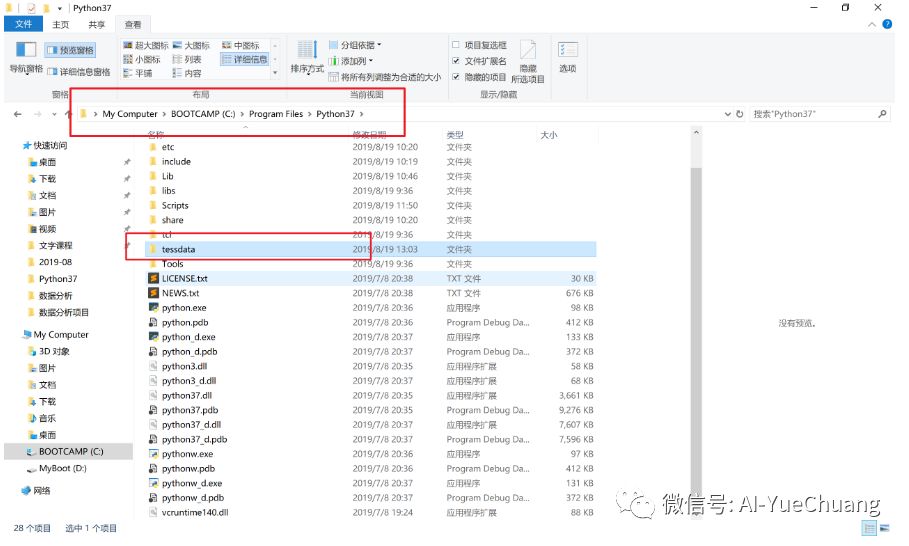
操作方法:解压压缩包 >>> 把解压的文件放入上图报错的相应 Python37 (注意:我的python是3.7,请按你自己的报错操作即可)的目录下即可 >>> 操作完毕
3. 获取验证码
为了便于实验,我们先将验证码的图片保存的本地。链接为:中国知网的注册页面
下载下来的验证码:

4. 识别测试
接下来新建一个项目,把下载的 验证码 放到你的项目根目录下,就是跟你的代码同一个文件夹 ,使用 resserocr 库来识别该验证码,代码如下:
import tesserocr # 导入库from PIL import Imageimage = Image.open('CheckCode.jpg') # 读取图片result = tesserocr.image_to_text(image)# 在这里我们新建了一个 Image 对象,# 调用 tesserocr 的 image_to_text() 方法。最后传入该图像 image 即可完成识别。print(result) # 输出识别结果。# 输出结果>>>dl0g
实际操作图片:
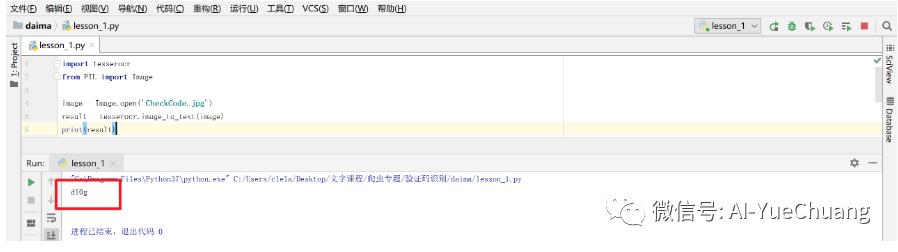
识别成功,轻松破解!这只是最简单的破解。
另外, tesserocr 还有一个更简单的方法,这个方法可以直接将图片文件 转换成 >>> 字符串 代码如下:
import tesserocrprint(tesserocr.file_to_text('CheckCode.jpg'))# 输出结果>>>dl0g
不过,此种方法的识别不如上一种方法好
5. 验证码处理
接下来我们换一一个验证码,验证码如图:(获取验证码图片和上面一样的操作)

重新用如下代码测试:
import tesserocrfrom PIL import Imageimage = Image.open('CheckCode2.jpg')result = tesserocr.image_to_text(image)print(result)# 可以看到,输出如下结果>>>Dqot
实际操作图片:
这次识别的结果和实际的验证码图片有偏差,这是因为验证码内多余线条干扰了图片的识别。
对于这种情况,我们还需要一下额外的处理,如转灰度、二值化 等操作。
我们可以利用 Image 对象的 convert 方法传如 L ,即可将图片转化为灰度图像,代码如下:
from PIL import Imageimage = Image.open('CheckCode2.jpg')image = image.convert('L')image.show()
传入 1 即可将图片进行二值化处理,如下所示:
image = Image.open('CheckCode2.jpg')image = image.convert('1')image.show()
扩展:
我们还可以指定 二值化的阈值 。
上面的方法采用的是默认阈值 127 。不过我们不能直接转化原图。
我们需要先将原图转为 灰度图像 ,然后再指定二值化阈值,代码如下所示:
from PIL import Imageimage = Image.open('CheckCode2.jpg')image = image.convert('L')threshold = 80 # threshold :阈值,然后阈值设置为 :80table = []for i in range(256):if i < threshold:table.append(0)else:table.append(1)image = image.point(table, '1')image.show()
最终代码:
import tesserocrfrom PIL import Image# image = Image.open('CheckCode2.jpg')image = Image.open('Code.jpg')image = image.convert('L')threshold = 80 # threshold :阈值,然后阈值设置为 :80table = []for i in range(256):if i < threshold:table.append(0)else:table.append(1)image = image.point(table, '1')image.show()
6. 结语
本节我们了解到利用 tesserocr 来识别验证码的处理过程。下一篇推文:极验滑动验证码识别 敬请期待。
以上是关于01 | 图形验证码的识别的主要内容,如果未能解决你的问题,请参考以下文章